
We have some cool news to share! Snorkel AI ranked 2nd, behind only GPT-4 Turbo, in our recent submission to AlpacaEval 2.0 LLM leaderboard. This benchmark measures the ability of well-known LLMs such as Gemini, Claude 2, Llama 2, Mixtral, etc. to follow general user instructions. This result was achieved with only an open-source 7B parameter model, thanks to Snorkel AI’s state-of-the-art methods for LLM customization.
Try out the new 7B model that put Snorkel AI in second place on AlpacaEval 2.0! Download, sandbox, or API calls.
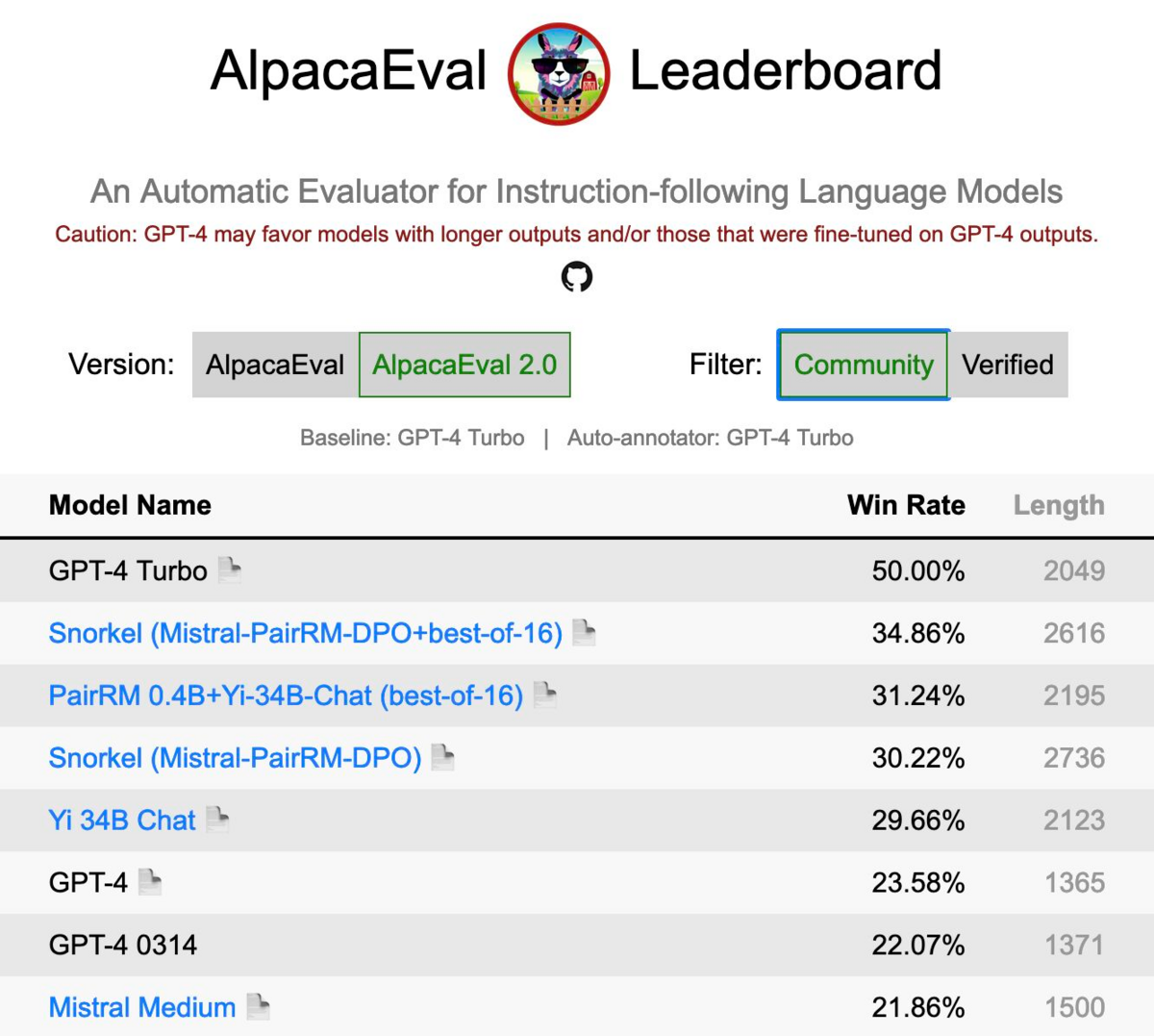
Snorkel AI has long championed the idea that AI teams can get better results faster by replacing highly manual data annotation with programmatic approaches that more efficiently capture and apply subject matter expertise. Snorkel Flow is our data development platform that helps companies like Wayfair and BNY Mellon to fine-tune and align generative models with these programmatic approaches, and today’s result demonstrates the value of a key component of that technology.
Alignment methods such as reinforcement learning from human feedback (RLHF) and direct process optimization (DPO) are typically used as the last step in LLM development to customize a model to match user preferences. That preference data has historically been collected in the form of manual annotations, which are then used to train a reward model for RLHF. DPO has recently emerged as a more stable and performant alternative that utilizes pairs of annotated responses directly. With programmatic alignment, we use a hybrid approach aimed at getting the best of both worlds. First, users rapidly supervise a custom reward model with programmatic labels generated in Snorkel Flow. Second, that reward model is used in conjunction with the LLM being aligned to create high volumes of high quality pairs for use with DPO. The result is a model that is aligned to your preferences, on your data, without a slow and expensive manual labeling process.
AlpacaEval is a general-purpose benchmark, so an off-the-shelf, general-purpose reward model (we used PairRM) sufficed to achieve this strong result without any additional task-specific programmatic data development. The model was fine-tuned and trained using Microsoft Azure A100 GPUs. Ongoing work includes building on this result with publicly shareable demonstrations of the full programmatic alignment pipeline in more business-specific use cases that are not well-represented by general-purpose benchmarks such as AlpacaEval.
To learn more about this research, join us at our LLM Summit, where researcher Hoang Tran will walk through programmatic alignment in more detail. Follow us on social media for future updates from our research team on state-of-the-art methods for LLM customization!
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

