Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
How a global financial services company built a specialized AI copilot accurate enough for production
A multinational, multibillion-dollar financial services company set out to develop an AI copilot which could provide call center agents with helpful answers to customer questions. The goal was to generate high-quality, low-latency responses without incurring significant inference costs as usage grows. However, ChatGPT 3.5 Turbo with RAG suffered from poor accuracy and hallucinations—and annual token costs were projected to exceed $1.5M within three years.
To overcome these challenges, the company adopted a set of guiding AI principles and embraced data-centric AI.
AI principles
- Be model agnostic, and choose the right one for the right use case
- Fine-tune smaller, open LLMs to match the accuracy of closed ones
- Self-host models to eliminate token costs and ensure fast responses
Data-centric AI
- Curate high-quality training data via AI data development
- Apply programmatic labeling and evaluation for rapid iteration on training data
- Fine-tune open models on enterprise data to perform specialized tasks
The team successfully adopted these principles, and partnered with Snorkel, Databricks, and AWS to implement a data-centric approach to AI development—enabling them to build specialized models trained on their own domain knowledge and data, and to meet production accuracy and cost requirements.
Results
- Improved response accuracy by 26 points
- Reached 99% confidence with near-zero hallucinations
- Reduced projected inference costs by up to 10x
- Achieved a Time to First Token (TTFT) of 1s
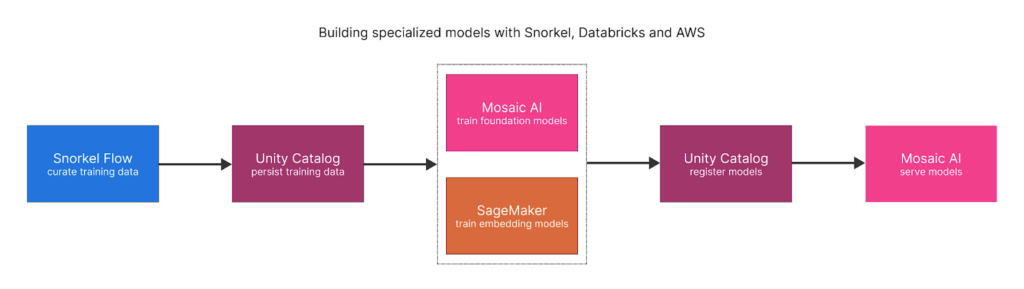
Data-centric AI with Snorkel, Databricks, and AWS
Snorkel, Databricks, and AWS enabled the team to build and deploy small, specialized, and highly accurate models which met their AI production requirements and strategic goals.
Foundation:
- Snorkel Flow for quickly curating high-quality, labeled training data at scale.
- Databricks Mosaic AI for easy, cost-effective foundation model fine-tuning and inference.
- AWS for cloud infrastructure and to fine-tune their embedding model with SageMaker.
The key to ensuring their AI copilot generated accurate and complete answers, and not hallucinations, was deploying an optimized RAG pipeline which always grounded answers by relevant information contained within their knowledge base (KB). This was accomplished by fine-tuning a bge-large embedding model to increase retrieval accuracy by 16 points and fine-tuning a Mixtral 8x7B foundation model to improve response quality.
The team developed an internal LLM evaluation framework which scores models based on response accuracy, compliance, and reliability. When evaluated with this framework, their optimized RAG pipeline scored 15 points higher than an out-of-the-box RAG pipeline with a base 70B model and 26 points higher than one with GPT 3.5 Turbo.
AI data development
Curating high-quality training data
Creating question-chunk pairs
The team began by requesting frequently asked questions from subject matter experts (SMEs), combining them with questions extracted from call center transcripts, and importing all questions into Snorkel Flow.
Next, they needed to pair these questions with relevant chunks from KB articles. This was done by taking advantage of a) collaborative data labeling to create a validation dataset for evaluating the embedding model and b) programmatic data labeling to create training and test datasets for fine-tuning it.
- SMEs tagged a subset of questions with the IDs of KB articles containing relevant information. The KB articles were looked up and the relevant chunks identified, resulting in a validation dataset composed of question-chunk pairs.
- The remaining questions were sent to a RAG pipeline (with the base embedding model) in order to retrieve relevant chunks for them, resulting in training and test datasets.
- The training and test datasets were then augmented by generating synthetic question-chunks pairs in Mosaic AI—using foundation models to generate relevant questions from unused chunks, and importing the pairs into Snorkel Flow.
Creating question-chunk-answer triplets
The question-chunk pairs created for training, testing, and validating the embedding model were transformed into question-chunk-answer triplets by generating answers with foundation models such as DBRX via RAG.
Identifying “good” triplets
The team took advantage of collaborative data labeling to create a validation dataset for evaluating the foundation model as well as programmatic data labeling to create training and test datasets for fine-tuning it.
- SMEs manually labeled triplets as good or bad in order to curate a golden dataset for evaluating programmatically labeled triplets (described below) as well as the overall accuracy of the RAG pipeline.
- SME acceptance criteria was then captured within Snorkel Flow labeling functions, which were used to programmatically label the remaining triplets as good or bad.
Model training
Fine-tuning
The good triplets were filtered out to create high-quality training data for fine-tuning both the embedding model and the foundation model. The foundation model training data was exported from Snorkel Flow and imported into Mosaic AI where it was then used to create a fine-tuned Mixtral 8x7B model. The embedding model training data was used to create a fine-tuned bge-large model with SageMaker.
This was an iterative process whereby both the training data and the models were continuously improved. The models were fine-tuned on training data. Then, the training data was improved with additional SME feedback as well as results from the fine-tuned models. The process continued until the fine-tuned models reached production accuracy.
Evaluation
In order to evaluate the results of the fine-tuned models, for both retrieval and generation, a separate model was created within Snorkel Flow which predicts whether triplets will be labeled good or bad based on previously captured SME acceptance criteria. After each fine-tuning iteration, this Snorkel Flow model—along with the ground truth/validation dataset—was used to evaluate both the fine-tuned bge-large embedding model and the end-to-end RAG pipeline, which included the fine-tuned Mixtral 8x7B foundation model as well.
Model deployment and inference
The team chose Databricks Mosaic AI, itself built on the Databricks Data Intelligence Platform, for deploying the optimized RAG pipeline, which included both the embedding model and the foundation model, as well as native vector search. With Mosaic AI, they fine-tuned the foundation model 4x faster than alternative approaches and, once deployed, benefitted from a TTFT of 1s—far lower than their requirement of 5s or less.
Proven path to GenAI success
By adopting Snorkel Flow for AI data development, Databricks Mosaic AI for open model fine-tuning and inference, and AWS for the cloud infrastructure upon which Snorkel Flow and Mosaic AI were deployed as well as supplemental AI/ML services, this multinational financial services leader developed a state-of-the-art platform for building and deploying small, specialized, and highly accurate AI models to support current and future GenAI initiatives.
They not only achieved success in deploying a production AI copilot, they met their goals of generating accurate responses with high confidence (and eliminating hallucinations), preventing linear growth in the tokenization costs of closed model APIs, and becoming fully model agnostic.
Learn more
Watch this demo from Marty Moesta, Snorkel’s lead product manager for GenAI, and see how RAG pipelines can be optimized with Snorkel Flow. Or, register to join one of our weekly demos which regularly cover RAG optimization and LLM fine-tuning/evaluation.
Topics

Team Snorkel