Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Cohere’s Alammar encourages effective strategy for Generative AI
Jay Alammar, director and engineering fellow at Cohere, presented a talk entitled “Generative AI is… what, exactly?” at Snorkel AI’s recent Foundation Model Virtual Summit. Below follows a transcript of his talk, lightly edited for readability.
Let’s start by defining a little bit of what we mean when we say, “Generative AI.” Recently, AI systems have been able to generate interesting things. That includes images. There have been a lot of very interesting developments in AI image generation over the last six months, maybe, that the vast majority of people now have access to. This is in creative fields, but also it’s in design, in architecture, etc. People have been using these, even though they’ve only been publicly accessible for a few months, to really stretch their imaginations and imagine these interesting ideas and places.
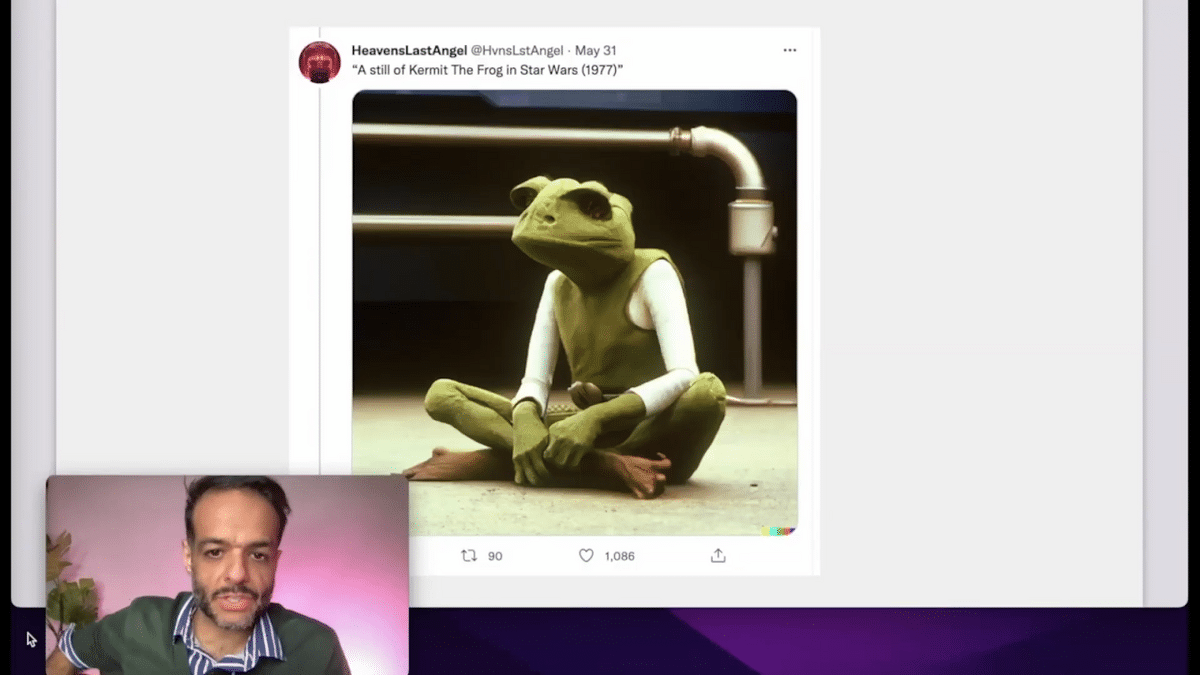
One of the first applications here that really captured my excitement is this series of prompts to one AI-image generation model that says, okay, this is “a still of Kermit the Frog in ‘Star Wars,’” and the model generates an image like this just from that text alone. This is a model that was not trained specifically on movies or on Muppets. But, that it’s able to capture a little bit of the essence of the frog and how it would look in the world of Star Wars was a little mind blowing to me. I’m gonna be honest.
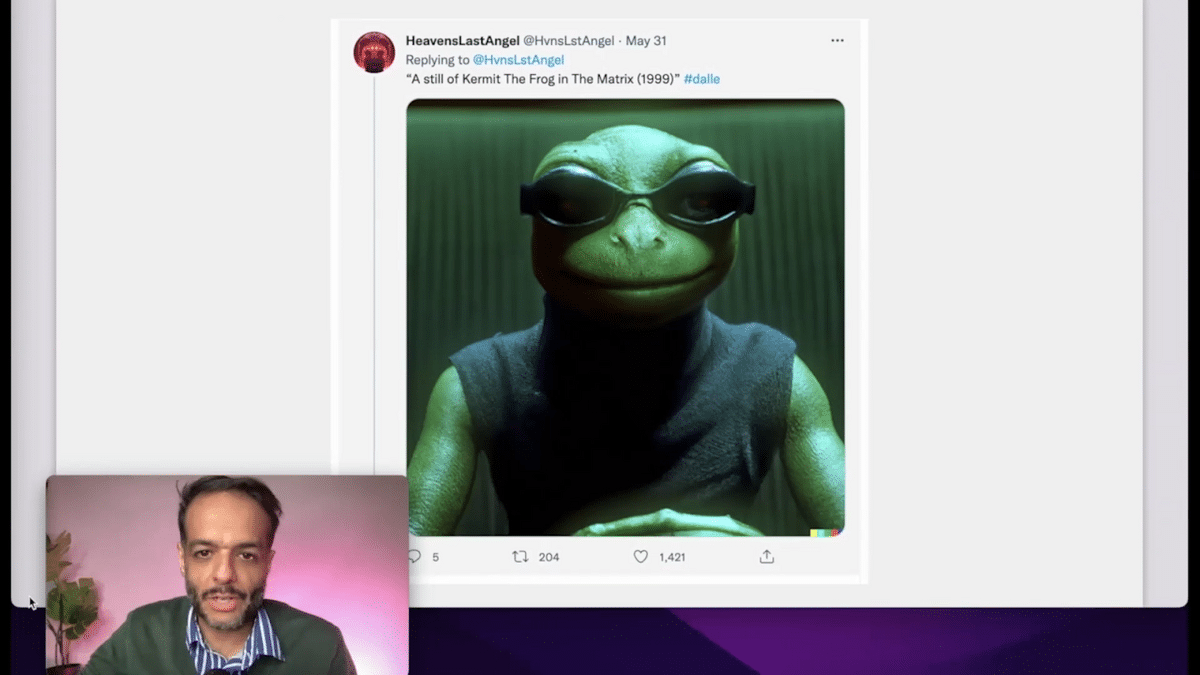
This is another one where it also put Kermit the Frog in “The Matrix.” You can see how it captures the lighting, the aesthetic, just the dramatic cyberpunk aesthetic.
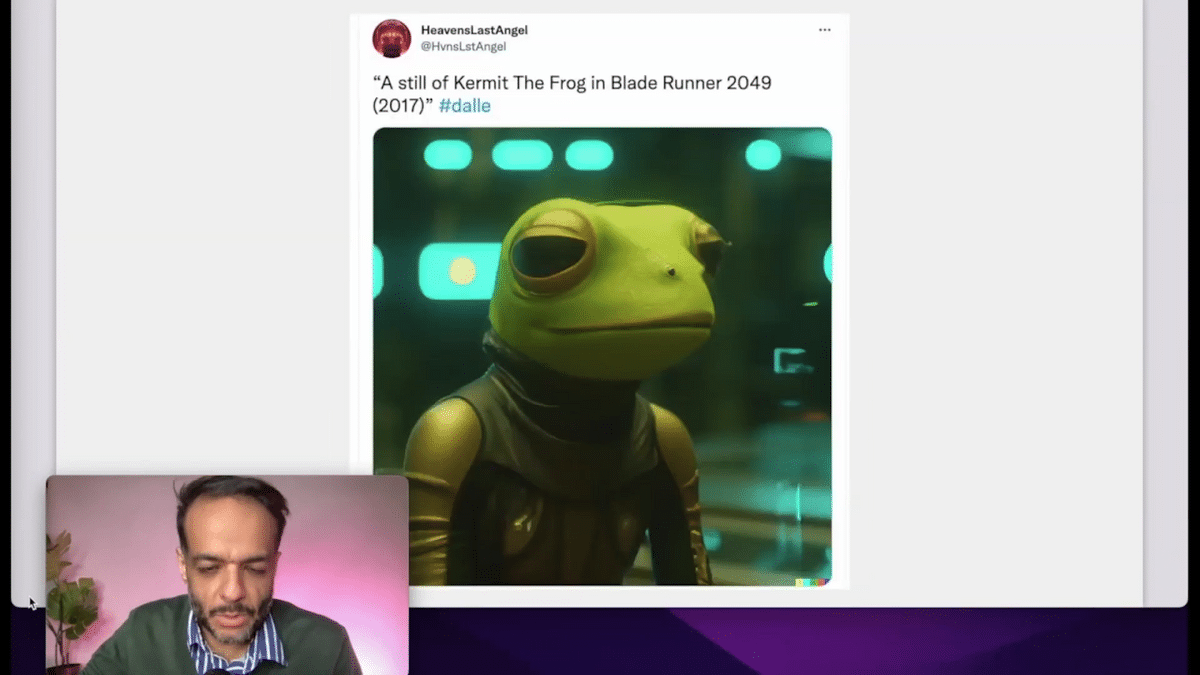
“Blade Runner” is even more neon and cyberpunk.
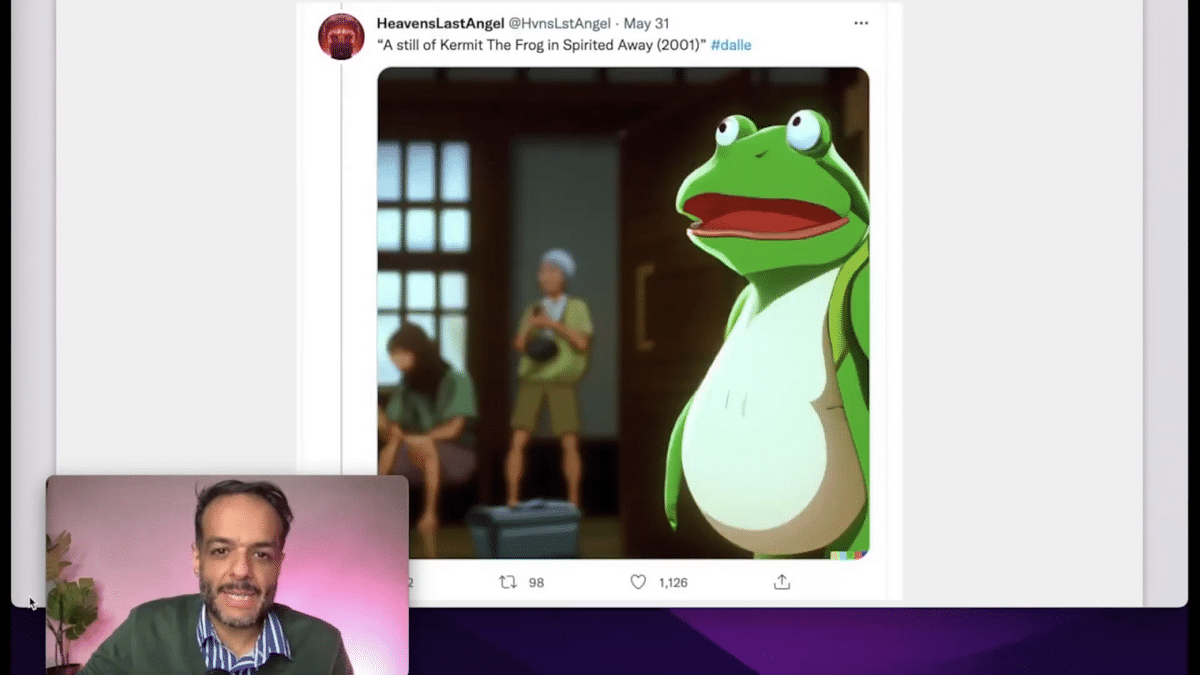
But also, if you give it the name of an anime it will put the frog in “Spirited Away,” in this case.

It’s already been winning awards for art shows.
But it’s already gone beyond just this idea of fun projects or fun tools to becoming this new industry. A lot of the momentum around the term, “Generative AI,” comes from articles like this—from venture capital funds that are describing this industry that’s coming out of using these capabilities of software that were manifested by artificial intelligence.
A lot of these articles have images like this that show you a lot of new products that are trying to innovate on top of this “Generative AI” theme. You can see some of them are entire new industries of copywriting companies, for example, whether that be marketing, or just general writing, or others. You can see text in the blue here, but you can have these others: image generation, code generation, speech. These are called different modalities. You can see a lot of companies and products popping up around these types of services and technologies.
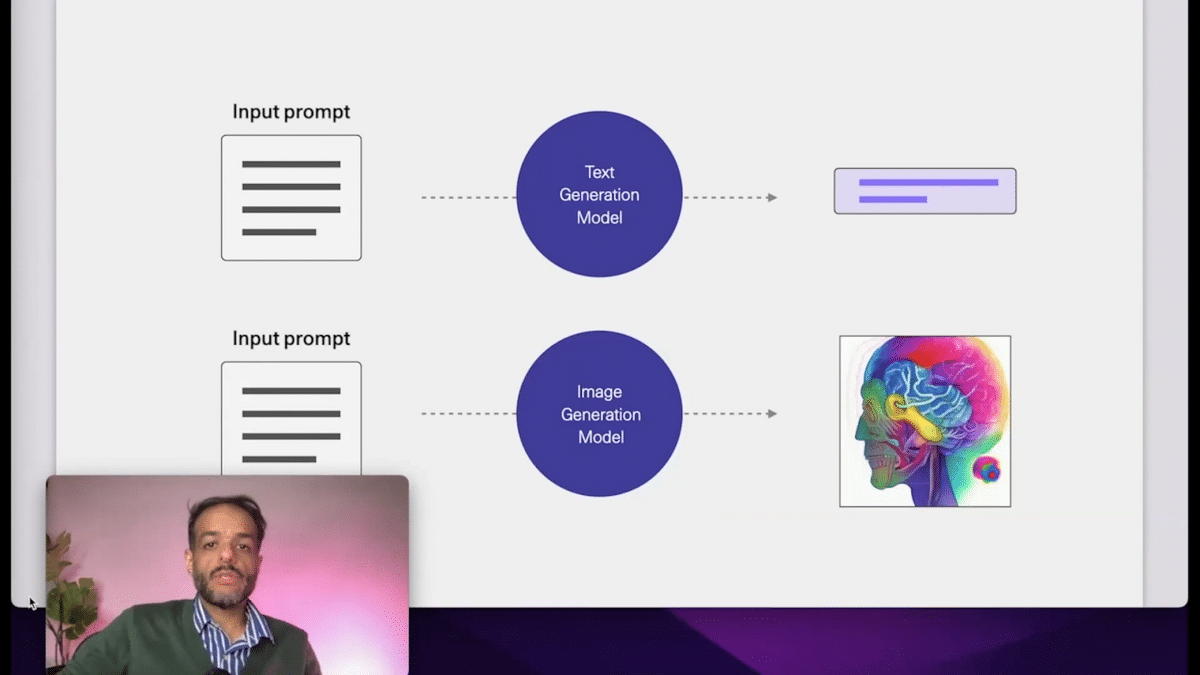
If I’m to, maybe, summarize the two main components of what we would call Generative AI at this time, it would be: number one, text generation models. These are these large GPT models that are able to generate text that is very coherent, and we can shape the input prompts for them to create some rather useful outputs. We’ll be talking a little bit about that. And then, number two, we also lump image generation under that.
You can already do some very interesting things with text generation. You can brainstorm with these models. You can have them give you ideas. So, if you’re a creator and you’re afraid of a blank canvas, these models are really great writing aids—that’s how I use them a lot—but they also can help with a lot of specific use cases. If you’re interested in summarization, or rewriting, or copywriting, they can do all of these and more.
I used to use boxes. We will be drawing a few figures of what generation models look like. So, let’s actually use Generative AI to inform what kinds of figures we paint. So when I say, “text generation model,” I’m going to start to paint them like this. This was made by an AI image generation model.

And we can also generate another one for image generation models. Let’s use the tools that we’ll be talking about here to brand some of the concepts.
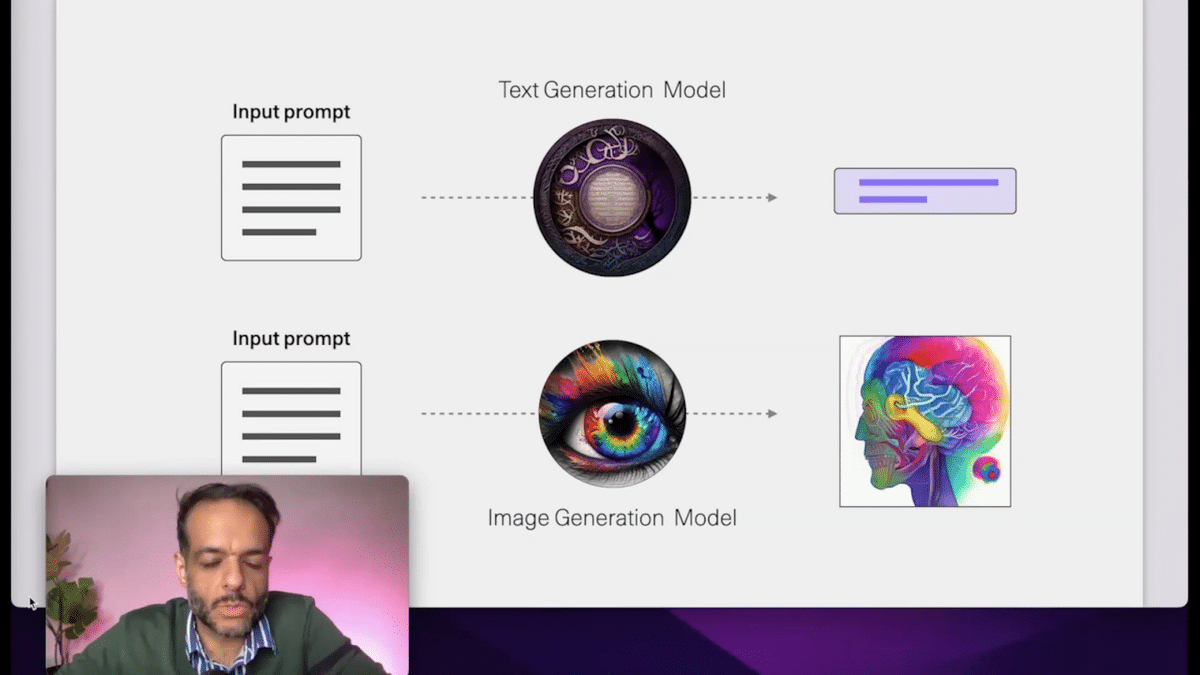
When we talk about Generative AI at this time, it’s mostly the commonly available tools for text generation and image generation. There’s a lot of research on video generation, there are a lot of ideas on can you generate music and other types of media. We’ll see more and more of that in the future, but that hasn’t been, let’s say, “accessible” to the common person yet.

I work at Cohere, which is working to make NLP (Natural Language Processing) part of every developer’s toolkit. We’ve been featured in a number of these lists, and the main idea is that Cohere trains these large language models and offers them on the cloud via API.
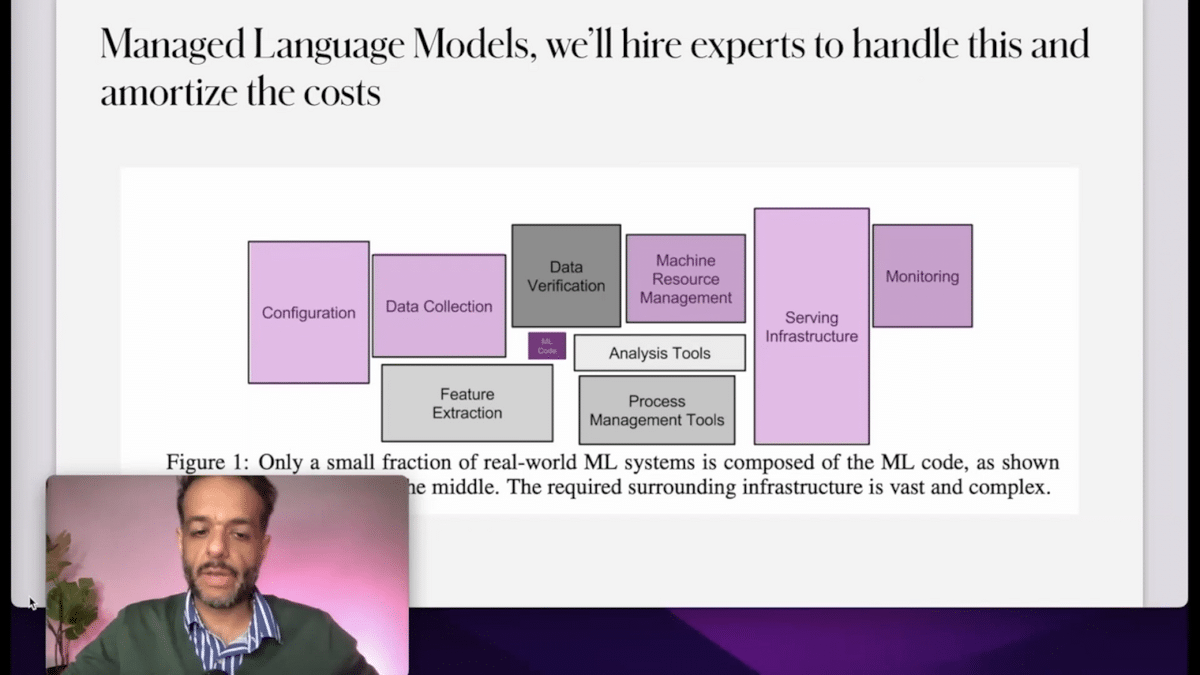
If you use a managed language model provider, you get all of these benefits, as compared to trying to deploy your own model and trying to figure out serving and monitoring. That’s a little bit of a high-level overview of what we do.
Text generation is one of the two families of NLP models that we work with at Cohere. We’ve been working with developers and companies for the last couple of years to help them use these models to solve real-world problems. So, we’ve seen a lot of use of text generation models and how to think about deploying them and using them, what kinds of use cases. That’s what informs a lot of this talk here. We can infer a bunch of these lessons and extrapolate them to image generation and other types of Generative AI that are coming down the pipe in the future.

“Generative AI is impressive,” was the first section, and I’m sure you’ve already come across things that impressed you about Generative AI. One of the challenges is that, yes, it can be impressive, but it’s not yet reliably impressive. It’s not ready for you to put in front of a live use case, where every output of the model is served to an end user, for example. There are certain scenarios where the models work best and what sort of workflows they’re best fit for. We’ll talk about a few of them here.
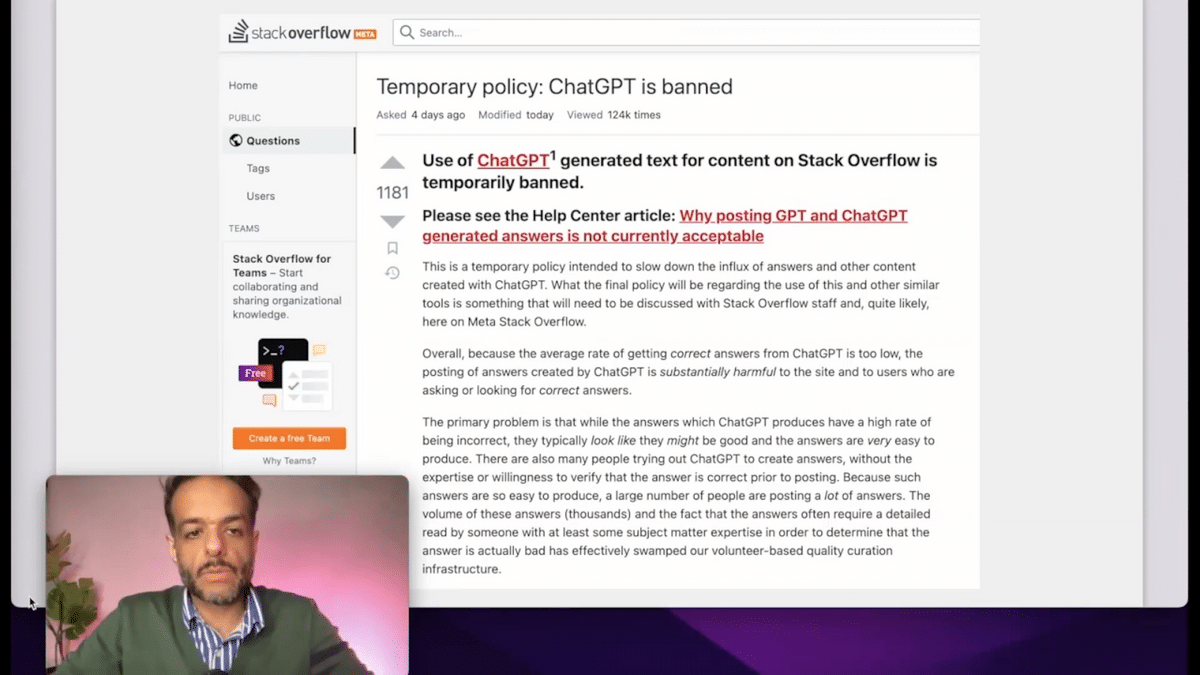
This challenge of reliability is evidenced by some websites like Stack Overflow, banning GPT-generated answers from the website because it’s harmful to the website and because the text typically looks good and is very readable and coherent.

But the actual answer is, on average, incorrect.
That’s a little bit of a challenge that, ironically, comes from us creating better and better models. We need them not just to be really good at coherent text, but then we start to have this expectation of, “okay, are they trustworthy? Are they factual?” That reliability is one thing that we need to think about when we think about Generative AI.
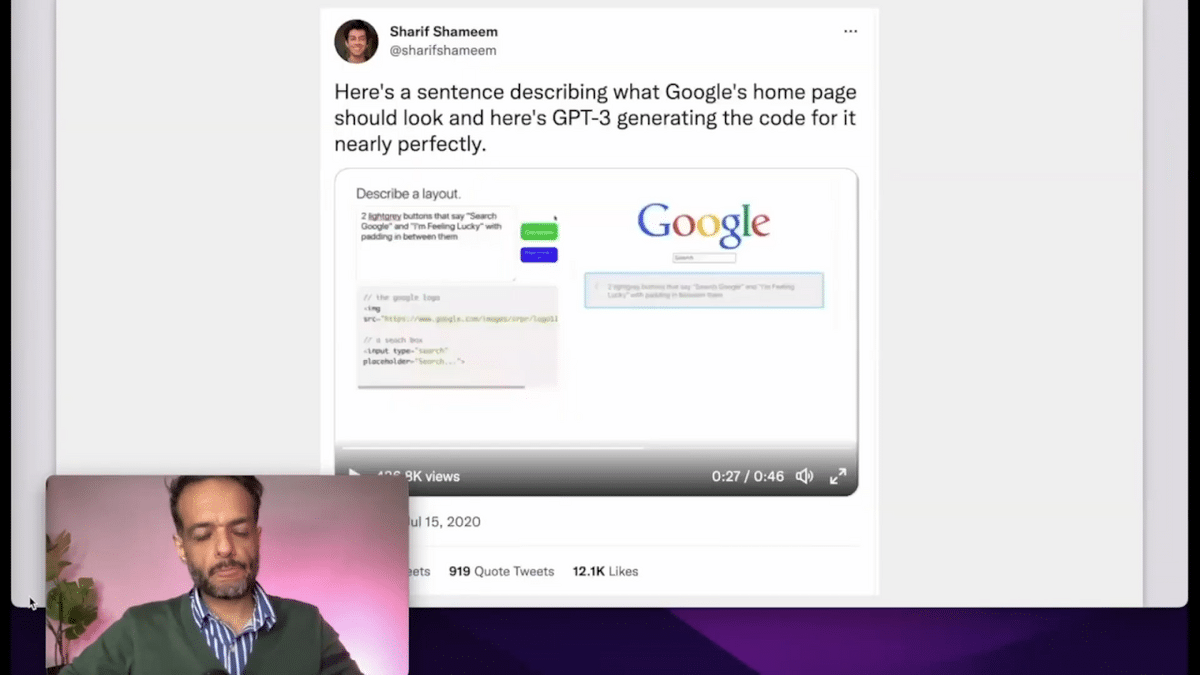
This is one of the first, let’s say, tweets or applications that really blew my mind about model X GPT-3, which is this demo where you describe a website and the model generates the code for you to build that website. It’s a really impressive example. It probably works some of the time.
The key word here is that it works nearly perfectly. This tweet was maybe about two-and-a-half years ago and we still don’t really have this technology yet. This is something you’ll come across with every technology cycle, where it works for some use cases, and we think, okay, it’s nearly there, but it might take a little bit more time.
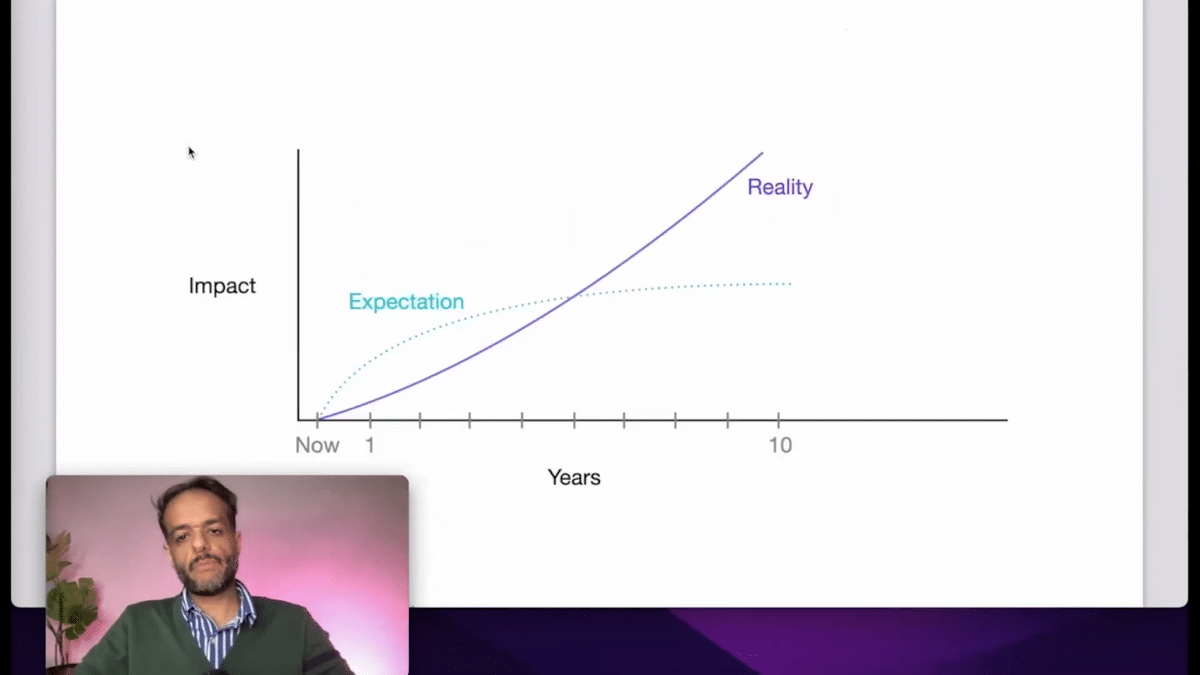
This is paraphrased from a quote by Bill Gates, where, we tend to overestimate how a technology will change the world in one or two years, but then we underestimate what actually ends up changing in the future. That reliability, I think, is one area where we, as an industry, are working to not only build better models but also inform users about the best ways to use these models.

To really safely and responsibly and properly use AI and Generative AI, we need a bunch of things. We need proper playbooks for how to deploy them, and where to deploy them, and what to look out for, and how to evaluate them. These are all research areas that are continuing to be developed, and there are ideas about: how can we ground them? How can we give them better access to information, to even tools? That’s another, sort of, theme.

To talk about language models a little bit here: these models are trained to have language skills. And that’s really the one thing that they’re trained to do.
Their training is basically that we get a lot of text and we use that text to generate examples to train the model. We get all of Wikipedia, we take a sentence of, let’s say, five words from Wikipedia, we give the model four of these words, and we hide the fifth. And we say, “okay, predict what the fifth word would be.” Then it would give us a prediction, and that prediction would be wrong, and we’ll say, “no, you predicted this word, that is not the right answer, this is the right answer. This is the difference between them.” So we update the model to be better at predicting the next word. Do this millions and millions of times, over a large enough dataset, and for a language model that is large enough, and that’s how you create a large GPT model that acquires language skills.

Then, on top of that, we also found that if the model is large enough and the dataset is also large enough, the model learns things beyond language. It also learns a lot of world information, and it learns some reasoning skills that are really surprising in how they emerge just from this language modeling task. Not complete reasoning, but some steps of reasoning that it’s able to do.
A few of the ideas we will touch on here are concepts for how to use these models more effectively to get better results. Ideas like prompt engineering, multi-generation, using these models for data augmentation. Also, we’ll be talking about a couple of interesting integrations of how not to think about a language model as just one thing that you give an input to and get an output out of. It’s useful to think about it as one component in a pipeline of a more intelligent language AI system.
We can think of a language model as this thing that has an input prompt and then it gives you an output. But if you’re thinking about using it as a component to solve problems you shouldn’t restrict yourself to the one output that the model generates.
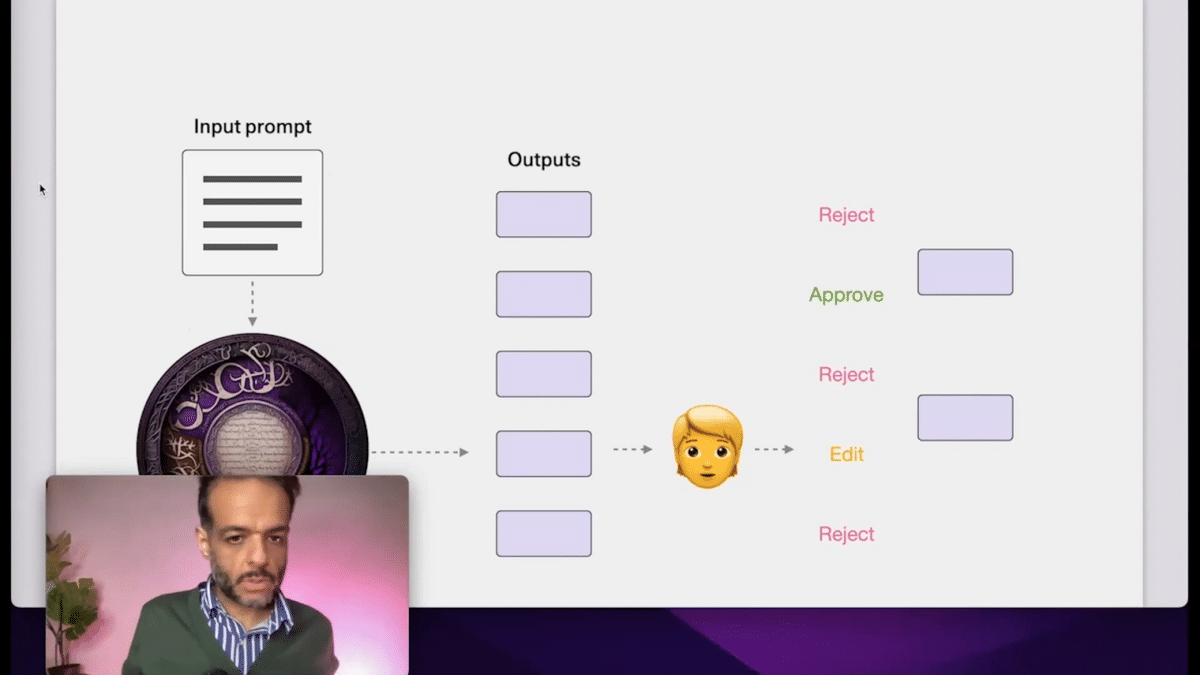
There are a lot of use cases that are improved if you have the model actually generate multiple outputs. Then we can select one of these outputs. We can pass them to a human that rejects a few, approves one, maybe edits one, and that serves as one way to roll out these models and get better results. And there are ways to automate some of these. There are measures of choosing the best output from among the five that the model generated. That would tend to give results better than if you just have the model generate one output and you choose that one.
We have this video by Dr. Rachael Tatman, that you can find on the Cohere YouTube channel, that demonstrates some of this idea about how to use generative language models to build chatbots faster. The idea here is how to use them to augment data to use them to generate training data.

That’s one area where these models are very interesting. These are two works that are exciting, that use large language models to generate training and synthetic data that create better search systems. The method on the left is called Gen-Q, and the one on the right is called InPars. And, there are many other research areas for how to use a generative model to generate data that makes other systems, be they search, or even classification, or even other types of generation models, better.

To touch a little bit on one of these methods, how can it improve a search system? If you’re building a search engine for an archive of documents, you can present the model with a prompt like this, where you have the text of the document and then you generate questions about this document, and that would give you synthetic data that is going to be very useful for you to create a better neural search or semantic search system.
The other concept that is emerging as a new key programming paradigm is this idea of prompt engineering, which is: how do you shape the input prompt to have the model do useful things for you? This is not just for text generation models, but this is also for image generation models. You have to be creative in what keywords you put in and how you use the input prompt and how you use language to nudge the model one way or another in what it creates and what it outputs.
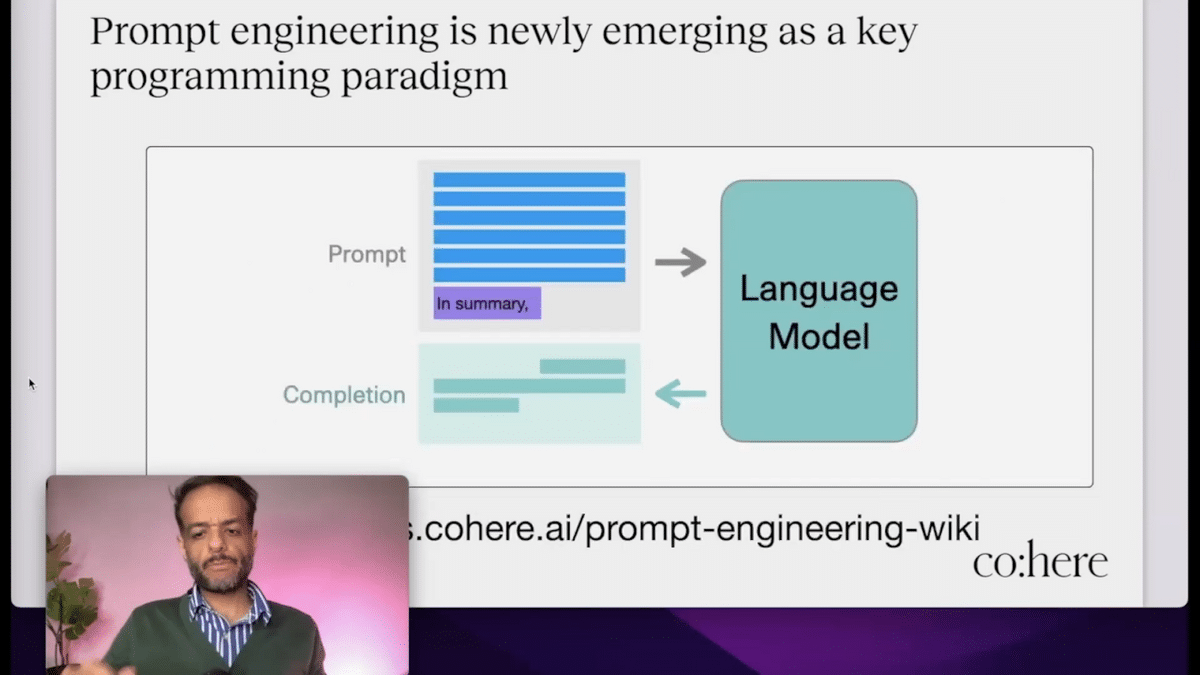
But for text models, you can search for our prompt engineering guide. If you’re working with a generative language model, one of the easiest prompts to give it is to give it a long article and say, “in summary,” and then the model would know that you’re trying to generate a summary out of this and it would generate a summary.
So, this is maybe generation number one. This is the first, let’s say, batch of language models or generative language models. More and more you start to see this other paradigm of instruction or command where you give the model the article and say, “summarize this article.” This is one way where this prompt engineering is evolving as people learn how to better interact or have preferences about how they interact with the model and what they intend to do with the model.

A lot of the time, providing examples of what you want the model to do is beneficial. So, if you issue a command to a model and it doesn’t do what you want it to do, giving a couple of examples tends to be useful and nudges it in the right way. That’s another useful trick for prompt engineering.

A very useful prompt pattern is the list, where you say, “this is a list of x,” and then give it a couple of examples and bullet points, and then you leave the third or fourth bullet point empty, and the model generates this. I use this all the time. It’s super useful. That’s a bunch of prompt engineering for text models. If you’re working with AI image-generation models, different models are prompted in different ways, but there are these ideas of, “okay, do you want an illustration or a photo? Do you want a vector graphic?” These are all useful keywords to put in the prompt. If you want, let’s say, a picture of a person, do you want it to be a close up? Do you want it to be a medium shot? Do you want it to be a long shot? These are all keywords that were relevant in the training of the model, and they can nudge the AI image-generation model to generate more of what you want to see.
Another very important idea, and I think it’s going to be very important this year, is this idea of retrieval-augmented language models. This is where a language model is able to access information beyond what is stored inside of it. This is where you give a language model the ability to access a search engine and search for results or access to a database where it can pull up some information. This is a very favorable thing to do for many reasons.
One is that it’s inefficient for you to store all of that information, all of the world’s information, inside of the parameters of a large language model. You have to deploy all of that to GPU memory when we have perfectly good database systems and software that can deal with all of that. Another thing is that, if everything is stored in the model, you cannot really update the information of the model without retraining the model or training it some more. You have these cutoff dates where the model doesn’t know anything beyond this specific year, while if the model actually had access to an external knowledge source, a database or the web, you can update that information. Or shift it—maybe sometimes you want to create a model that does not talk about our world. Maybe you want it to talk about a specific fictional world where you’re building a chatbot that talks to you about trivia for a specific fantasy world, for example.
So there are use cases where you want more control about what information the model can access. But also, one of the pitfalls of people interacting with language models is expecting them to be able to generate facts. That’s another area where these retrieval-augmented models excel, they can tell you, “this is the fact, and I think that because of this page or this source that it cites.” That’s another really important idea that comes from them.

Then it’s useful to, as we talk, not just think about the model as one thing that you input to and get an output out of. You can think about it more as a system where a language model is only one piece in that pipeline.
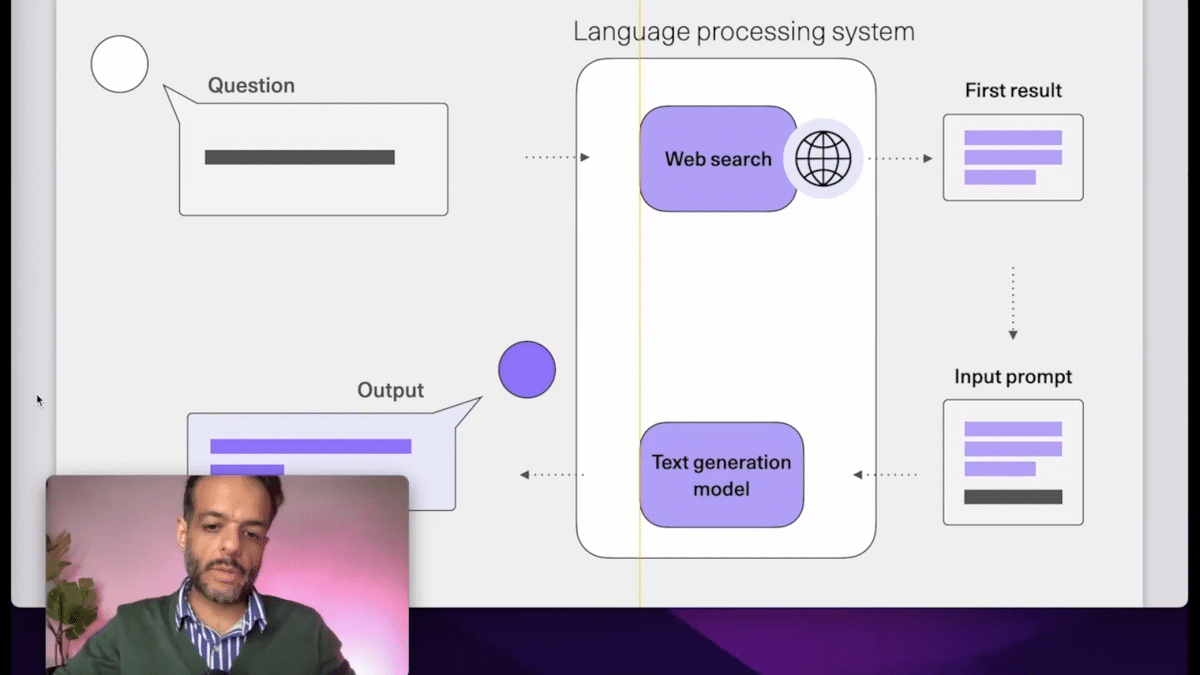
We have an example system here for answering questions, where the model doesn’t just answer the question right away. It actually goes and searches the web, gets the results from the web, puts that into a part of a prompt, and then generates the answer.
We have a full write-up about this system, and we’ve open-sourced it as part of what we call the Cohere Sandbox program. So, we have this discord bot. You can ask it any questions. It’ll go search the web, give you the answer, and also cite to you where it found it. We welcome people to build on top of this and make it their own. This blog post goes into exactly how that system works.

My final point is that “Generative AI,” the term, doesn’t even cover the half of it.
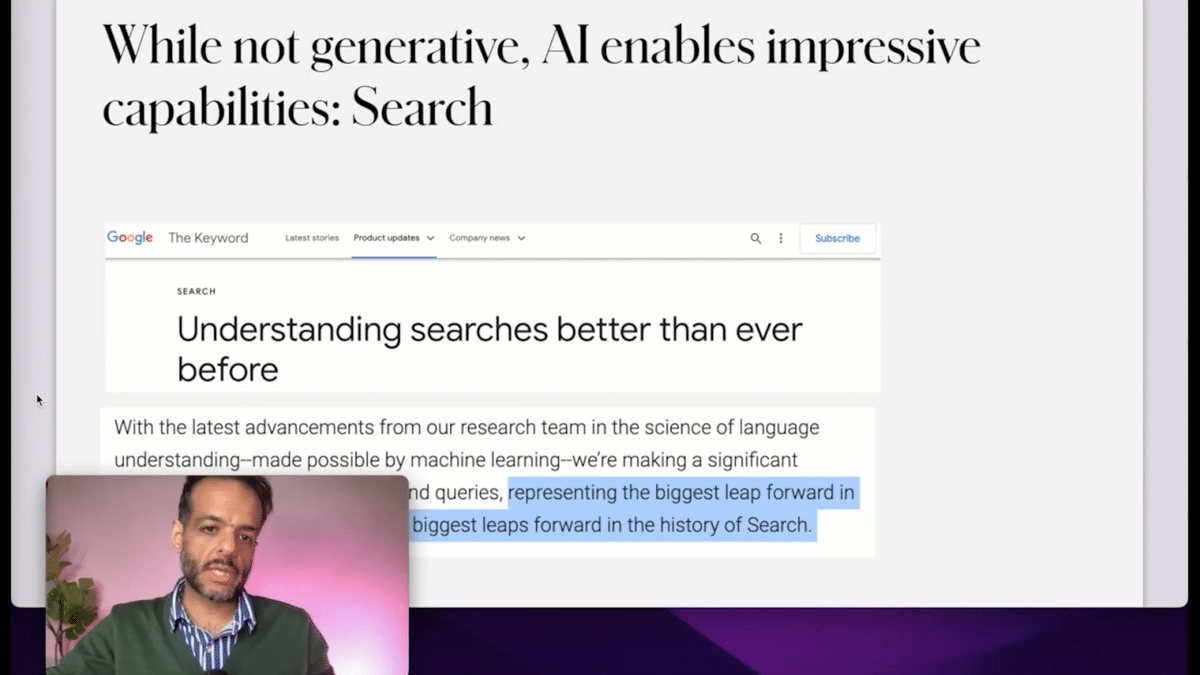
AI empowers really interesting use cases in search, and that is not really a generative capacity. So, when we only talk about Generative AI, we’re not addressing some of the most interesting areas.

Because search is one of them, but then you also have multimodal “image understanding” models. These are image captioning models, and I give them this icon based on these two that we’ve generated previously. These models have been developing in very interesting ways. We had models like this from 2015, but then we have later models that you’re able to actually have dialogue with, and you point them in various directions.
This is a very interesting model from DeepMind called Flamingo, where you give it a picture, it gives you a caption, but you can also have this dialogue with the model and you can use that dialogue to guide the model’s attention to things that are difficult for models typically to focus on.
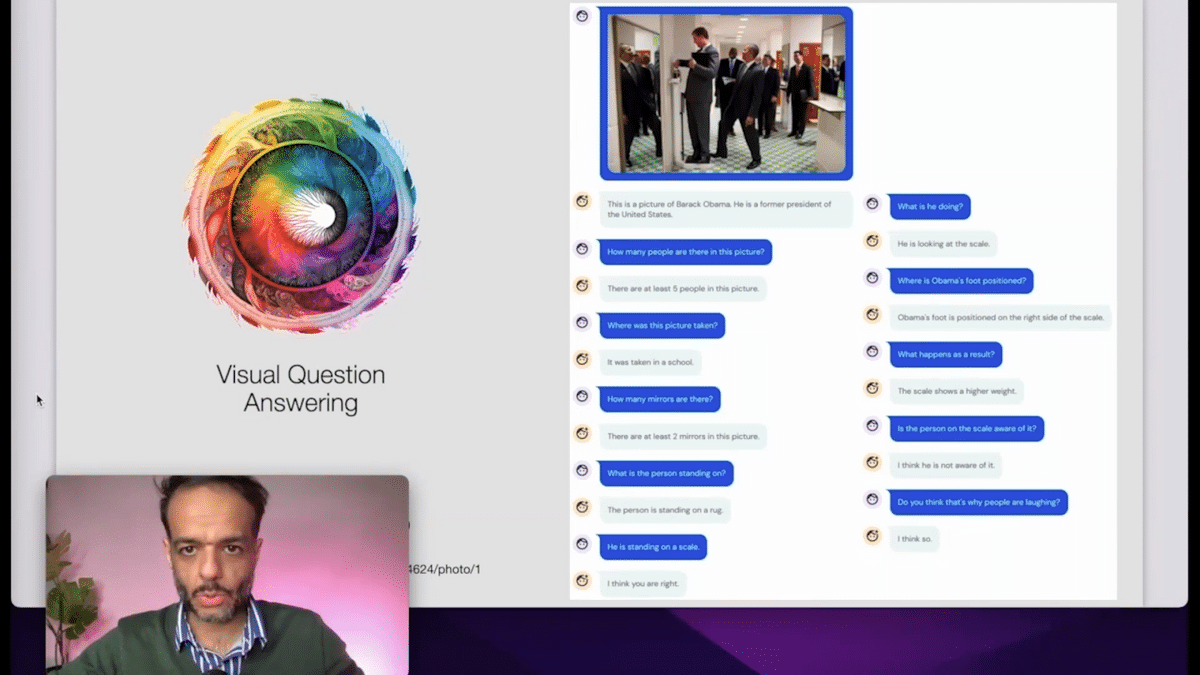
Things like practical jokes, or how many people are in the picture without counting the people that appear in the mirror, for example.
A lot of this is based on this blog post by Andrej Karpathy ten years ago, where he said this image makes him depressed about AI, because the technology at that time was not able to understand these subtleties, and we see really quickly, ten years on, that the technology is catching up.

This is a very quick look at Generative AI: what it is, how it’s impressive, how it’s not reliably impressive yet, and how we need to develop these playbooks. We need to think about how we ground these models for them to give us better results. Then, just on terminology, the term “Generative AI” doesn’t even capture everything that is exciting about the world of AI.

Thank you so much for listening. You can find Cohhere on cohere.ai. We welcome you to join our Discord community. We have a lot of discussions about NLP, and we are always excited to work with people who are building the next generation of language understanding and language generation systems.
I hope you’ve enjoyed this. Thank you so much.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Team Snorkel