Search result for:
All Topics
Latest posts
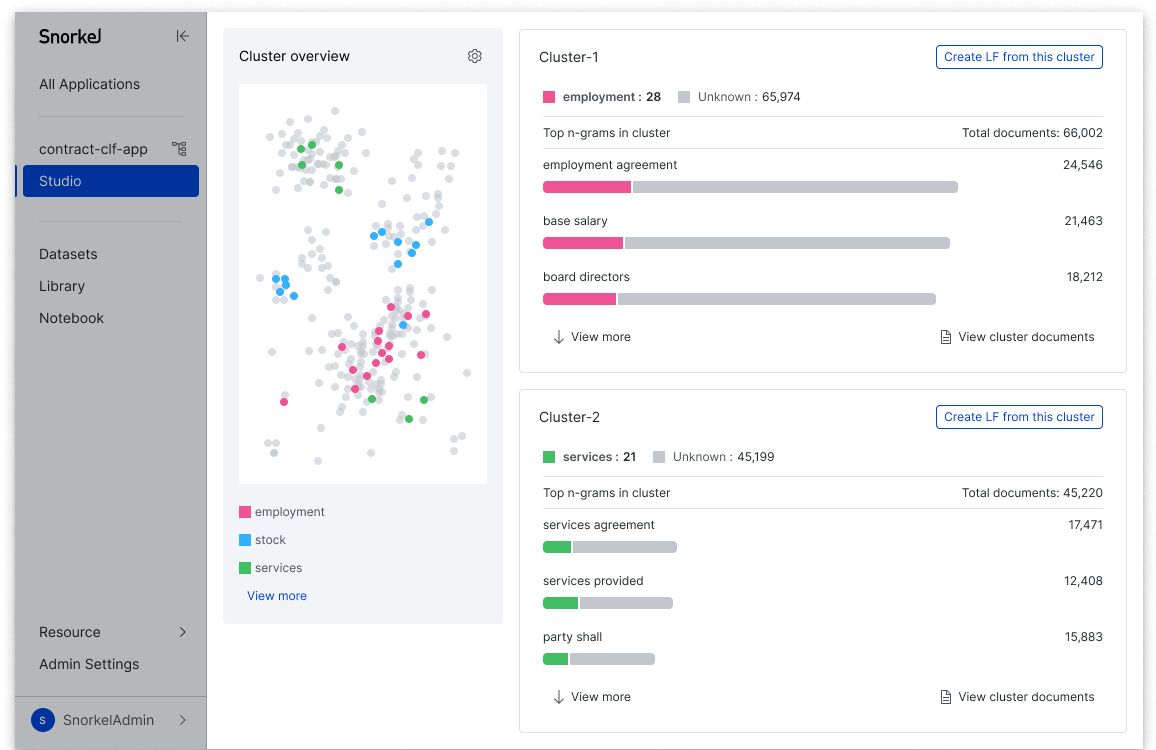
Introducing Cluster View: Instant data insight made actionable to speed AI development
Programmatic labeling moves a classic technique from interesting to high-impact So much of real-world AI development entails working with text data that’s messy — in fact, 80%+ of enterprise data is unstructured. And while state-of-the-art models get a lot of the glory, creating the training data that conveys what your model needs to learn is more often the biggest determiner of AI…


Data-centric approaches to multi-label classification
AI systems are well-suited to tasks involving recognizing and predicting data patterns. Supervised classification systems categorize unseen data into a finite set of discrete classes by learning from millions of hand-labeled labeled sample points. These classifiers are powerful business tools – they automate document sorting, customer sentiment analysis, sales performance, and other distinct business problems. However, they also require an…


Data annotation guidelines and best practices
What is data annotation? Data annotation refers to the process of categorizing and labeling data for training datasets. This process plays a critical role in preparing data for machine learning models, as high-quality training data enables more accurate predictions and insights. In order for a training dataset to be usable, it must be categorized appropriately and annotated for a specific…

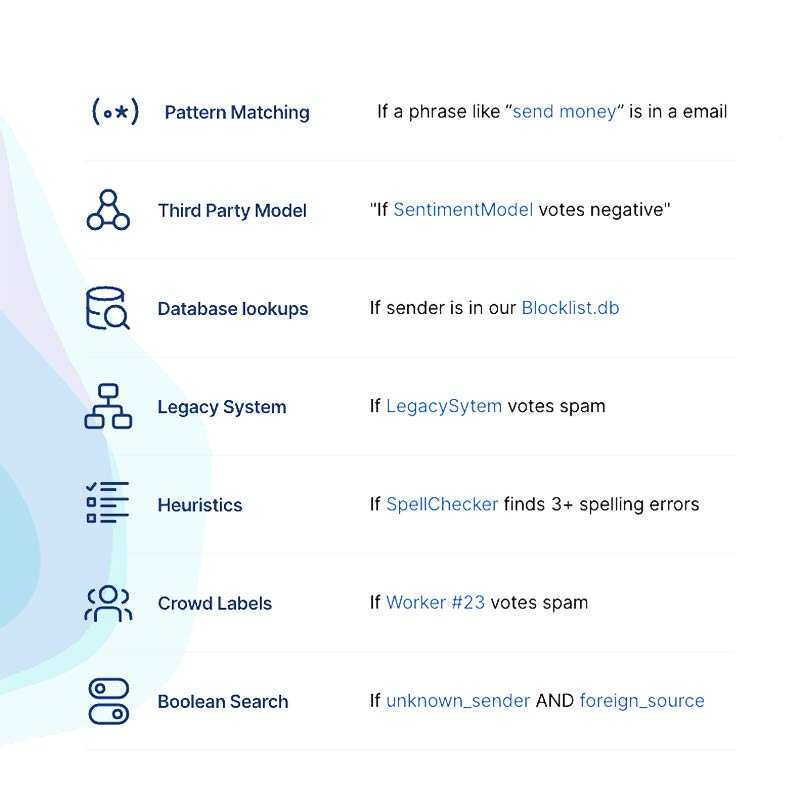
3 ways to use Snorkel’s Labeling Functions
Labeling functions are fundamental building blocks of programmatic labeling that encode diverse sources of weak labeling signals to produce high-quality labeled data at scale. Let’s start with the core motivation for labeling functions: over time, every major commercial organization and government agency builds various valuable, often bespoke knowledge resources. These resources include employee expertise, wikis and ontologies, business logic, and…


Clinical entity classification in electronic health records
Research recap: Ontology-driven weak supervision for clinical entity classification in electronic health records (EHRs) In this post, I have summarized the research published in this academic paper, Ontology-driven weak supervision for clinical entity classification in electronic health records by Jason Fries et al. This paper was published in Nature Communications in 2021.Problem statement Electronic health records (EHR) contain a rich…


Building AI models for financial document processing best practices
Highlighting the best practices for building and deploying AI models for financial document processing applications AI has massive potential in the financial industry. Building AI models to automate information extraction, fraud detection, and compliance monitoring can provide efficient and faster responses and support repurposing domain experts’ labor to more meaningful tasks. Developing AI models is not just about having models…


The benefits of programmatic labeling for trustworthy AI
The following post is based on a talk discussing the benefits of programmatic labeling for trustworthy AI, which was presented as part of the Trustworthy AI: A Practical Roadmap for Government event that took place this past April, with Snorkel AI Co-founder and Head of Technology, Braden Hancock. If you would like to watch Braden’s presentation, we have included it…


Uncovering the unknowns of deep neural networks by Sharon Li
Learning about the challenges and opportunities behind deep neural networks In this talk, Assistant Professor in Computer Science Sharon Li shares some exciting work about uncovering the unknowns of deep neural networks. She also shares some exciting challenges and opportunities in this domain. If you would like to watch Sharon’s presentation, we have included it below, or you can find…
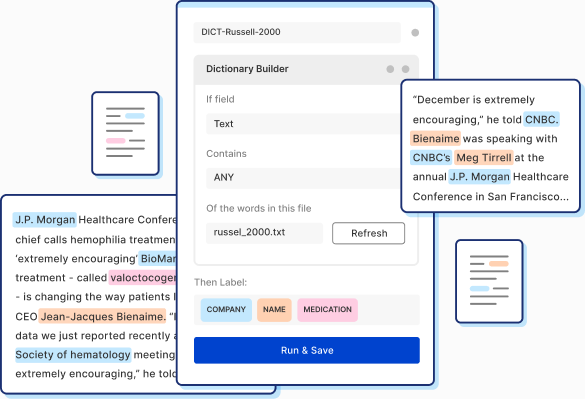
Named entity extraction and recognition with Snorkel Flow
If you were ever amazed at how Google accurately finds the answer to your question just by a few keywords, you’ve witnessed the power of named entity recognition (NER). By quickly and accurately identifying different entities in a sea of unstructured articles, like names of people, places, and organizations, the search engine can figure out each article’s main topics and…


A data-centric perspective on trustworthy and interpretable AI
The future of data-centric AI talk series In this talk, Assistant Professor of Biomedical Data Science at Stanford University, James Zou, discusses the work he and his team have been doing from a data-centric perspective to trustworthy and interpretable AI. If you would like to watch James’ presentation, we have included it below, or you can find the entire event…

Government keynote presentation by FBI CTO Gregory Ihrie
Gregory Ihrie is the Chief Technology Officer for the FBI, responsible for technology, innovation, and strategy. He also leads the FBI’s efforts in advancing the bureau’s management, policy, and governance of AI systems. Ihrie chairs the FBI’s Scientific Working Group on Artificial Intelligence, as well as the Department of Justice’s AI Committee of Interest. He is one of three officers…

MLOps: Towards DevOps for data-centric AI with Ce Zhang
The future of data-centric AI talk series Don’t miss the opportunity to gain an in-depth understanding of data-centric AI and learn best practices from real-world implementations. Connect with fellow data scientists, machine learning engineers, and AI leaders from academia and industry with over 30 virtual sessions. Save your seat at The Future of Data-Centric AI. Happening on August 3-4, 2022….

What to expect at The Future of Data-Centric AI 2022
30+ sessions by 40+ speakers in 2 action-packed days Last year we organized The Future of Data-Centric AI conference to explore the shift from model-centric to data-centric AI. Speakers included researchers and industry experts such as Andrew Ng (Landing AI), Anima Anandkumar (NVIDIA), Chris Re (Stanford AI Lab), Michael DAndrea (Genentech), Skip McCormick (BNY Mellon), Imen Grida Ben Yahia (Orange)…


Auto LF generation: Lots of little models, big benefits
Constructing labeling functions (LFs) is at the heart of using weak supervision. We often think of these labeling functions as programmatic expressions of domain expertise or heuristics. Indeed, much of the advantage of weak supervision is that we can save time—writing labeling functions and applying them to data at scale is much more efficient compared to hand-labeling huge numbers of…


Building a COVID fact-checking system with external knowledge
Powerful resources to leverage as labeling functions In this post, we’ll use the COVID-FACT dataset to demonstrate how to use existing resources as labeling functions (LFs), to build a fact-checking system. The COVID-FACT dataset contains 4086 claims about the COVID-19 pandemic; it contains claims, evidence for the claims, and contradictory claims refuted by the evidence. The evidence retrieval is formulated…


Snorkel AI FAQ
Browse through these FAQ to find answers to commonly raised questions about Snorkel AI, Snorkel Flow, and data-centric AI development. Have more questions? Contact us. Programmatic labeling Use cases 1. What is a labeling function? A Labeling Function (LF) is an arbitrary function that takes in a data point and outputs a proposed label or abstains. The logic used to…

Panel discussion: Academic and industry perspectives on ethical AI
This post showcases a panel discussion on the academic and industry perspectives of ethical AI, which was moderated by Director of Federal Strategy and Growth, Alexis Zumwalt, Fouts Family Early Career Professor and Lead of Ethical AI (NSF AI Institute AI4OPT), Georgia Institute of Technology, Swati Gupta, Chief Data Officer, Department of the Navy, Thomas Sasalsa, Senior Manager of Responsible…

Event recap: Adopting trustworthy AI for government
We’re currently experiencing such a rapid AI revolution and adoption of technologies, ranging from autonomous cars to virtual assistants and robotic surgeries and so much more, making it challenging for our government agencies to keep up. Especially when adding AI technologies to the mix, it can be even harder to manage.The crucial adoption of trustworthy AI and its successful integration…


Programmatic labeling
The founding team of Snorkel AI has spent over half a decade—first at the Stanford AI Lab and now at Snorkel AI—researching programmatic labeling and other techniques for breaking through the biggest bottleneck in AI: the lack of labeled training data. This research has resulted in the Snorkel research project and 150+ peer-reviewed publications. Snorkel’s programmatic labeling technology has been…
Weak supervision
The founding team of Snorkel AI has spent over half a decade—first at the Stanford AI Lab and now at Snorkel AI—researching weak supervision (WS) and other techniques for breaking through the biggest bottleneck in AI: the lack of labeled training data. This research has resulted in the Snorkel research project and 150+ peer-reviewed publications. Snorkel’s technology which applies weak…
Data-centric AI: A complete primer
The founding team of Snorkel AI has spent over half a decade—first at the Stanford AI Lab and now at Snorkel AI—researching data-centric techniques to overcome the biggest bottleneck in AI: The lack of labeled training data. In this video Snorkel AI co-founder Paroma Varma gives an overview of the key principles of data-centric AI development. What is data-centric AI?…
Data extraction from SEC filings (10-Ks) with Snorkel Flow
Leveraging Snorkel Flow to extract critical data from annual quarterly reports (10-Ks) Introduction It can surprise those who have never logged into EDGAR how much information is available in annual reports from public companies. You can find tactical details like the names of senior leadership, top shareholders, and more strategic information like earnings, risk factors, and the company strategy and vision. Warren…

Liger: Fusing foundation model embeddings & weak supervision
Showcasing Liger—a combination of foundation model embeddings to improve weak supervision techniques. Machine learning whiteboard (MLW) open-source series In this talk, Mayee Chen, a PhD student in Computer Science at Stanford University focuses on her work combining weak supervision and foundation model embeddings that improve two essential aspects of current weak supervision techniques. Check out the full episode here or…
AI in cybersecurity an introduction and case studies
An introduction to AI in cybersecurity with real-world case studies in a Fortune 500 organization and a government agency Despite all the recent advances in artificial intelligence and machine learning (AI/ML) applied to a vast array of application areas and use cases, success in AI in cybersecurity remains elusive. The key component to building AI/ML applications is training data, which…
Active learning: an overview
A primer on active learning presented by Josh McGrath. Machine learning whiteboard (MLW) open-source series This video defines active learning, explores variants and design decisions made within active learning pipelines, and compares it to related methods. It contains references to some seminal papers in machine learning that we find instructive. Check out the full video below or on Youtube. Additionally, a…

Using few-shot learning language models as weak supervision
Utilizing large language models as zero-shot and few-shot learners with Snorkel for better quality and more flexibility Large language models (LLMs) such as BERT, T5, GPT-3, and others are exceptional resources for applying general knowledge to your specific problem. Being able to frame a new task as a question for a language model (zero-shot learning), or showing it a few…


Accelerating AI in healthcare
How can data-centric AI speeds your end-to-end healthcare AI development and deployment Healthcare is a field that is awash in data, and managing it all is complicated and expensive. As an industry, it benefits tremendously from the ongoing development of machine learning and data-centric AI. The potential benefits of AI integration in healthcare can be broken down into two categories:…

Bill of materials for responsible AI: collaborative labeling
In our previous posts, we discussed how explainable AI is crucial to ensure the transparency and auditability of your AI deployments and how trustworthy AI adoption and its successful integration into our country’s critical infrastructure and systems are paramount. In this post, we dive into making trustworthy and responsible AI possible with Snorkel Flow, the data-centric AI platform for government and federal agencies. Collaborative labeling and…

ICLR 2022 recap from Snorkel AI
We are honored to be part of the International Conference on Learning Representations (ICLR) 2022, where Snorkel AI founders and researchers will be presenting five papers on data-centric AI topics The field of artificial intelligence moves fast! This is a world we are intimately familiar with at Snorkel AI, having spun out of academia in 2019. For over half a…


Explainability through provenance and lineage
In our previous post, we discussed how trustworthy AI adoption and its successful integration into our country’s critical infrastructure and systems are paramount. In this post, we discuss how explainability in AI is crucial to ensure the transparency and auditability of your AI deployments. Outputs from trustworthy AI applications must be explainable in understandable terms based on the design and implementation of…
Join our newsletter for expert advice, the latest research, and exclusive events.
By submitting this form, I acknowledge I will receive email updates from Snorkel AI, and I agree to the Terms of Use and acknowledge that my information will be used in accordance with the Privacy Policy.