Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
How to build production-grade RAG retrieval with Snorkel Flow
Snorkel AI has worked with several of the country’s largest companies to help build retrieval augmented generation (RAG) systems that yield real enterprise value. These applications pair information retrieval algorithms with the generative capabilities of large language models to answer important questions quickly and accurately. In at least one case, a RAG application we helped build reduced a client’s hours-long repetitive task down to minutes.
I recently presented a walkthrough of how clients can use Snorkel Flow to build production-grade retrieval augmented generation applications. You can watch a recording of the webinar (embedded below), but I’ve summarized the main points of my demonstration here.
The value of retrieval augmented generation systems
Snorkel AI engineers helped one banking client build a RAG application to answer business-critical questions from 500+-page documents. The process used to take subject matter experts hours. The application reduced that time to minutes.
How did this RAG system work?
The system first broke the 500+ page documents into small chunks and located each within an embedding space. When users ask questions, the system first searches that embedding space for chunks relevant to the question then loads those chunks into the prompt and sends it to the large language model (LLM). Instead of getting a decontextualized question, the model gets the question with appropriate information to help answer it.
The project started with off-the-shelf components that achieved just 25% accuracy. Going from that starting point to a production-grade 89% accuracy took us on a journey, but we reached our destination much faster with Snorkel Flow.
Why do LLM systems fail?
Shortcomings in LLM-based applications fall into two main categories:
- Retrieval errors occur when the application fetches the wrong context.
- Generation errors occur when the LLM creates an undesirable response despite receiving the correct context.
Generation errors typically require that we fine-tune the LLM. That means curating appropriate responses and identifying high-quality responses to them.
Retrieval errors can originate from two primary sources:
- Suboptimal document chunking. Naive approaches may separate important fragments from each other or lump too much content together.
- Misaligned embedding models. Generalist embedding models perform well on documents from disparate topics, but often struggle to separate documents from a single topic.
Fortunately, we can address all of these challenges in Snorkel Flow.
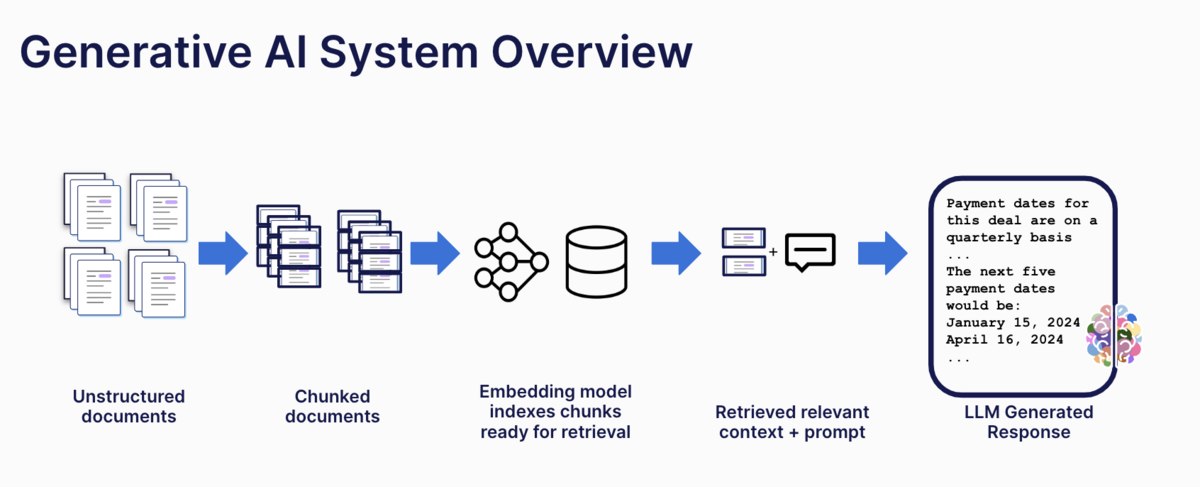
Five steps for tuning RAG systems in Snorkel Flow
Tuning a RAG application in Snorkel Flow follows a systematic five-step process.
The steps are as follows:
- Evaluate the existing pipeline: We look at the overall performance and identify issues that might prevent it from meeting the production quality bar.
- Identify targeted error buckets: The issues could be related to the embedding model, chunking algorithm, or the need to develop metadata models to better index our chunks.
- Conduct model training and fine-tuning in Snorkel Flow: We use Snorkel Flow to label, curate, and optimize data to train and fine-tune models.
- Re-evaluate the pipeline: Assess whether the modifications had the desired effect and whether the system reached the production quality bar.
- Iterate: If the system still does not meet the production quality bar, we repeat the process.
This methodical approach ensures that we optimize every aspect of the system for maximum performance. The combination of targeted improvements and iterative evaluation results in a robust, efficient, and high-performing AI system.
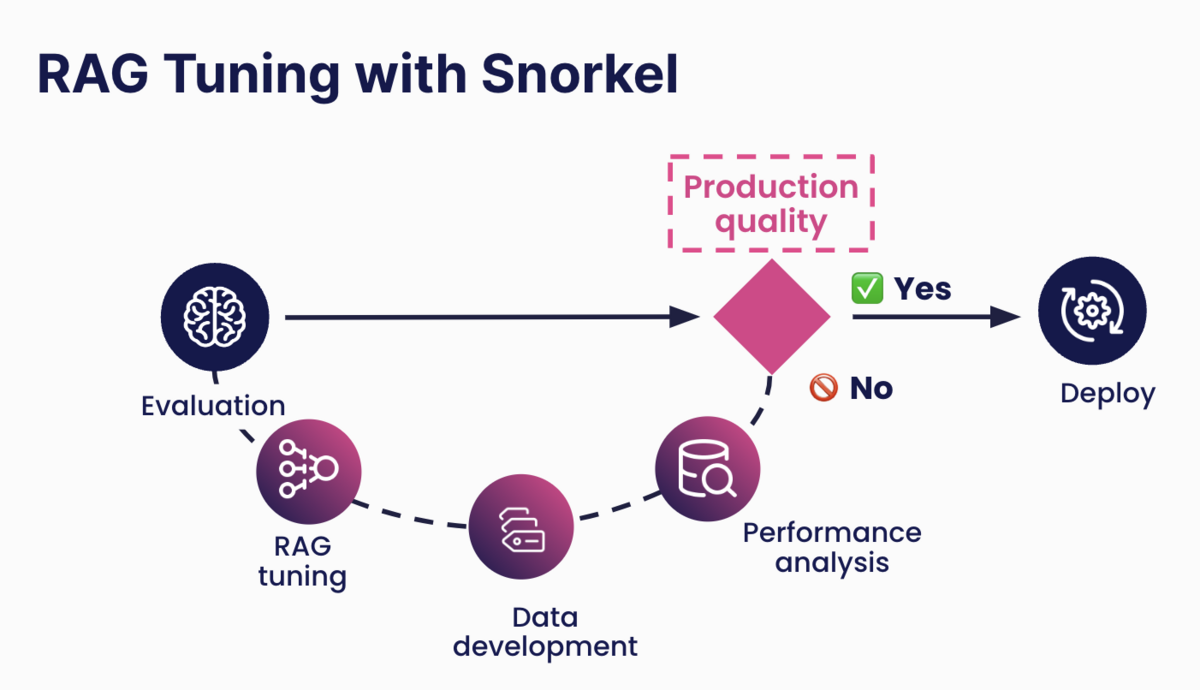
Evaluating and labeling LLM responses in Snorkel Flow
Snorkel Flow allows domain experts to evaluate and label responses from their RAG application in an easy and intuitive user interface.
The interface presents the subject matter expert with the users’ prompt, the LLM’s response, and the retrieved context added to the prompt. A panel on the right of the screen allows the SME to rate the context and response individually to locate the problem with the retrieved context, the LLM, or both.
The interface also allows the SME to tag common error modes. For example, the retrieval pipeline may pull text from the table of contents instead of a relevant chapter. By noting common error modes directly in the platform, data scientists can later address them with data labeling and filtering.
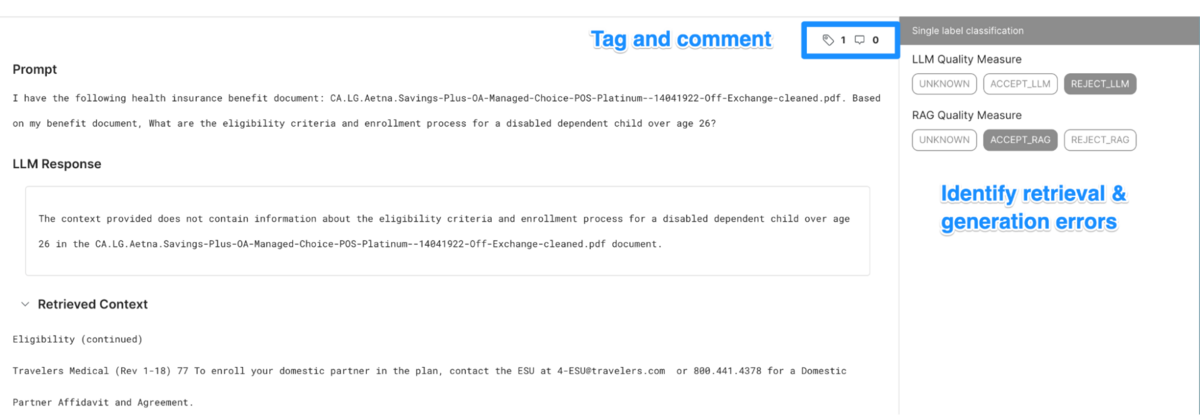
Improving document chunking
Document chunking forms the foundation of any retrieval-augmented generation pipeline. It involves the logical division of documents into manageable and meaningful sections, or “chunks.”
Naive chunking approaches typically split documents into sentences, paragraphs, or sections of a fixed length. These approaches can lose important information stored in the document’s layout. It may subdivide tables or break apart coherent sections.
Creating optimal chunks requires a rich understanding of document structure and a semantic understanding of the relevant sections. Snorkel’s DynamicChunker uses this information to encapsulate each logical section of a document into its own chunk.


Document enrichment: models to improve RAG retrieval
Document enrichment repurposes classification models to improve the performance of RAG pipelines. In this approach, we create metadata models to tag sections or figures with specific topics or values.
In Snorkel Flow, we build these metadata models rapidly and accurately by relying on subject matter expertise and scalable labeling functions. For instance, we might train a model to tag numerical figures detected within a document as “annual deductible” or “monthly premium.”
The labeling functions for these models will likely start with an LLM prompt and then use precise SME guidance to correct the LLM labels where they’re wrong. For example, Snorkel Flow users may define a labeling function that applies the “annual deductible” tag to the first number that follows the words “annual deductible.”
This document enrichment approach allows us to optimize the search and retrieval space at inference time and make our LLM responses more precise.

Snorkel metadata models identify important document characteristics that lead to improved retrieval.
Customizing embedding models
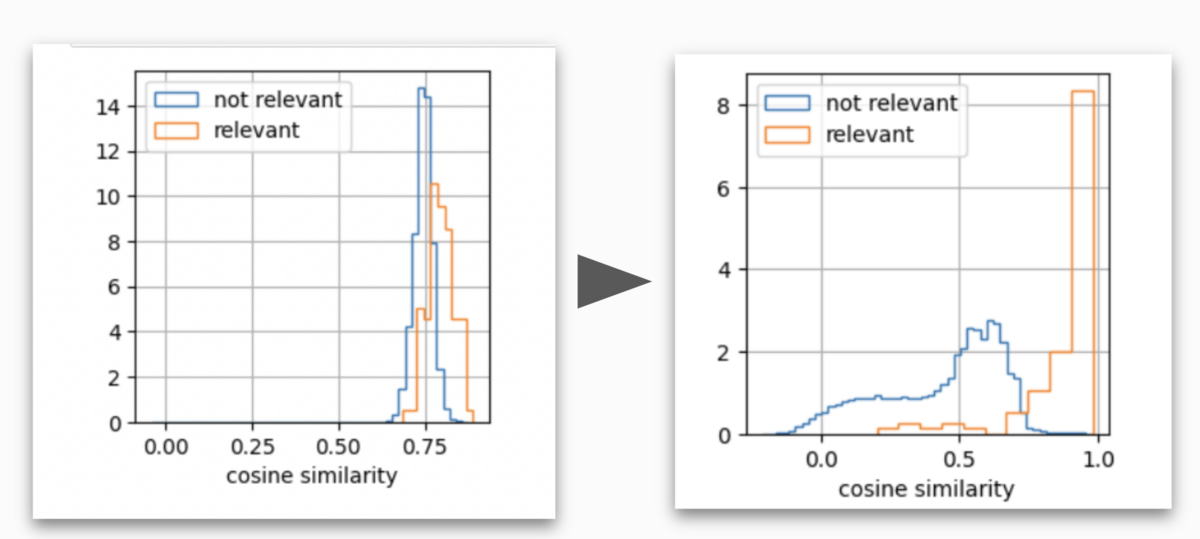
Customizing and fine-tuning embedding models can yield significant improvements in the performance of RAG systems.
Using Snorkel Flow, we can scalably create pairs of questions to connect with context chunks. Each question pair includes one question that would appropriately be answered by the chunk and one that wouldn’t. These questions should both be relevant to the topic, but not the question itself.
Feeding these positive/negative pairs to the embedding model pipeline helps the model better understand the topic space and more finely parse subtopics. This, in turn, helps the model retrieve the correct context at inference time.
Fine-tuning and aligning large language models
After a developer has sufficiently addressed retrieval errors, they may turn their attention to generation errors via LLM fine-tuning. Snorkel offers an end-to-end workflow for programmatically aligning LLMs to company policies and objectives. We will share more about this approach in an upcoming webinar and associated blog post, so stay tuned!
In the meantime, you can read my colleague Chris Glaze’s post about how his team used Snorkel Flow to curate prompt and response training data for the open source RedPajama LLM.
Building high-performance retrieval-augmented generation systems
Snorkel Flow empowers businesses to build robust and efficient retrieval-augmented generation (RAG) applications. The platform enables subject matter experts and data scientists to collaborate to identify shortcomings and develop their proprietary data to improve the performance of several components of RAG applications.
By following our iterative development loop, Snorkel Flow users can build reliable and high-performing RAG systems that solve real-world business problems—and they can do so quickly.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Marty Moesta
Marty Moesta is the lead product manager for Snorkel’s Generative AI products and services, before that, Marty was part of the founding go to market team here at Snorkel, focusing on success management and field engineering with fortune 100 strategic customers across financial services, insurance and health care. Prior to Snorkel, Marty was a Director of Technical Product Management at Tanium.