New Snorkel benchmark leaderboards. See the results.
Snorkel Flow
Curate training data and deliver AI models up to 100x faster with programmatic data development.
Snorkel Flow is an AI data development platform which accelerates enterprise AI development by encoding SME knowledge and applying it at scale, enabling data scientists to quickly curate training data, evaluate models, optimize RAG pipelines, and fine-tune LLMs.
The fast path to production for enterprise AI
Unblock strategic AI initiatives
Break through data roadblocks by creating training data without the need for months of valuable SME time.
Learn more
Deliver accurate models for production
Accelerate model iteration and delivery from months to weeks or mere days with built-in error analysis and evaluation.
Learn more
Adapt models to specialized tasks
Fine-tune small LLMs to build specialized models which perform domain-specific tasks with higher accuracy, lower costs.
Learn more
Trusted by world-leading data science teams
93%
Model accuracy
with just a few labeling functions
“We accurately labeled a few thousand pathology reports with one domain expert in days versus weeks using Snorkel Flow.”
Janet Mak
Deputy CIO and VP of Digital Solutions
85%
accuracy
on a classification model within days
“With Snorkel Flow, we cut labeling time and significantly accelerated model development when delivering NLP solutions.”
Catherine Aiken
CSET Director of Data Science and Research
What is AI data development?
Labeled data is required to train highly accurate AI/ML models for specialized, domain-specific tasks. However, manual data labeling with human annotation is slow, expensive, and often blocks enterprise AI projects on day one.
AI data development eliminates this bottleneck by streamlining collaboration between data scientists and SMEs via a unified platform for capturing domain knowledge and applying it to enterprise data, empowering data scientists to label entire datasets with the click of a button rather than requiring a team of SMEs to hand label each data point.
The Snorkel Flow AI data development platform
Snorkel Flow provides data scientists and subject matter experts with a collaborative platform for capturing domain knowledge, using it to label entire datasets or generate synthetic ones, and to quickly iterate on training data and model development via built-in guided error analysis and model evaluation.
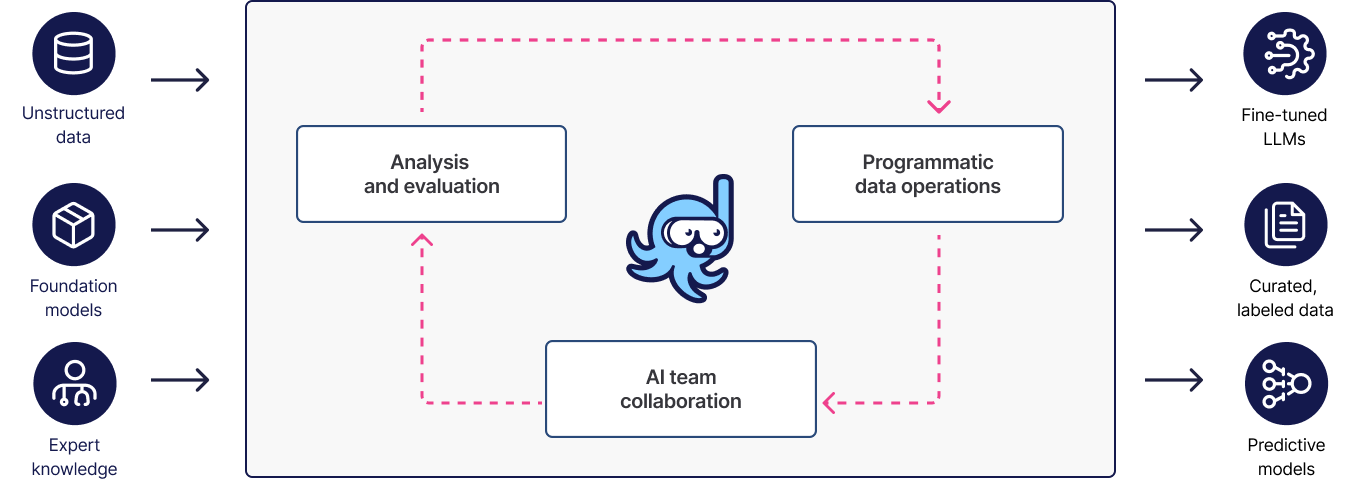
Unblock AI initiatives
AI/ML teams should never be blocked due to missing or low-quality training data. Nor should data scientists, ML engineers, and SMEs be required to spend valuable time on manual data labeling.
Empower data scientists to curate high-quality training data in days rather than months
Take advantage of SME-in-the-loop to improve quality without the need for manual data labeling
Deploy AI/AML models which demonstrate higher accuracy and meet production requirements

Ditch the spreadsheets, and deliver production models faster
Snorkel Flow makes it easy for AI teams to curate training data by capturing SME domain knowledge and using it to automatically generate labels for entire datasets which, after curation, can be used to build classification and information extraction models, evaluate and fine-tune LLMs, and optimize RAG pipelines.
Learn more about data labeling & annotation
Jumpstart data labeling with LLMs
Prompt a foundation model such as OpenAI GPT-4o or Meta Llama 3.1 to generate the initial labels for an entire dataset.
Capture and apply domain knowledge
Capture domain knowledge and enterprise policies with out-of-the-box templates, and use it to improve label accuracy.
Fine-tune models and RAG pipelines
Curate training data and fine-tune embedding models and LLMs as well as extract document metadata for enhanced retrieval.
Evaluate in-domain model accuracy
Use captured domain knowledge and enterprise policies to predict the accuracy of LLM responses, with or without RAG.
Deliver accurate models to production
Improve model quality quickly with guided error analysis. Rapidly correct errors in your data with inputs from your models and SMEs.
Perform LLM evaluations based on SME domain knowledge and feedback to identify where models are failing to generate accurate responses.
Review model-guided error analysis results to improve label accuracy by discovering errors, conflicts, and low confidence levels.
Incorporate SME feedback by taking advantage of collaborative features such as ground truth annotation, tagging, and comments.
Iterate on training data by adding or modifying SME domain knowledge as needed, and monitoring diversity and coverage to avoid over/underfitting.
Adapt models to specialized tasks
Foundation models have become extremely capable, but they lack the domain knowledge needed to perform specialized tasks within the enterprise. However, specialized models can be derived from them, combining their inherent natural language and reasoning capabilities with enterprise data, corporate policies, and industry standards.
Training
Build classification and information extraction models which are trained to produce accurate predictions on enterprise documents.
Fine-tuning
Build specialized LLMs by fine-tuning small models on domain knowledge so they generate more accurate responses than off-the-shelf foundation models.
Distillation
Leverage state-of-the-art foundation models to generate training data which can be used to fine-tune smaller, faster models with equivalent accuracy.
Interoperable with your AI stack
Snorkel Flow supports cloud and on-premises infrastructure, providing enterprise-grade security, governance, and integrations with popular platforms and tools.
Learn more
Data ingest
Easily and securely integrate with enterprise data sources or upload files in standard formats.

Model training
Train predictive models via native integration with popular machine learning libraries.
Production serving
Deploy models with MLflow or via AWS SageMaker, Google Vertex AI, and Databricks integration.
Infrastructure
Host Snorkel Flow within the secure infrastructure of your choice.
Make data your differentiator and deliver specialized AI 10-100x faster
Data labeling
Capture SME domain knowledge with OOTB templates and label entire datasets on day one.
Learn more
LLM fine-tuning
Curate training data and fine-tune specialized LLMs to perform domain-specific tasks with higher accuracy.
Learn more
LLM evaluation
Perform custom LLM evaluations which measure the quality of responses based on enterprise data and policies.
Learn more
RAG optimization
Optimize RAG pipelines by fine-tuning embedding models and extracting document metadata to improve retrieval accuracy.
Learn more

Ready to get started?
Take the next step and see how you can accelerate AI development by 100x.