Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Large language model training: how three training phases shape LLMs
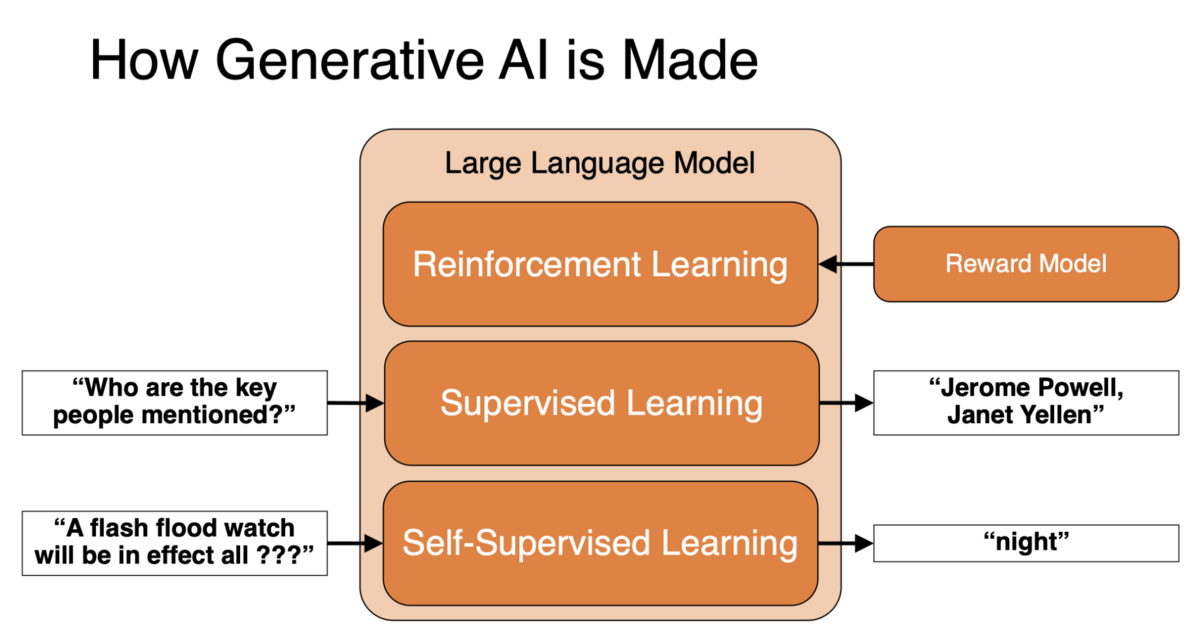
Training large language models is not a singular process. Rather, it’s a multi-layered stack of training processes, each with its unique role and contribution to the model’s performance.
The three main phases are:
- self-supervised learning
- supervised learning
- reinforcement learning.
I recently gave a talk at Snorkel AI’s second Enterprise LLM Summit about the problems that can surface when the data for these three labels is not properly aligned. The talk included a short explainer of the three training phases, which the Snorkel team excerpted as a separate video. I’ve summarized the main points below.
Phase 1: self-supervised learning for language understanding
Self-supervised learning, the first stage of training, is what traditionally comes to mind when we talk about language modeling.
It involves feeding the model with vast amounts of unannotated or raw data and having it predict ‘missing’ pieces of it. The model learns something about language and the domain of the data to generate plausible answers.
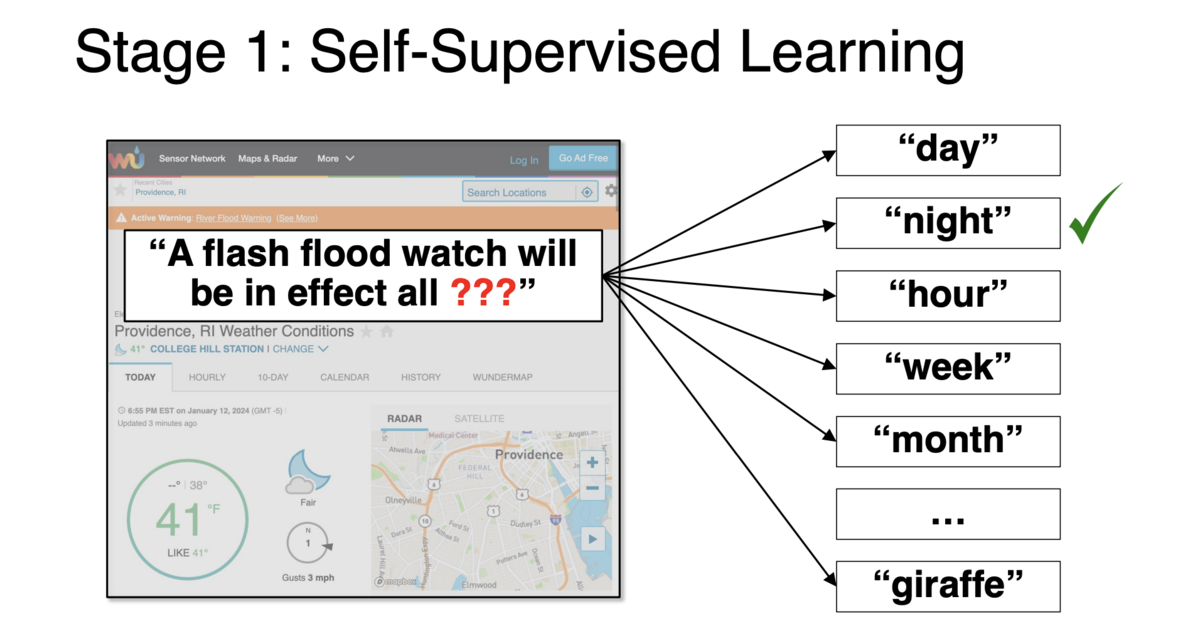
For example, if we feed the model with text from a weather website and ask it to predict the next word, it has to understand something about the language and the weather domain. In the presentation, I gave the example sentence “A flash flood watch will be in effect all _____.”
In an intermediate state, the model ranks a list of predictions, from likely answers (“day”, “night”, “hour”) to less plausible ones (“month”), and even nonsensical ones (“giraffe”) that should be assigned very low probability. This process is called self-supervision (as opposed to unsupervised learning) because there is a specific right answer—the word that actually appeared in the text we collected—which was “night” in my example. Self-supervision is similar to unsupervised learning in that it can use abundant, unannotated data.
Phase 2: Supervised learning for instruction understanding
Supervised learning, also known as instruction tuning, is the second stage in the training process of large language models (LLMs). It’s a crucial phase that builds upon the foundational knowledge acquired during the self-supervised learning stage.
In this phase, the model is explicitly trained to follow instructions. This goes beyond the basic prediction of words and sentences, which is the main focus of the self-supervised learning stage. The model now learns to respond to specific requests, making it far more interactive and useful.
The effectiveness of instruction tuning in enhancing the capabilities of LLMs has been demonstrated in various studies, several of which included Snorkel researchers. One notable outcome was that the model showed improved performance in generalizing to new, unseen tasks. This is a significant achievement as one of the main objectives of machine learning models is to perform well on unseen data.
Due to its proven effectiveness, instruction tuning has become a standard part of LLM training. With the completion of the instruction tuning phase, the model is now explicitly trained to be a helper, doing more than just predicting the next words and sentences. It’s now ready to interact with users, understand their requests, and provide helpful responses.

Phase 3: reinforcement learning to encourage desired behavior
The final stage in the training stack is reinforcement learning. This encourages desired behavior and discourages unwanted outputs. This stage is unique as it does not provide the model with exact outputs to produce, but rather grades the outputs it generates.
The concept of reinforcement learning predates LLMs, but Open AI first proposed it in the context of LLM training shortly after the introduction of instruction tuning. The process starts with a model, already enriched with the ability to follow instructions and predict language patterns. Next, data scientists use human annotations to distinguish between better and worse outputs. These data annotations serve as a guideline for the model, helping it understand which responses are preferred and which are not. The feedback from these annotations is then used to train a reward model.
The reward model is a critical component of this process. It provides rewards at scale, effectively guiding the model towards producing more desirable responses and discouraging less desirable ones. This method is particularly effective in promoting fuzzier concepts like brevity and discouraging harmful language, enhancing the overall quality of the language model’s output.
This approach to reinforcement learning is often referred to as reinforcement learning with human feedback. It emphasizes the importance of human involvement in the training process, ensuring that the model’s learning is aligned with users’ expectations.
Three phases. Three techniques. One improved model.
Training of LLMs is a multi-faceted process that involves self-supervised learning, supervised learning, and reinforcement learning. Each of these stages plays a critical role in making LLMs as capable as they are. The self-supervised learning phase helps the model to understand language and specific domains. Supervised learning enables the model to follow instructions and generalize to new tasks. Finally, reinforcement learning encourages desirable behaviors and discourages harmful language. The combined effect of these stages results in a more effective and capable LLM.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Stephen Bach
Stephen Bach is the Eliot Horowitz Assistant Professor in the Computer Science Department at Brown University. Previously, he was a visiting scholar at Google, and a postdoctoral scholar in the computer science department at Stanford University advised by Christopher Ré.
He received his Ph.D. in computer science from the University of Maryland, where he was advised by Lise Getoor. His research focuses on weakly supervised, zero-shot, and few-shot machine learning. The goal of his work is to create methods and systems that drive down the labor cost of AI. He was a core contributor to the Snorkel framework, which was recognized with a Best of VLDB 2018 award. He also co-led the team that developed the T0 family of large language models. The team was also one of the proposers of instruction tuning, which is the process of fine-tuning language models with supervised training to follow instructions. Instruction tuning is now a standard part of training large language models. Stephen is also an advisor to Snorkel AI.