
Humans learn tasks better when taught in a logical order. A child who has already learned addition, for example, will have an easier time learning multiplication. Along with our collaborators at Stanford, I and my students at the University of Wisconsin-Madison have discovered that a similar logic applies to large language models, and we’ve developed a way to exploit this tendency that we call “Skill-it!”
I recently presented a summary of our Skill-it! research findings at Snorkel AI’s Enterprise LLM Summit. The presentation also included a peek into some other research we’ve done on how to strengthen foundation models when you don’t have additional data, a process we call “zero-shot robustification.” You can watch the entire video below—which I would recommend—but I’ve summarized the main points here.
Understanding Skill-it!
Large language models (LLMs) can accomplish a diverse range of tasks, from writing code to chatting with users. However, the sheer amount of data they need to process during training can be overwhelming. That’s where Skill-it! comes in.
The Skill-it! tool helps us select and order the data these models are trained or fine-tuned on to enhance their capabilities in the most efficient way possible.

In Skill-it!, we define a “skill” as a specific capability or behavior that the model acquires from a piece of data. This could be a task, a data source, a category, or a family of tasks. We then partition our dataset into different groups that correspond to these skills.
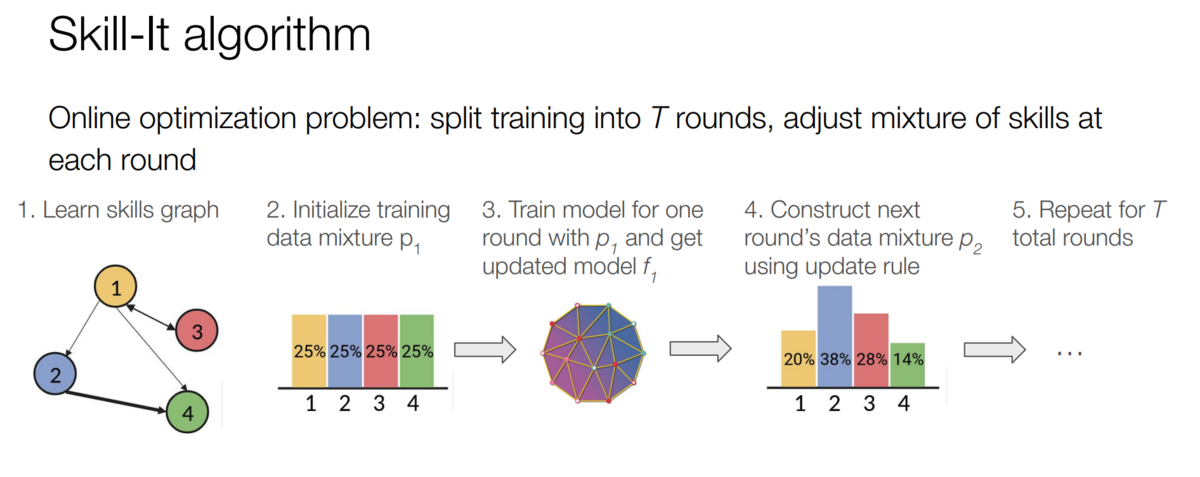
From here, we construct what we call a “skills graph.” This graph represents the different skills we’ve identified, with edges between skills indicating how learning one skill can aid in learning another. This graph allows us to create an “order” for the skills, helping the model learn more structurally and efficiently.
The algorithm adjusts the mixture of skills at each round of training, basing these adjustments on the skills graph and the model’s performance on each skill. An initial data mixture trains the model for one round. Then, Skill-it! constructs a new mixture based on an update rule. This update rule takes into account adjacency from the skills graph and the evaluation loss, allowing us to continuously refine the data mixture to optimize each round of the model’s learning process.
The Impact of Skill-it!
Skill-it! has demonstrated significant impact in optimizing the training of language models. Its performance has been tested across a variety of tasks and baselines, consistently proving its efficacy. Here are some noteworthy accomplishments of Skill-it!
- Performance across multiple tasks: Skill-it! outperformed other methods in a diverse set of tasks. In one example involving question generation in Spanish, Skill-it! managed to improve the validation loss rate significantly faster than other methods.
- Superiority over baselines: In a comprehensive evaluation involving 12 different baselines, Skill-it! emerged as the top performer in 11 cases.
- Efficiency: Skill-it!’s approach to ordering and mixing training data based on the skills graph and evaluation loss results in a more efficient learning process.
- Scalability: Not only does Skill-it! perform well on individual tasks, but its performance also scales effectively when applied to larger, more complex models.
Zero-shot robustification
In certain situations, we may not have access to additional data for training. This is where a technique we call “zero-shot robustification” comes into play. This innovative approach offers a unique solution to improve the robustness of models without the need for external data.
Understanding zero-shot robustification
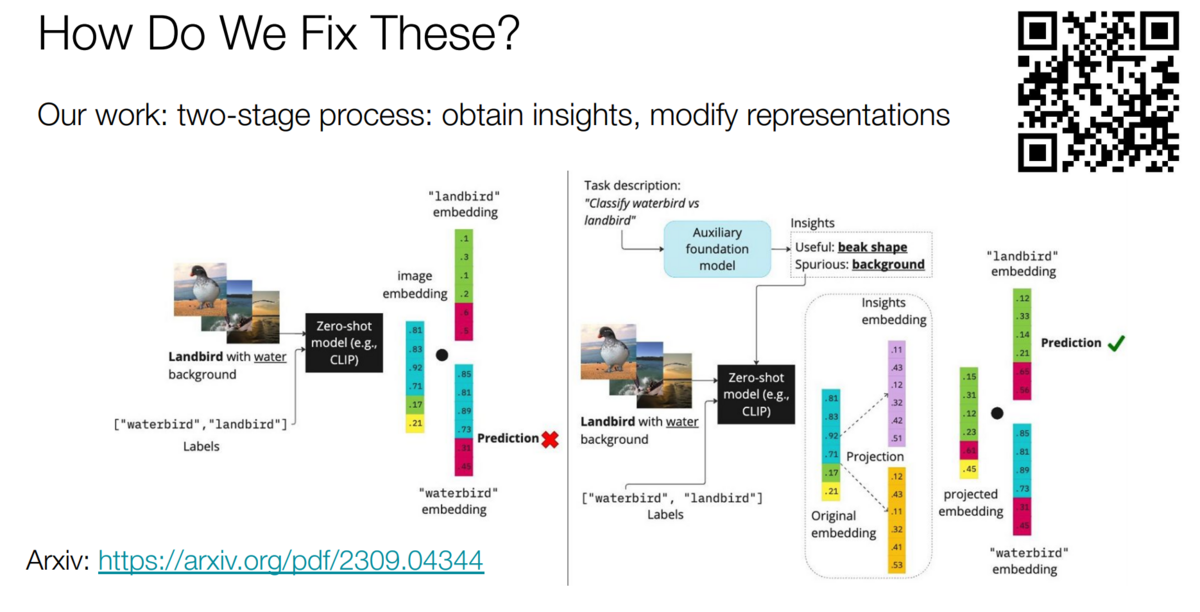
Zero-shot robustification operates on a simple yet powerful premise. It queries an LLM for insights into its understanding of useful features and those that are spurious or misleading.
In our paper on the topic, we use the popular Waterbirds dataset, which requires distinguishing between water birds and land birds. An unmodified CLIP model would frequently confuse land birds shown in or near water as water birds, and vice versa. We asked an LLM what features to emphasize and ignore. It suggested—correctly—that we should ignore the background and focus on the shape of the bird’s beak.
We then use those insights to guide the CLIP model’s predictions on the fly—without any fine-tuning or training data.

The Process of Zero-Shot Robustification
Once we’ve gathered these insights, the next step involves modifying the model’s representations based on this newfound knowledge.
How can we turn the text-based insights into a way to modify our model’s representations? First, we embed them (e.g., with CLIP’s text encoder). Next, inspired by work on debiasing word embeddings, we use simple linear-algebraic operations. For example, to get rid of a spurious concept, we project the current representation onto a subspace invariant to the one spanned by the embedded spurious insight. This boosts the features that the language model has identified as useful and diminishes or eliminates those that are deemed spurious. This fairly simple procedure has the potential to dramatically increase prediction quality without any external data.
The Impact of Zero-Shot Robustification
This approach to robustification can significantly improve the model’s robustness. Even without access to additional training data, zero-shot robustification allows us to leverage the model’s inherent knowledge to enhance its performance. This not only helps make the models more reliable but also aids in mitigating issues caused by spurious correlations, leading to more accurate predictions and outcomes.
Getting more from foundation models more efficiently
Skill-it! and zero-shot robustification provide powerful tools for optimizing the training and robustness of foundation models. By ordering training data efficiently and leveraging the model’s inherent knowledge, we can greatly improve the performance of foundation models across a range of tasks.
As we continue to explore these techniques and others, we look forward to the future of language model training and the potential it holds.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Fred Sala
Chief Scientist
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on data-centric AI, foundation models, and automated machine learning. He and his group received the 2024 DARPA Young Faculty Award, a best student paper runner-up award at UAI ’22, the outstanding Ph.D. dissertation award from the UCLA Department of Electrical Engineering, the NSF Graduate Research Fellowship.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

