Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
New research expands limitations of weak supervision, foundation models
Snorkel AI researchers continue to push the frontier of machine learning, as demonstrated by the 18 research papers recently added to our website.
This batch of research papers, all published in 2022, present new developments in weak supervision and foundation models. One explores the application of weak supervision beyond classification to include rankings, graphs, and manifolds. Several others examine the opportunities and risks associated with foundation models—including several techniques that can improve the value of any foundation model. Additionally, Snorkel researchers also turned their attention toward machine learning challenges in the biomedical field.
Below follows a summary of each of the papers. You can see more Snorkel papers on the research section of our website.
PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts
S. Bach, et al
PromptSource is a system that provides a templating language, an interface, and a set of guidelines to create, share, and use natural language prompts to train and query language models.
Dataset Debt in Biomedical Language Modeling
J. Fries, et al
This paper finds that only 13% of biomedical datasets are available via programmatic access and 30% lack documentation on licensing and permitted reuse, highlighting the dataset debt in biomedical NLP.
A Survey on Programmatic Weak Supervision
J. Zhang, et al
This paper presents a comprehensive survey of recent advances in Programmatic Weak Supervision (PWS), and discusses related approaches to tackle limited labeled data scenarios.
Nemo: Guiding and Contextualizing Weak Supervision for Interactive Data Programming
C. Hsieh, et al
This paper presents Nemo, an interactive system that improves the overall productivity of Weak Supervision learning pipelines by an average of 20%, compared to the prevailing WS approach.
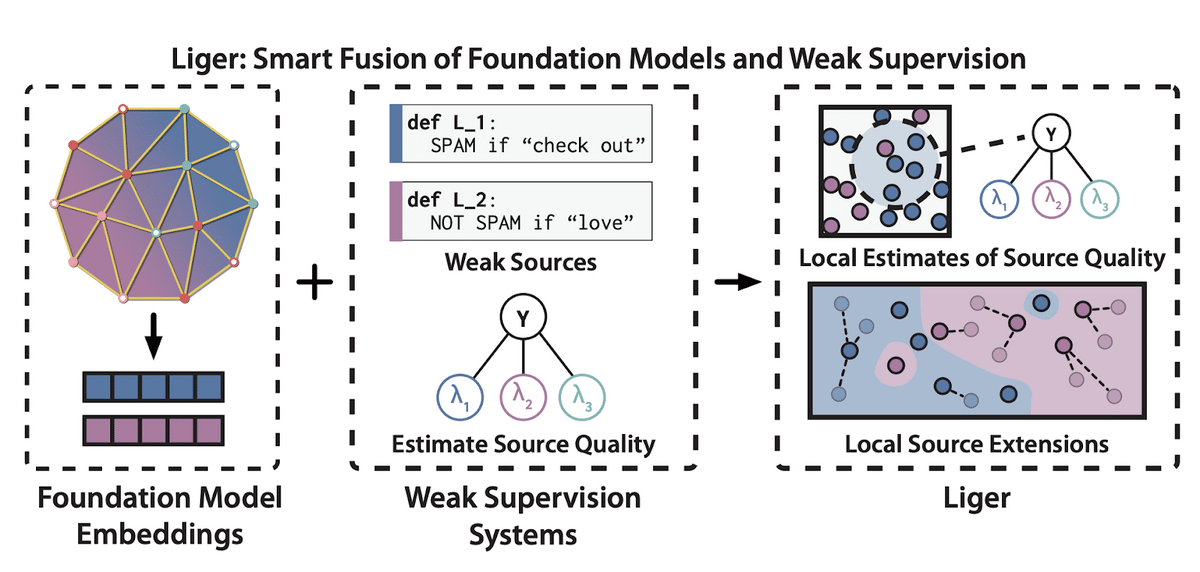
Shoring Up the Foundations: Fusing Model Embeddings and Weak Supervision
M. Chen, et al
Liger, a combination of foundation models and weak supervision frameworks, improves existing weak supervision techniques by partitioning the embedding space and extending source votes in embedding space, resulting in improved performance on six benchmark NLP and video tasks.
Learning to Compose Soft Prompts for Compositional Zero-Shot Learning
N. Nayak, et al
Compositional soft prompting is a parameter-efficient technique that improves the zero-shot compositionality of large-scale pretrained VLMs by learnable tokens of vocabulary and outperforms existing methods on benchmark datasets.
Generative Modeling Helps Weak Supervision (and Vice Versa)
B. Boecking, et al
This work shows how to fuse weak supervision and generative models, jointly creating both labels for points and additional unlabeled data. This improves both the quality of the labels and the abilities of the generative model, while also acting as a form of data augmentation, outperforming a variety of baselines.
BIGBIO: A Framework for Data-Centric Biomedical Natural Language Processing
J. Fries, et al
BigBIO is an open source, community library of 126+ biomedical NLP datasets that facilitates meta-dataset curation for language modeling and enables zero/few-shot evaluation of biomedical prompts and multi-task learning.
Understanding Programmatic Weak Supervision via Source-aware Influence Function
J. Zhang, H. Wang, et al
This paper proposes source-aware variation of Influence Function, which measures the influence of individual components in the Programmatic Weak Supervision pipeline, and can be used for multiple purposes such as understanding incorrect predictions, identifying mislabeling of sources, and improving the end model’s generalization performance.
Lifting Weak Supervision To Structured Prediction
H. Vishwakarma, et al
This work shows how to use weak supervision for settings beyond classification, including predicting structured information like rankings, graphs, and points on manifolds. Surprisingly, it develops theory that shows that the same kind of generalization guarantees found in the classification case apply here too.

AutoWS-Bench-101: Benchmarking Automated Weak Supervision with 100 Labels
N. Roberts, X. Li, et al
AutoWS-Bench-101 is a framework for evaluating automated weak supervision techniques. It builds a benchmark suite to help practitioners choose the best method for their tasks, including picking between zero-shot usage of foundation models, model-based labeling functions, and more.
Tight Lower Bounds on Worst-Case Guarantees for Zero-Shot Learning with+ Attributes
A. Mazzetto, C. Menghini, et al
This paper demonstrates a mathematical analysis of zero-shot learning with attributes, providing a tight lower bound on the worst-case error of the best map from attributes to classes and showing that this bound is predictive of how standard zero-shot methods behave in practice.
Binary Classification with Positive Labeling Sources
J. Zhang, et al.
This paper demonstrates that WEAPO, a Weak Supervision method for binary classification tasks with only positive labeling sources, is effective and efficient—achieving the highest performance of the tested Weak Supervision approaches in terms of label quality and final classifier accuracy on 10 benchmark datasets.
Zero-Shot Learning with Common Sense Knowledge Graphs
N. Nayak and S. Bach
Zero-shot learning with Common Sense Knowledge Graphs is a general-purpose framework with a novel transformer graph convolutional network for generating class representations from common sense knowledge graphs, which improves over existing WordNet-based methods on zero-shot learning tasks.
Contrastive Adapters for Foundation Model Group Robustness
M. Zhang, et al.
The authors propose Contrastive Adapting, an efficient adapter training strategy that improves the group robustness of large pre-trained foundation models (FMs) without finetuning, leading to up to 56.0 percentage points of increase in accuracy compared to zero-shot.
Ask Me Anything: A simple strategy for prompting language models.
S. Arora, et al.
This paper proposes “Ask Me Anything” (AMA), a prompting method that uses weak supervision to combine noisy predictions from multiple prompts generated from an LLM, resulting in an average 10.2% performance lift over the few-shot baseline across a variety of different open-source models.
On the Opportunities and Risks of Foundation Models
R. Bommasani, et al.
Stanford researchers concluded that new, larger, and more powerful foundation models represent a paradigm shift in AI, providing opportunities and risks that require deep interdisciplinary collaboration to understand and address.
Anomaly Detection with Multiple Reference Datasets
M. Chen, et al.
This paper proposes generalizations of CWOLA and SALAD, which exploit multiple reference datasets to improve performance in resonant anomaly detection, and provides finite-sample guarantees to go beyond existing asymptotic analyses.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Matt Casey
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.