Join our inaugural Reading Group in San Francisco on April 29. Register now
Spring 2022 Snorkel Flow release roundup
Latest features and platform improvements for Snorkel Flow
2022 is off to a strong start as we continue to make the benefits of data-centric AI more accessible to the enterprise. With this release, we’re further empowering AI/ML teams to drive rapid, analysis-driven training data iteration and development. Improvements include streamlined data exploration and programmatic labeling workflows, integrated active learning and AutoML, utilities for complex data types, and more.
Enterprises such as BNY Mellon, Genentech, Memorial Sloan Kettering Cancer Center, Orange, and others in the Fortune 500 are adopting data-centric AI with Snorkel Flow to accelerate AI development by 10-100x. We recently also announced that Snorkel Flow is now generally available.
Ready to see Snorkel Flow in action? Join us on April 27th for a live demo.
Power your data-centric workflows with instant, guided feedback [beta]
Making more AI development workflows data-centric is a top priority. In Q1 we continued to build on our revamped Studio experience that brings data exploration, programmatic labeling, model training, and model analysis into a single interface. Enhancements include:
- Immediate quality feedback for labeling functions: The new search-based query language makes it faster to write labeling functions that capture heuristics at scale with programmatic labeling. Now you have instant insight into the coverage (including incremental coverage) and precision of each function as you write it. You also receive explicit suggestions to improve, so you’re being coached as you go.
- Faster model-based feedback on training sets: Iteration is key for successful, data-centric AI, but iterating without guidance is like shooting in the dark. Snorkel Flow provides model-guided error analysis as a core part of our workflow, and now we’ve gone a step further by automatically training a real-time model for you to provide performance feedback as you iterate on your training data labeling.
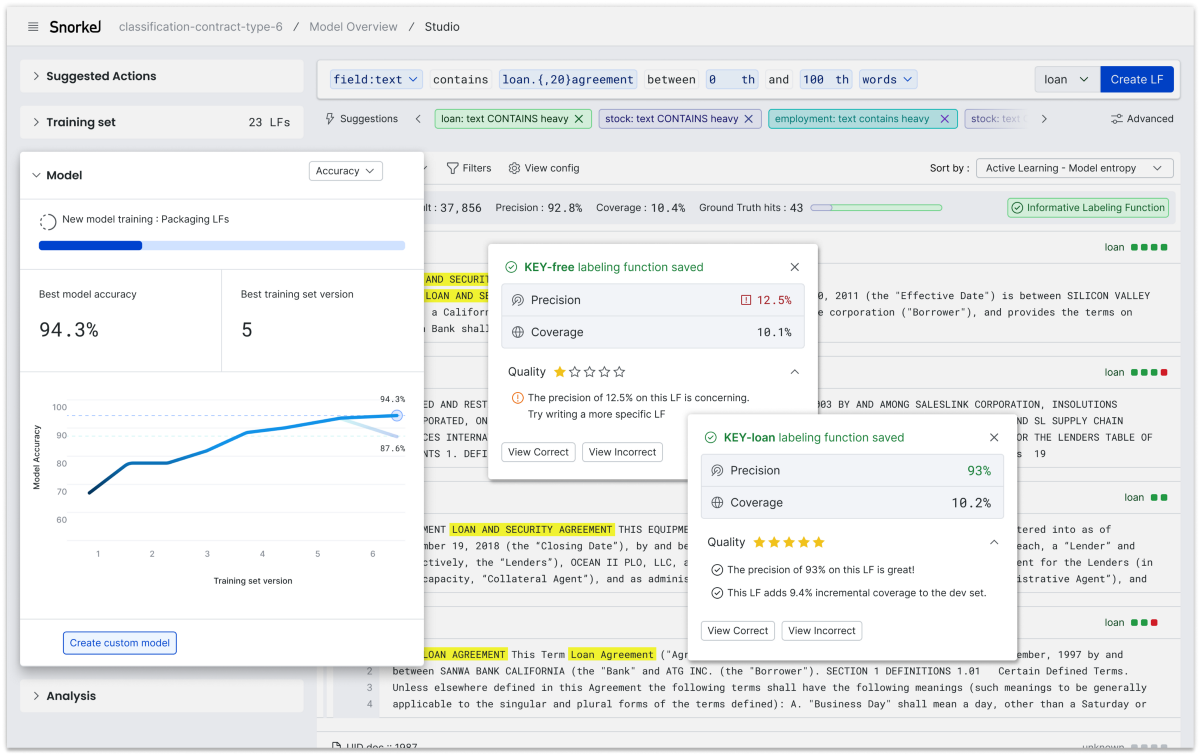
This builds on the capabilities released in Q4 including accelerated labeling function creation and guided error analysis within the Studio interface. The new Studio experience is currently available for all customers building document classification applications.
Pair active learning with programmatic labeling in-platform for amplified impact
Active learning is a machine learning technique to optimize the labeling process by prioritizing the data points your model is least certain about to be labeled first. Typical active learning workflows still require you to manually label vast numbers of data points. In Snorkel Flow, because active learning is coupled with programmatic labeling, users can see a 10-100x acceleration. In the new Studio experience (beta), we’ve made it easier to view and sort by current model confidence as you develop labeling functions, making programmatic active learning a first-class workflow.
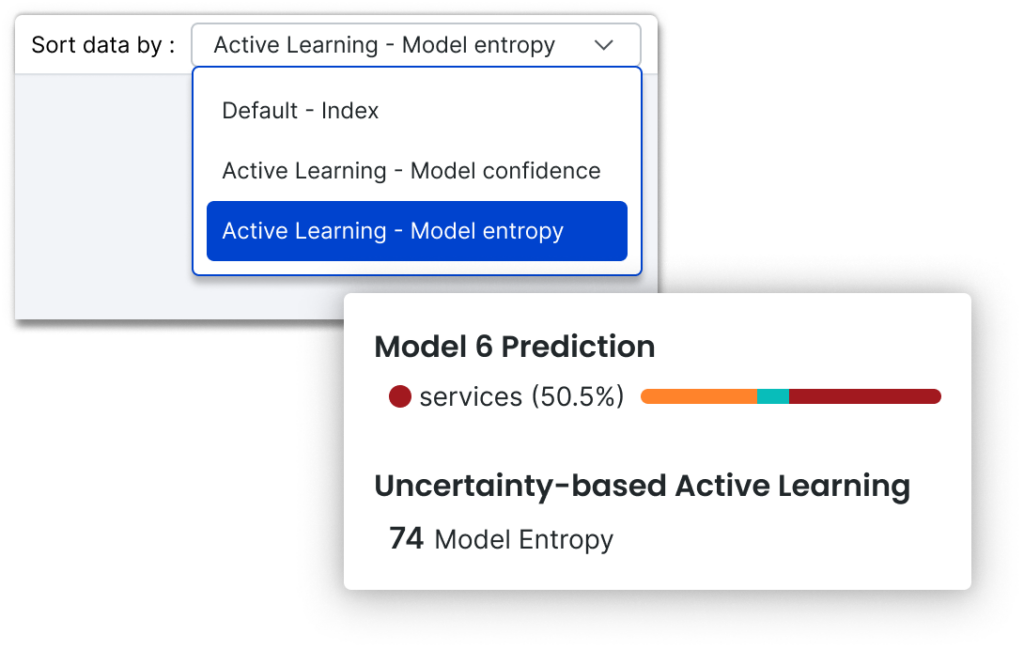
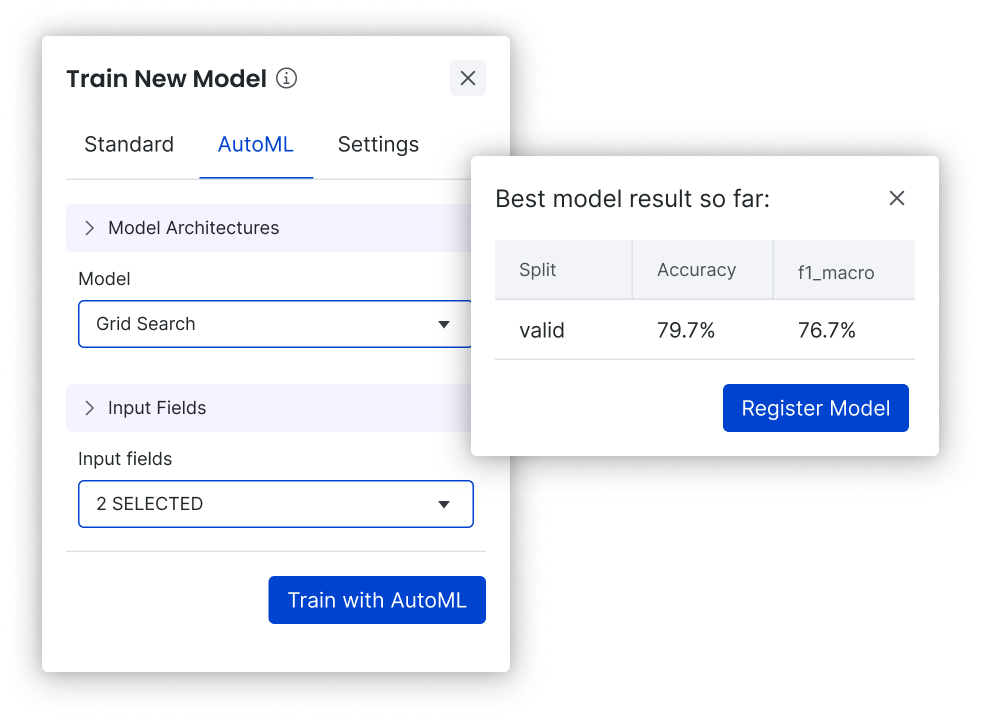
Let AutoML optimize your architecture without stalling your data development
Snorkel Flow’s AutoML suite, introduced in our last release, is a powerful way to explore a variety of architectures with the push of a button to efficiently find a high-performing model with appropriately tuned hyper-parameters. Not only does this save time for data scientists and machine learning engineers, it allows users with little ML knowledge to train models effectively.
With this release, we’ve made the AutoML experience more efficient by showing you the best-performing model found so far during the AutoML process. You can choose to register a given model (even as AutoML continues in the background) and use it to guide iteration on your labeling functions. This means you’re never stalled while the job runs. AutoML is available across all ML task types, including document classification, information extraction, conversational analysis, and more.
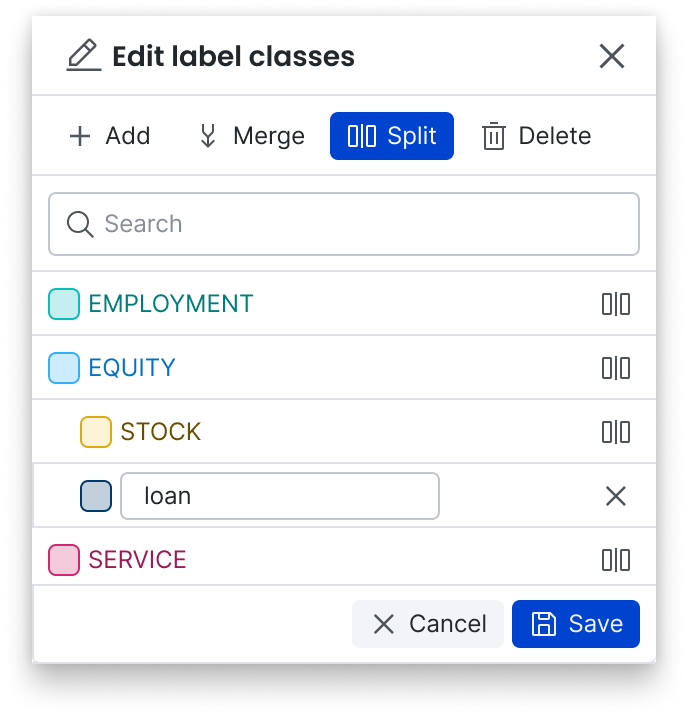
Respond seamlessly to real-world label schema updates with in-context editing
A core advantage of Snorkel Flow’s programmatic labeling technology is adaptability. As your AI applications face inevitable production data and business objective changes, you can easily modify label classes and adapt training data in response. With this release, we’ve made this workflow even easier; you can rename existing classes, add new classes, remove classes, merge classes, and split classes, all from within Studio. From there, simply update a handful of labeling functions to regenerate your training data in minutes rather than completely relabeling manually over weeks or months.
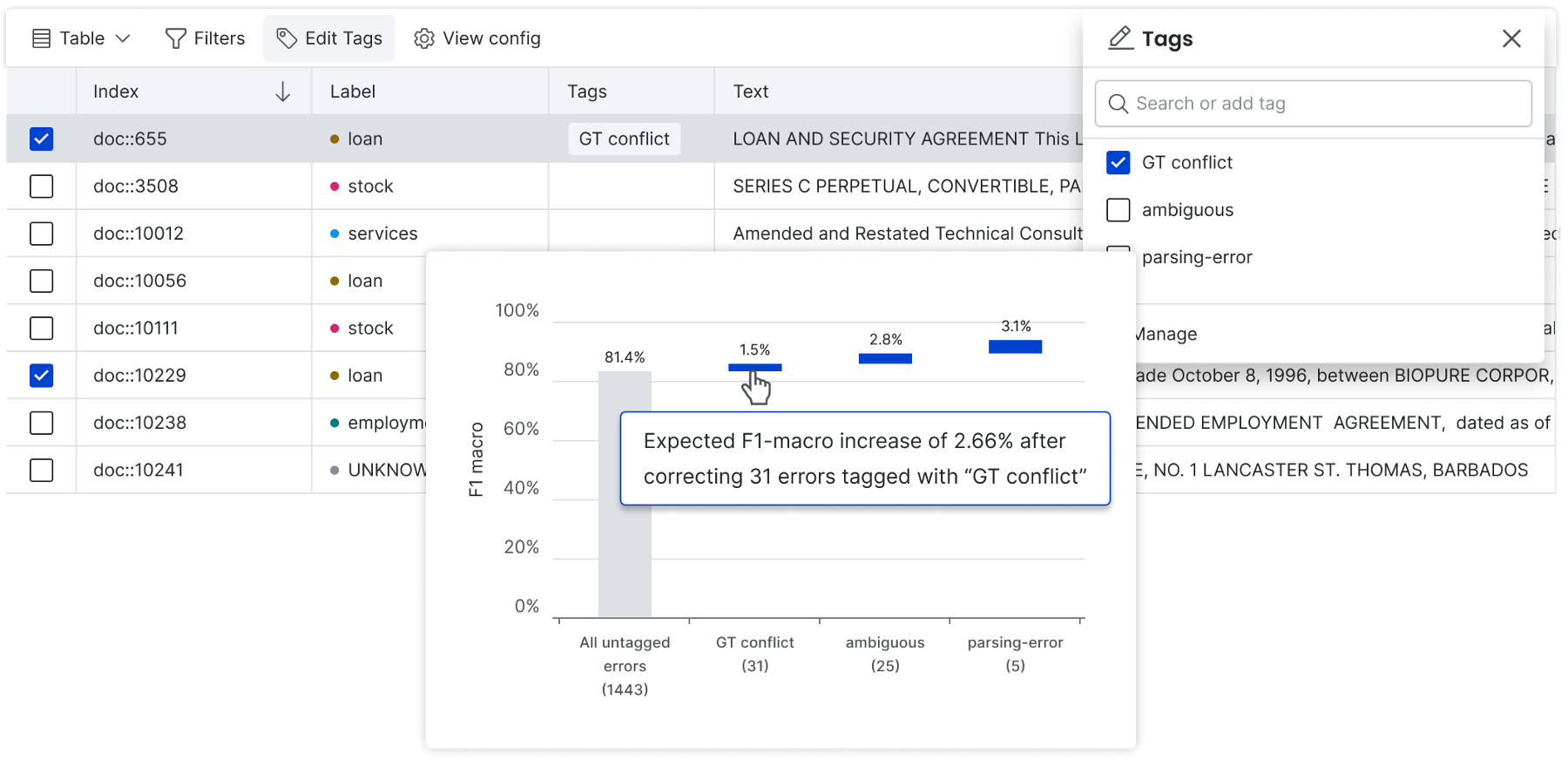
Action on error insights faster with improved tagging and analysis
Understanding where errors are occurring and their impact to overall model performance is critical–and most often these errors can be traced back to the training data. Snorkel Flow guides you to the slices of the training data causing errors and makes it easy to tag data points with information about the error, including when your ground truth may actually be incorrect (this is especially a risk when QA on ground truth labeling is limited).
Now, the tagging workflow is even faster with the ability to multi-select data for tagging in Studio’s table view. As you create tags, Snorkel Flow automatically creates visualizations for you that summarize the prevalence of different tags, making it easy to spot those having the highest impact to performance, take action, and share this information with stakeholders, including the domain experts you collaborate with.
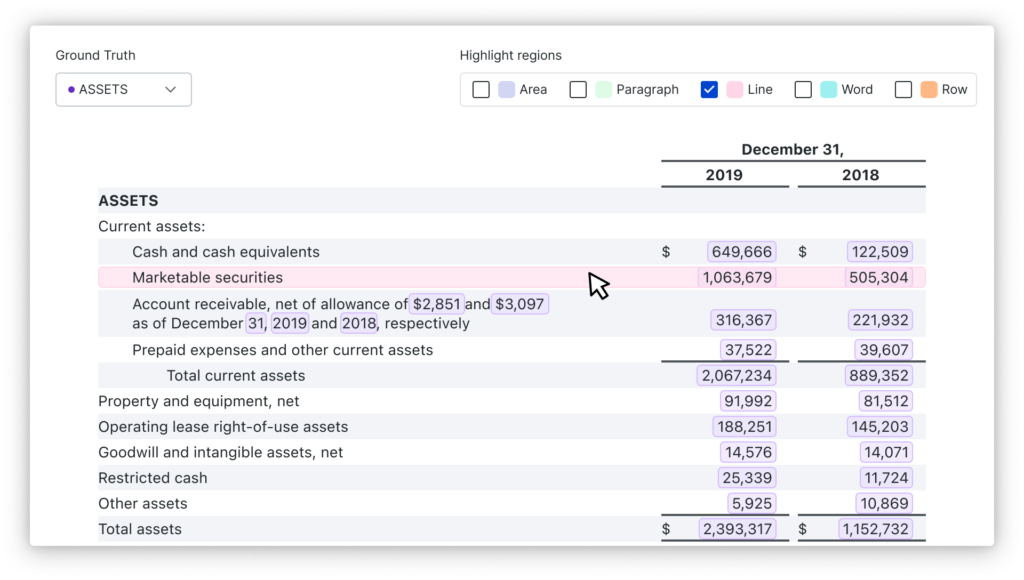
Unlock data within PDF documents with built-in utilities
Real-world AI development entails processing complex, messy data; a prime example is data contained within PDFs. Building on a suite of features that make working with PDFs easier, we’ve shipped a number of new capabilities in Q1. These include highlight options to visualize particular regions like lines or words, new labeling function builders with improved UX for regex patterns over rows and surrounding areas, and page splitting and page filtering preprocessors to target specific pages within PDF documents and speed processing. These built-in utilities reduce the overhead for data science teams to unlock the data within these PDFs.
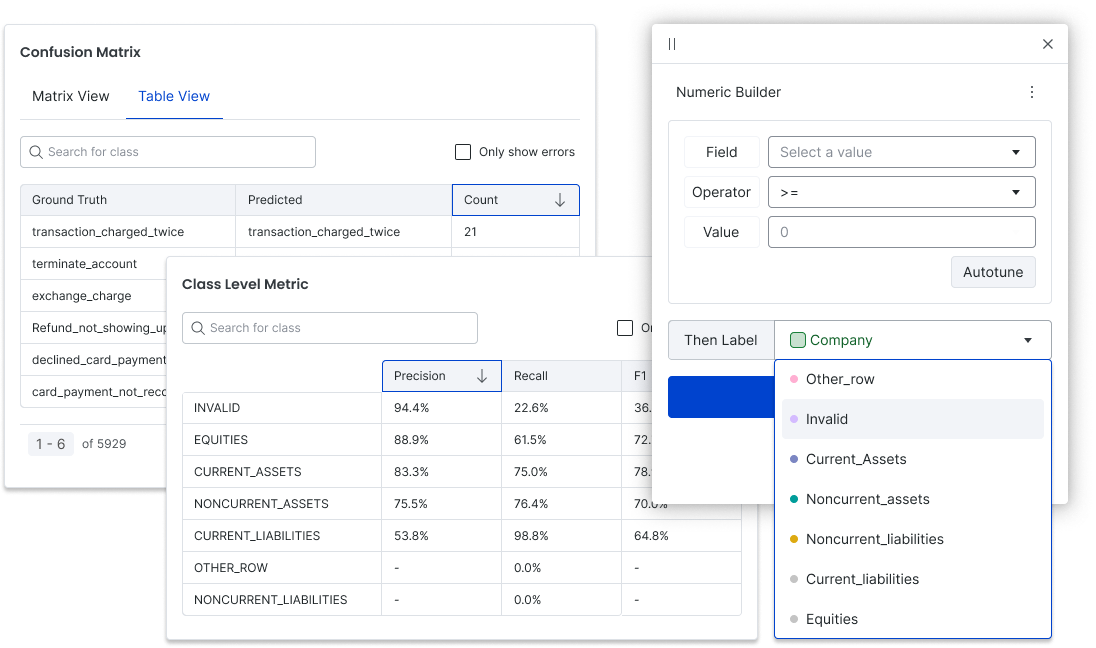
Tackle high cardinality problems with streamlined workflows
Another real-world source of complexity for AI/ML problems is when classification or extraction tasks entail a large number of possible classes or targets. We delivered a number of UX enhancements in Q1 to support high-cardinality development (cases where there are hundreds of possible classes or more) including the ability to search for classes when creating labeling functions and adding ground truth labels, search and sort options within class-level metrics, and a sorted tabular view within the confusion matrix.
The value delivered with this release further accelerates AI development for the AI/ML teams who use Snorkel Flow today. If you’re ready to see the platform in action, join us on April 27th for a live demo of Snorkel Flow, including these recent additions.

Molly Friederich
Molly leads the product marketing team at Snorkel AI, partnering closely with cross-functional teams to bring the value of data-centric AI to AI/ML teams.
Prior to Snorkel AI, she spent nearly six years at SendGrid and Twilio, supporting organizations' ability to engage customers using email APIs and marketing software.