Join our inaugural Reading Group in San Francisco on April 29. Register now
Summer 2022 Snorkel Flow release roundup
On the heels of the second annual Future of Data-Centric AI event, we’re energized by what we learned from data scientists, machine learning engineers, and AI leaders who are adopting data-centric approaches to accelerate AI success. The Snorkel Flow platform provides these teams with a seamless workflow across training data creation, model training, and analysis—the scaffolding to make data-centric AI practical and high-impact.
With our summer, we’ve added new data-centric AI capabilities to Snorkel Flow, strengthening our core pillars of rapid data iteration, model-guided error analysis, and domain expert collaboration.
The summer 2022 release delivers new:
- Programmatic labeling options, including auto-generated labeling functions
- Model-based insights and guidance to make development iteration faster
- Error analysis tools to make troubleshooting strategic
- Integrations and workspaces to support enterprise scale
Join us on September 13th for our release webinar to see many of these features in action! For now, let’s dive in.
Powerful programmatic labeling advancements for speed and interpretability
As the pioneers of programmatic labeling, we continue to push the frontiers of this central pillar of data-centric AI—it’s the most scalable, adaptable approach to achieve high-quality training data and unlock high-performing models.
“Data is the foundational element that makes AI/ML shine. It’s the air businesses breathe.”
Erin Babinsky
Data Science Director at Capital One
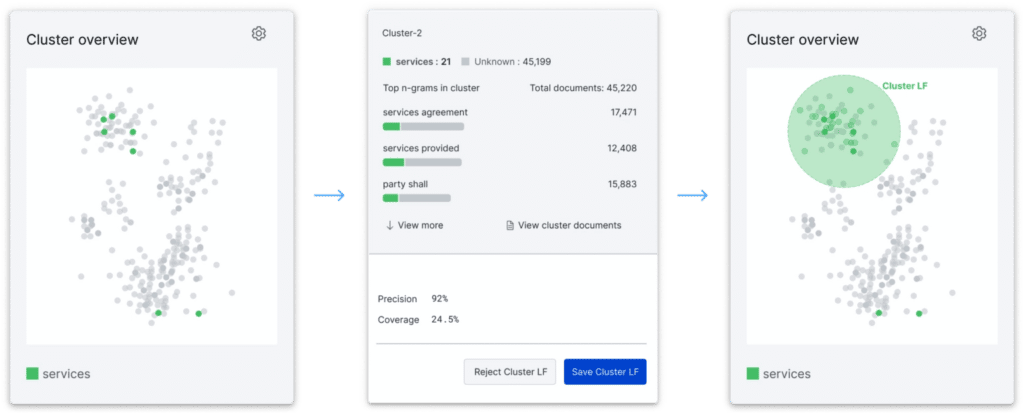
With Cluster View, available in beta as part of New Studio, you can create embeddings with the click of a button; Snorkel Flow will use these to generate clusters to visualize patterns in your data. This is valuable on its own for data exploration. Still, we go further by auto-suggesting Cluster Labeling Functions you can use to jump-start your progress by programmatically labeling all data points within a cluster with the click of a button.
Additional labeling function (LF) enhancements include new LF builder options and structured data rendering improvements to accelerate programmatic labeling even further:
- Multi-polar LFs: Output more than one class with individual LFs to consolidate labeling logic and speed up development for high cardinality use cases (those with many possible classes).
- Custom LF builders: Save custom LFs you write via the Python SDK as GUI-based LF builders to speed workflows for data scientists and domain experts on your team.
- Structured document expression LF builder: Flexibly express nuanced positional and contextual patterns within PDFs and structured data
- Nested tables: Write LFs over structured data more intuitively by viewing data embedded within columns (such as arrays) as nested tables in the Snorkel Flow data viewer.
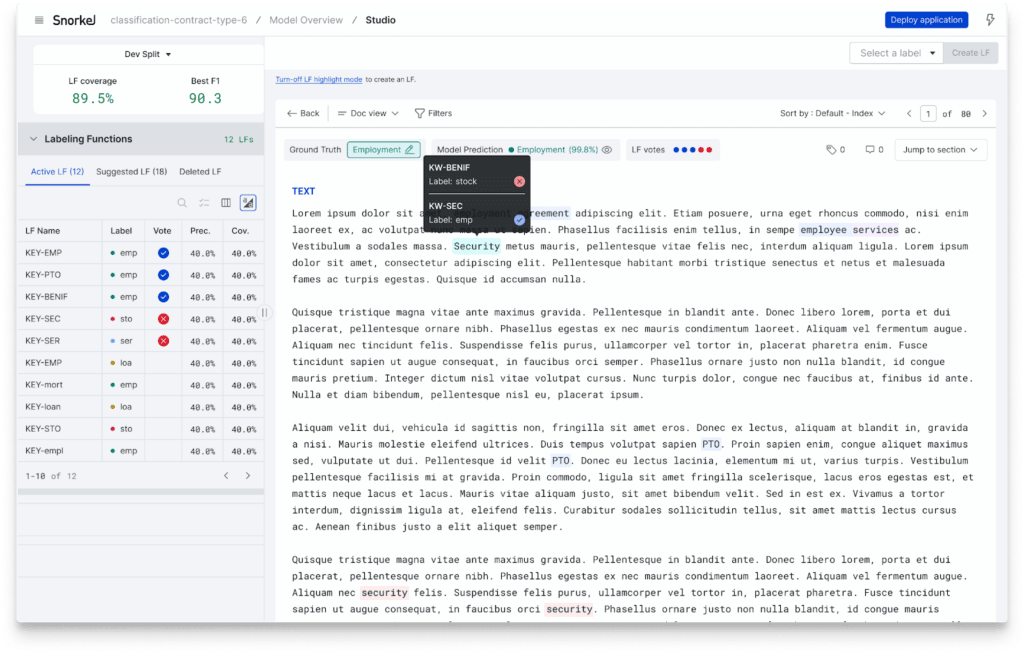
As you label data programmatically in Snorkel Flow, it’s easier to interpret the source of a given training data label. Spot-check documents and troubleshoot using LF highlighting to see which spans triggered any given labeling function to vote for a class. When a ground truth label exists, you can see whether that LF vote was correct. New with this release is improved at-a-glance visualization thanks to LF highlighting over all LFs voting on a given data point at once.
Continuous model feedback to guide rapid iteration
Iterating on your training data and programmatic labeling without integrated model analysis and guidance would be like flying blind. Snorkel Flow integrates model training deeply into the data labeling workflow to provide you with guidance to iterate strategically.
With this release, we’ve updated the new Studio experience (available for opt-in) to make this insight more streamlined and faster.
- Fast Train: Automated, real-time quality feedback from a faster ML model as you write labeling functions shows your progress to signal when to train a full model to insights.
- Persistent performance: Your latest LF coverage and best model score are anchored to your workspace, showing how each action you take impacts results and whether you’ve reached your training data quality and model performance goals.

Actionable data quality insights
Knowing where your training data needs improvement is powerful, but knowing exactly how to improve it—including automated improvements you can make with a single click—is where the real workflow acceleration happens.
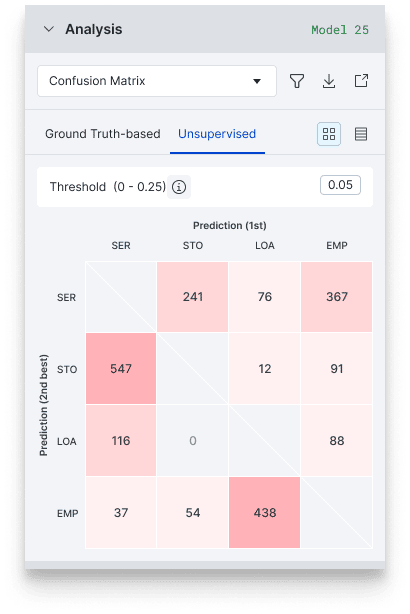
Unsupervised Confusion Matrix, a new analysis tool in Snorkel Flow, supports users who want to dive into a new project and write labeling functions before they’ve hand-labeled any ground truth, including validation data. Until now, this would mean they could not analyze the quality of the resulting labeled training data. Still, the Unsupervised Confusion Matrix uses probabilistic outputs calculated under the hood—no ground truth required! As with the standard ground truth-based confusion matrix, you can click directly into buckets of the data where the model is most confused to iterate.
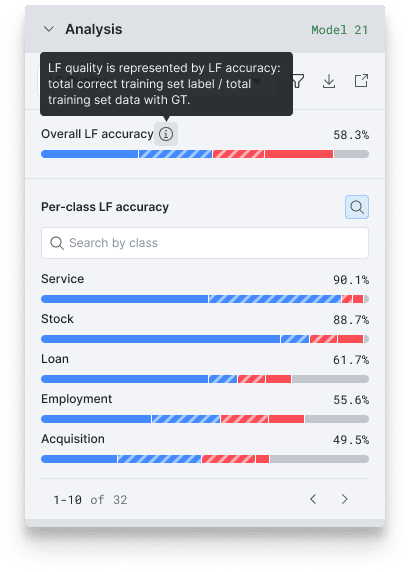
As you write Labeling Functions (LFs) in Snorkel Flow, we now provide you with aggregated LF accuracy and coverage analysis. See how you’re doing against your dataset overall and per class for all data with ground truth labels. Seeing where your LFs are all voting correctly, where they conflict, and where you lack coverage is yet another source of guidance as to your next best action.
Strategic collaboration and troubleshooting
Collaboration is core to data-centric AI—it’s why Snorkel Flow provides a first-class experience for data scientists and the domain experts they partner with. This includes Annotation Suite (used to label and QA ground truth data) and tagging workflows (critical interfaces for data scientists and domain experts to accelerate iteration and troubleshooting).
Recent improvements to Annotation Suite include:
- Sequence tagging annotation: Drag-and-click workflows streamline tagging spans across unstructured text.
- PDF search and zoom: Jump to keywords within long, complex documents using hot-keys and zoom into PDF data for easier review and efficient annotation.
- Data filtering: Review data by inter-annotator agreement within a batch or class or by specific annotators assigned to a particular batch.
As you review error modes in your data in Snorkel Flow, tagging data is a powerful way to surface the most impactful errors to address first. Often, tagging is best done with your subject matter experts, who can use the GUI to tag data themselves or label slices of tagged data you send them.
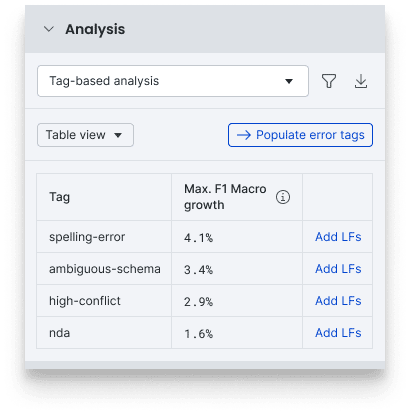
Here are some useful improvements to tag-based workflows and insights in this release.
- Filter-to-tag: In the New Studio experience, you can query data to display relevant documents and tag many at once, for instance, if you’ve noticed a typo that’s driving model confusion.
- Auto-generated LFs: Add auto-suggested labeling functions (with estimated F1 macro impact) to improve the data quality within a given tag bucket.
- Better charting: Displays all documents you’ve tagged with color-coding to show whether tagged is corrected as you iterate.
Enhancements for enterprise scale
As your team grows in size, skill, and complexity of use cases, your platform needs to support your maturing needs. With this release, Snorkel Flow now offers Workspaces to separate users, data, and applications across a single installation and upgraded notebook support to use JupyterHub to give users individualized notebook instances that isolate data and resource use while improving audit capabilities).
Several new capabilities within the summer 2022 release speed first- and last-mile workflows, letting you onboard new datasets and deploy models faster.
- Data ingest integrations: Built-in connectors to pull data directly from Snowflake and SQL databases.
- Data-prep support: Optimized in-app shuffling and splitting automate the creation of training, validation, and test sets to jump-start application building.
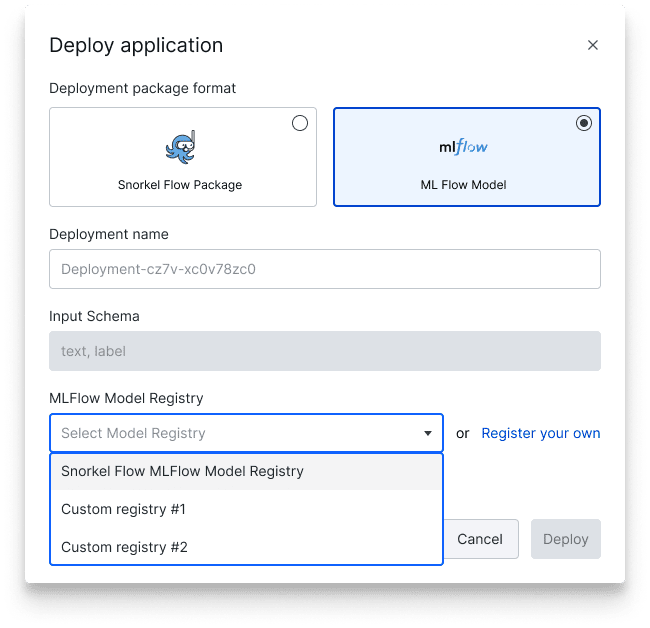
- Improved MLflow integration: Use the GUI-based MLflow connector to register existing MLflow registries with Snorkel Flow and deploy to any environment that supports MLflow packages.
Finally, because innovation should never come at the cost of performance, we’ve made back-end improvements to memory efficiency yielding better stability and scalability, up to 5x faster dataset search and resampling, and up to 4x faster application copy performance to improve productivity when sharing or building on existing work.
This release delivers more value across the entire data-centric AI workflow, inspired by the learnings from our users as well as research carried out by our team. To see Snorkel Flow in action, join the Summer Release webinar on September 13th!

Molly Friederich
Molly leads the product marketing team at Snorkel AI, partnering closely with cross-functional teams to bring the value of data-centric AI to AI/ML teams.
Prior to Snorkel AI, she spent nearly six years at SendGrid and Twilio, supporting organizations' ability to engage customers using email APIs and marketing software.