Join our inaugural Reading Group in San Francisco on April 29. Register now
LoRA: Low-Rank Adaptation for LLMs
Large language models promise enormous functionality. Trained on internet-scale datasets, off-the-shelf LLMs handle many general reasoning tasks remarkably well without any additional training. Reaching high performance on specific tasks, however, requires additional customization. At tens of billions of parameters, customizing an entire LLM costs significant time and money. But data scientists have developed a shortcut: Low-Rank Adaptation, also known as LoRA.
LoRA shrinks the difficulty of training and fine-tuning large language models (LLMs) by reducing the number of trainable parameters and producing lightweight and efficient models. Data scientists can also apply LoRA to large-scale multi-modal or non-language generative models, such as Stable Diffusion.
Table of contents
LoRA: through the low-rank looking glass
LoRA is one form of parameter-efficient fine-tuning, abbreviated PEFT. The central idea underlying LoRA, and PEFT more generally, is to approximate the update to a large parameter model using a low-dimension update. This low-dimension update contains most of the information (gradient signal) contained in the full update but requires much less computation time and memory.
Intuition
LoRA doesn’t change the underlying model, but it changes how the model emphasizes different connections. Think of each low-rank matrix as a filter. Most photo applications offer pre-made filters that users can apply to their images to evoke different moods. A sepia filter makes photos look older. Adding a vignette filter makes the photos feel more cinematic.
LoRA matrices work similarly, though more subtly. Through their chosen training data, data scientists and machine learning engineers can modulate the model’s response to perform better on a particular topic or task or to render responses in a particular tone. Because this doesn’t alter the underlying model, they can train different LoRA “filters” for different applications and apply them to the same model.
Algorithmic details
The genesis of LoRA was a paper by Microsoft researchers Edward Hu, et. al. In this work, they apply their technique to the use case of fully fine-tuning the GPT-3 175B model and show that LoRA “reduces the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.” These are immense savings that make full LLM fine-tuning feasible and cost-effective for those who are compute constrained.
The idea behind the technique is simple: Given a layer’s weight matrix W0, the weights are updated during each iteration of fine-tuning as W0 = W0 + ∇W, where ∇W is the gradient of the weight matrix. Computing this update matrix is what takes the bulk of time and GPU resources in finetuning. The researchers cleverly note that one can approximate and greatly simplify the update computation by breaking ∇W into a product of low-rank matrices.
Mathematically, you can think of this as projecting the weight matrix into two low-dimensional subspaces (where the learning now occurs) and then reconsolidating it in the original space. LoRA can be applied to any and all weights in the model, including the attention weights. Data scientists can use a number of approaches to select which weight matrices to update.
Efficiency and runtime analysis
Studies have shown that LoRA training pipelines can use incredibly small rank-decomposition subspaces (relative to the size of the original space). Doing so allows data scientists to fine-tune an LLM such as GPT-3 by updating as few as 0.01% of the original parameters.
PEFT and LoRA implementations
Popular deep learning libraries offer PEFT implementations, such as PyTorch Lightning’s Lit-GPT and HuggingFace’s PEFT, that accelerate the process of getting to a fine-tuned model. Configuring PEFT is particularly simple in HuggingFace. Doing so requires only a quick import statement followed by wrapping a base HuggingFace Transformers model. From their blog post, all you need is to add the following lines to your code to integrate PEFT into your finetuning workflow.
Starting with imports…
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"And subsequently define an appropriate config…
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)And finally wrapping the base Transformers model…
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282LoRA/PEFT + scalable data curation
Appropriate data selection forms the foundation for all machine learning customization efforts—whether that’s a simple logistic regression model or a LoRA-customizated generative AI (GenAI) model.
For LoRA and other GenAI fine-tuning approaches, data scientists and machine learning engineers must ensure that they have a sufficient number of high-quality, domain-appropriate prompt and response pairs for each of the tasks that they care about. Depending on the number and complexity of the target tasks, this could require tens of thousands of examples. Few organizations possess this data in a usable form. The vast majority would require labeling and curation. Manual approaches to preparing this data often prove unworkable due to time, cost, or privacy concerns.
The Snorkel Flow AI data development platform allows users to clear this challenge through scalable data labeling solutions. For example, two of our researchers used programmatic labeling functions in Snorkel Flow to curate 20,000 examples from the OpenAssistant and Dolly 2.0 data sets down to the best 10,000 examples in about a day.
The original version fo the RedPajama open source LLM used the entire 20,000 examples. Our researchers fine-tuned a separate version using their curated 10,000 examples. In double-blind study, human testers preferred our researchers’ version of the model in every category. Snorkel researchers and engineers have since used similar approaches to improve generative applications for some of the largest companies in the world.
<EMBED VIDEO OF CHRIS GLAZE TALK>
Getting LoRA right
Practitioners such as Sebastian Raschka have established a number of tips and tricks that are crucial to getting full performance out of LoRA. Here are some essential heuristics.
- Adjust the scaling factor alpha in the LoRA update. As a general rule of thumb, set alpha to be twice the rank of the decomposition, i.e. alpha = 2 * r.
- Even with LoRA, you’ll still need a decently specced GPU. Expect to need about 14GB of GPU RAM to finetune a 7 billion parameter LLM.
- If you’re resource-constrained, try using QLoRA. You should get about a 33% reduction in GPU memory usage (14GB → 9.37GB) at the cost of about a 40% increase in runtime.
- Ideally, use Adam or AdamW as your optimizer. If you have to use SGD, be sure to do so with a cosine annealing learning rate scheduler.
- Using LoRA, you can fine tune in as little as a single epoch (and often fewer is better, due to overfitting).
- Use LoRA everywhere: there’s no reason not to. LoRA can be applied to dense layers, attention weights, adaptation heads, and projection layers. Using it everywhere seems to help performance and yield additional savings on GPU memory and runtime.
LoRA variants
LoRA’s simplicity and effectiveness have catalyzed a whole thread of research centered on developing LoRA variants. Some of the most popular variants include:
- QLoRA: a quantized version of LoRA
- QALoRA: a combination of PEFT and quantization applied to LoRA
- LongLoRA: adapts LoRA to longer context lengths
- S-LoRA: a scalable version of LoRA that optimizes memory usage
- Tied-LoRA: LoRA with weight-tying for increased parameter efficiency
Many other variants have been proposed, and even more are in the works.
Other PEFT Methods
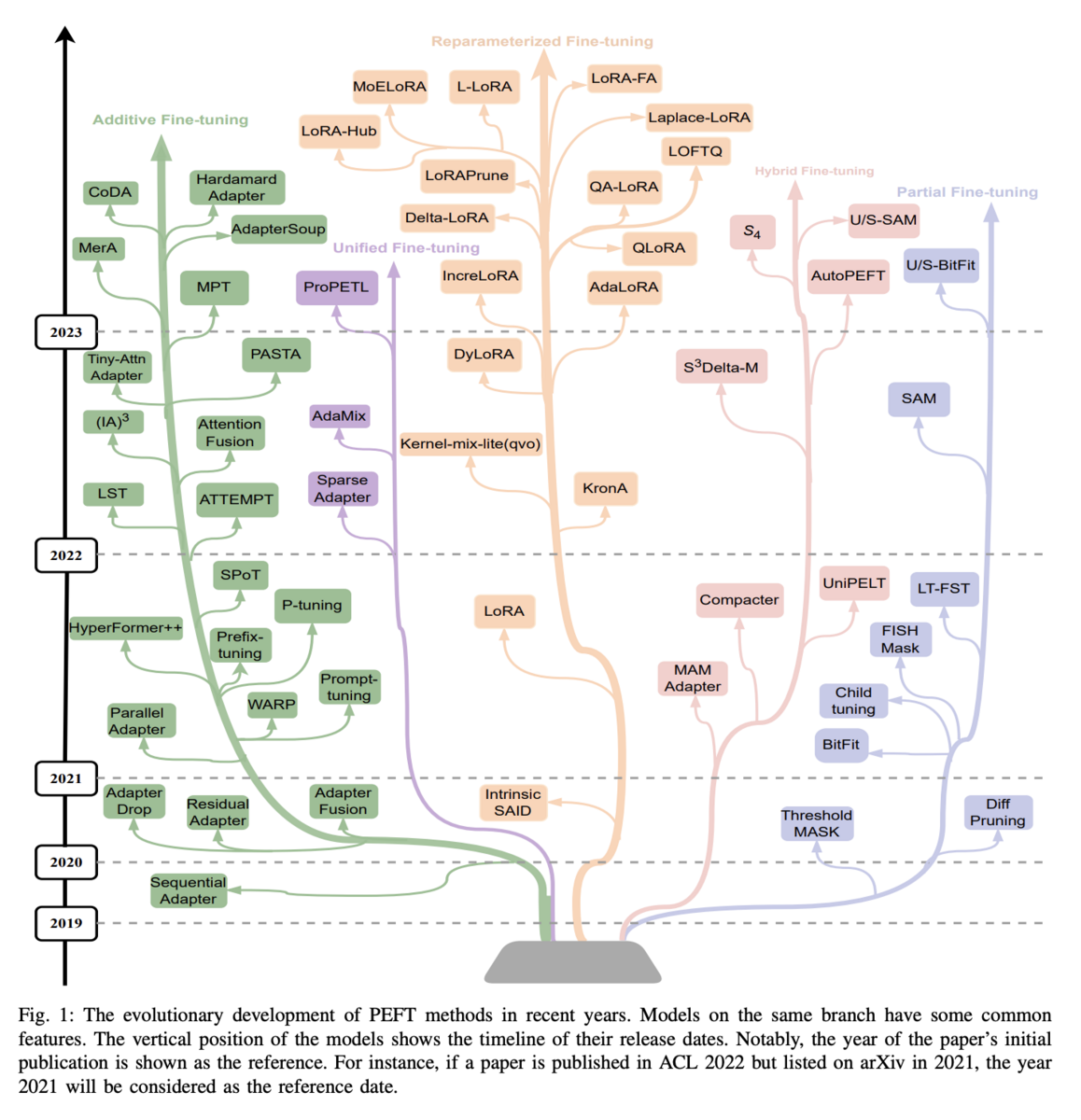
This survey paper provides an excellent overview of the ecosystem of parameter-efficient finetuning methods. While LoRA falls under the umbrella of reparameterized fine-tuning methods, there are four additional categories of methods: additive fine-tuning, hybrid fine-tuning, partial fine-tuning, and unified fine-tuning.
- Additive fine-tuning approaches introduce additional parameters to the model in order to perform task-specific fine-tuning. Examples of additive fine-tuning methods include CoDA and LST.
- Partial fine-tuning approaches operate within a model’s original parameter space. They perform adaptation by selecting a subset of the existing weights most useful for a downstream task. Examples of this approach include SAM and LT-SFT.
- Reparameterized fine-tuning methods take the classical LoRA approach by learning a low-rank approximation to a high-rank matrix update.
- Hybrid fine-tuning methods combine the unique benefits of different PEFT approaches – adapter, prefix, and LoRA – in an effort to achieve the best of all worlds. Examples of the hybrid approach include UniPELT and AutoPEFT.
- Unified fine-tuning methods resemble hybrid fine tuning approaches, but they provide theoretically-motivated architectures for combining methods into a single framework. Examples include AdaMix and SparseAdapter.
Comparing LoRA & PEFT Methods
The following table from the Xu et. al. paper summarizes performance (in terms of GPU memory consumption) across a variety of PEFT methods.
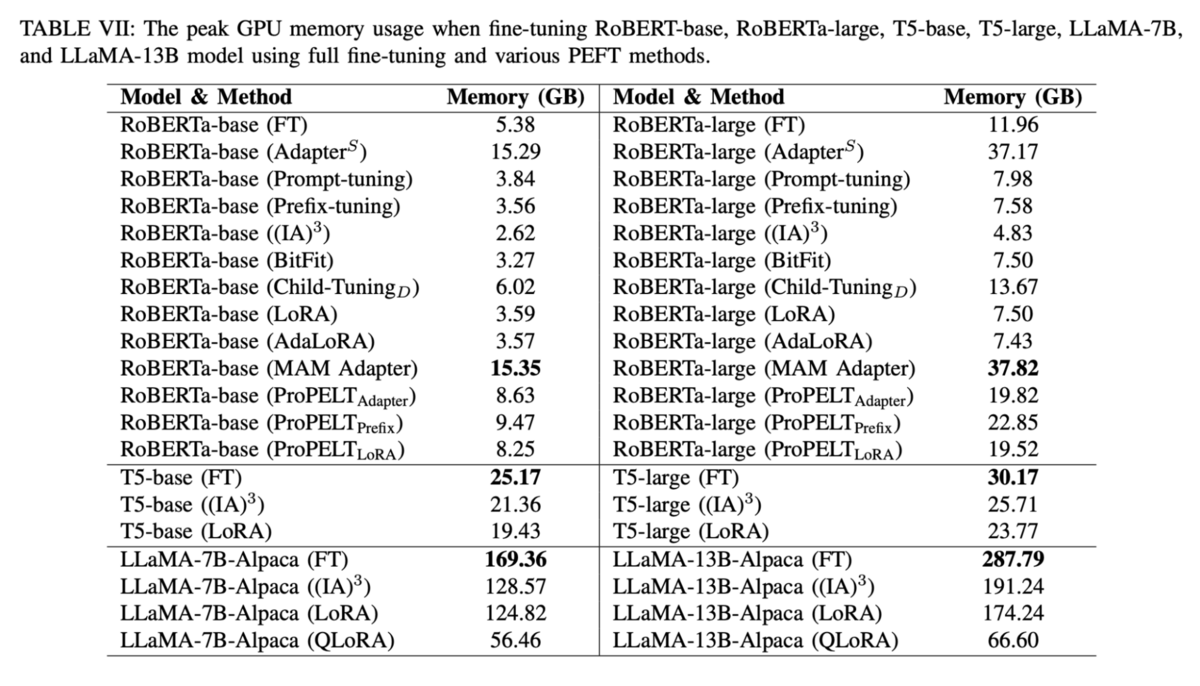
One takeaway is that the reduction in GPU memory usage provided by the use of LoRA and PEFT is huge, ranging anywhere from 25-100% depending on the type and size of the model. Furthermore, if you are willing to sacrifice some accuracy, quantized versions of LoRA can further cut memory usage by half or more. However, some hybrid and additive fine-tuning methods such as MAM can increase memory usage.
Another table from the paper further emphasizes these points
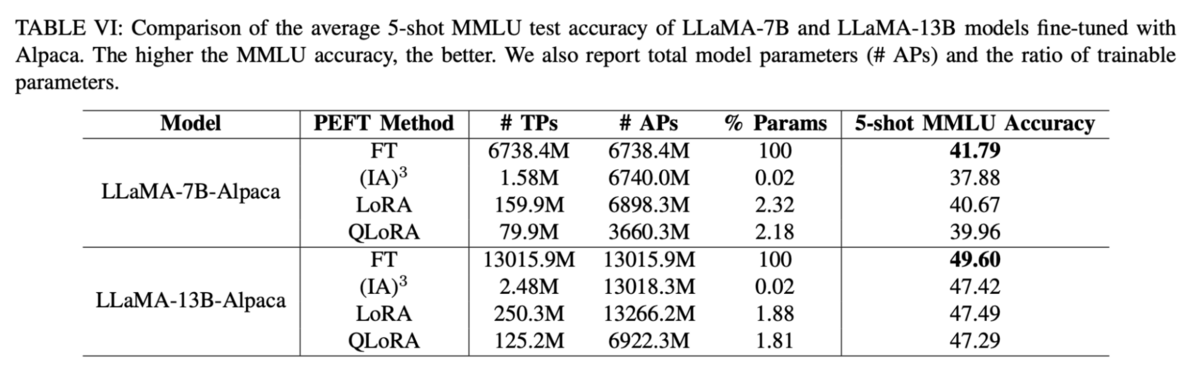
For only a slight reduction in downstream task performance, LoRA and QLoRA can perform comparably to the original LLaMA-7/13B-Alpaca models but with parameter counts at only about 2% of the originals.
LoRA: customize generative models faster
LoRA provides one of the best and easiest ways to reduce LLM parameter counts and memory usage and increase the speed of fine-tuning and inference. The availability and ease-of-use of open source implementations, such as those provided by HuggingFace, allow for plug-and-play adaptations of LoRA and PEFT methods to any LLM.
While many variants of LoRA have been proposed, along with hybrid approaches that combine the benefits of different algorithms, simple approaches such as the original LoRA and QLoRA are enough to provide extreme reductions in memory usage and runtime. Additionally, to get the most out of LoRA, practitioners such as Sebastian Raschka have provided thorough guides that detail optimal hyperparameter settings and strategies for utilizing these methods.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Matt Casey
Matt Casey leads content production at Snorkel AI. In prior roles, Matt built machine learning models and data pipelines as a data scientist. As a journalist, he produced written and audio content for outlets including The Boston Globe and NPR affiliates.