
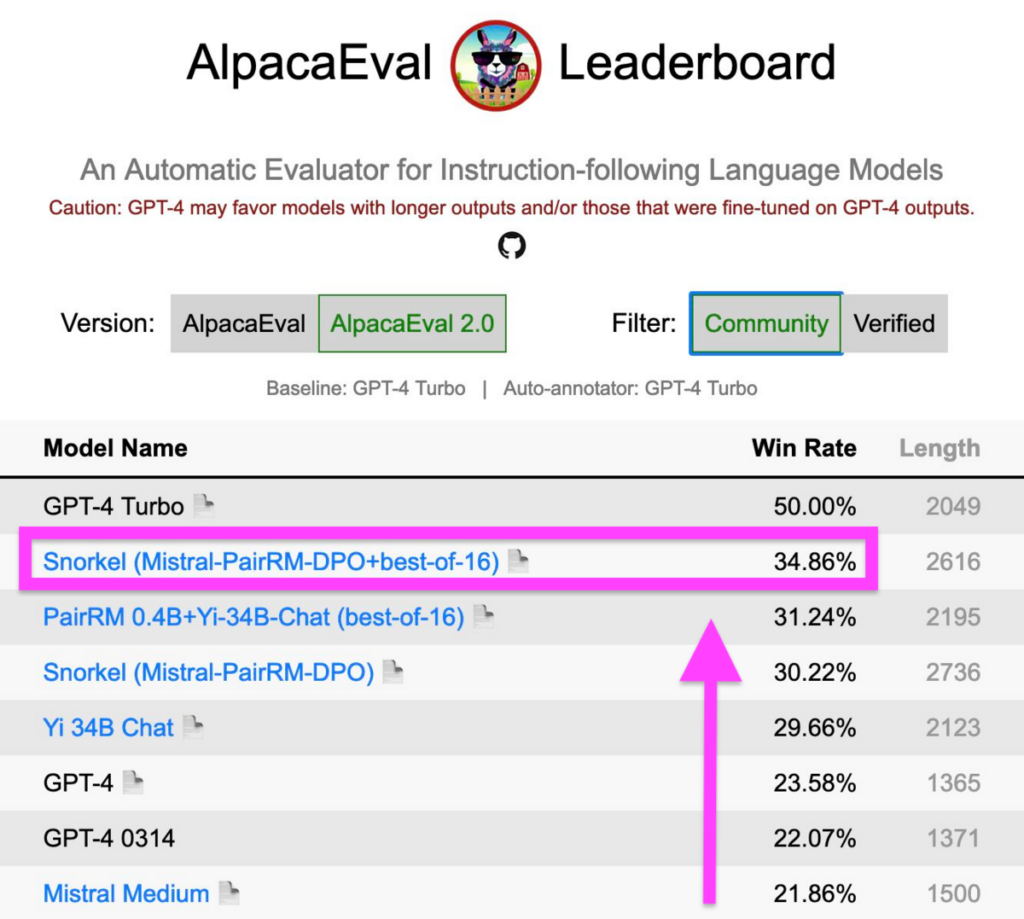
Back in January, Snorkel AI placed a model at the top of the AlpacaEval leaderboard. It beat the next-best competitor by more than seven points and maintained its rank for longer than a month. Recently, I talked with Matt Casey, data science content lead at Snorkel AI, about how we built the model using direct preference optimization, how it changed the AlpacaEval leaderboard, and how it will help us build better, more useful large language models for Snorkel’s customers.
I recommend that you watch my interview with Matt (embedded below), but I also wanted to share some of my thoughts in writing.
What is the AlpacaEval Leaderboard?
To start, let me explain our basic achievement.
The AlpacaEval tool automatically evaluates the instruction-following capabilities of large language models (LLMs). It feeds the model prompts from the AlpacaFarm evaluation set and measures how well an LLM understands and executes the given instructions by comparing the LLM’s responses to those from GPT-4. An auto-annotator model chooses which model produced the “better” response, creating a win rate.
Because the evaluation results in winning or losing, it lent itself to a leaderboard where researchers and data scientists can demonstrate how different model approaches result in better or worse win rates against GPT-4.
Our state-of-the-art open-source model placed second on the leaderboard—second only to GPT-4, which serves as the auto-evaluation standard—and beat many closed models.
For a small research project, we thought this was a significant achievement.
How we used direct preference optimization (DPO) on our model
LLM training happens in three phases: pre-training, fine-tuning with prompts and responses, and alignment. My colleague Chris Glaze and I previously worked on a successful research project to build a better LLM by curating high-quality prompt and response data, but this project focussed on alignment.
The alignment phase nudges the model’s outputs closer to what actual users want. This is tricky. User feedback data is hard to find in the wild. OpenAI hired a lot of people to rank and rate model responses. Most companies can’t afford to do that.
Data scientists can use indirect signals to infer the quality of a response—such as whether or not the user clicks on an included link—but these signals can be misleading.
Instead of trying to find or create a large, human-created preference data set, we decided to create synthetic alignment data. Using prompts from UltraFeedback and self-generated responses from our base LLM, we utilized a helper model that reliably ranks LLM responses to which one is preferred.
Then, we created a training loop. Our base LLM created several responses. Our helper model rated them. We kept the highest-rated response as “accepted” and marked the lowest-rated response as “rejected,” and used these to align the model. We performed self-generated responses to mimic the reinforcement learning with human feedback (RLHF) pipeline, and at the same time, not rely on outputs of larger models like other approaches.
Here, the ranking model is PairRM from AI2 and the base model is Mistral.
Why was DPO more preferred than RLHF for this project?
Until recently, nearly all LLM alignments used RLHF. This typically involves getting users to rate or rank multiple responses, training reward models to learn human preferences, and using reinforcement learning/PPO to train LLMs to maximize the reward scores (a proxy for human preferences).
DPO, in contrast, uses binary feedback. A response is either accepted or rejected. The model tries to adjust its output to look more like accepted responses and less like rejected ones.
DPO offered two main advantages over RLHF for this project:
- Improved stability.
- Computational efficiency.
In earlier experiments with RLHF, we saw our LLM’s loss curve explode and sometimes become very repetitive. The DPO approach avoided those over-fitting and instability pitfalls.
For reasons I won’t go into great detail about here, DPO is also much more computationally efficient than RLHF, which allowed us to run our experiments faster and at a lower cost.
Our “iterative DPO” approach also allowed the model to be more “creative” than the original DPO implementation. The original DPO utilizes human-written documents as preference data. The iterative approach with self-generation allowed the models to be rewarded for any self-creativity as long it aligned with the reward policy.
In my talk with Matt, I used the example of saying “thank you.” If you had a model that was not trained to say “thank you,” it could happen to develop that behavior during alignment with DPO—so long as users appreciated that behavior.
What happened next for the AlpacaEval Leaderboard?
If you look at the AlpacaEval leaderboard now, you won’t see Snorkel at the top. Our model has fallen quite a bit—down to 12th place, as of this writing. While part of that is due to other researchers building newer, better models, the bigger part of our model’s fall is because we asked for the leaderboard to change its rating approach, which Yann Dubois from AlpacaEval team has proactively addressed in the new version.
We noticed that AlpacaEval showed a bias for longer responses. The reward model we used also favored longer responses. That, in turn, encouraged our model to create longer responses.
But longer isn’t better. Sometimes, ten words are better than 100. We raised a GitHub issue to adjust models’ scores according to their response length. The new length adjustment lowered our score by almost five points—from 34.9 to 30.0.
That’s okay with us. We’re more interested in helping to push the field forward than we are interested in standing atop a leaderboard.

What does this mean for Snorkel Flow customers?
Snorkel AI is a research-led company, but we don’t just do research for fun. This project helped prove a path for how we can help enterprises align their LLMs in the future.
We likely won’t use the reward model we used for this project for our customers. That model and training loop aimed to create a high-performing LLM for a general audience. That’s not what we do for our customers. “Good” requires context. In the enterprise setting, only subject matter experts can supply that context.
In my talk with Matt, I gave the example of a customer-facing model built for the insurance or finance industry. That model should not give anything that resembles personal financial advice. Ever. Working with a bank’s SMEs, we could help build a reward model that would align the model to those guidelines.
From research to leaderboard to customer use
This project proved a couple of things. It proved that a DPO and a reward model in a loop could scalably align high-performance models. It proved that good-faith open-source collaboration can help nudge the field forward, and it proved a path for building better, more high-performant models for Snorkel’s customers.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Hoang Tran
Senior Machine Learning Engineer
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor’s degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

