Search result for:
Building FinQA: An Open RL Environment for Financial Reasoning Agents

TL;DR: We built FinQA — a financial question-answering environment with 290 expert-curated questions across 22 public companies, now available on OpenEnv. Agents use MCP tools to discover schemas, write constrained SQL queries, and answer multi-step questions from real SEC 10-K filings. Most open-source models struggle with this kind of multi-step tool use, and even frontier closed-source models, while more accurate, show inefficient tool use — over-querying and lacking the discipline to extract only what’s needed. We break down model performance across multiple axes to understand where and how they fail. Using FinQA as an RL environment, we also collaborated with UC Berkeley’s rLLM team to train a 4B model that outperformed the 235B model from the same family — suggesting that tool discipline, not scale, is the bottleneck. FinQA is our first open environment, with more complex enterprise environments on the way!
The Challenge: Teaching Agents to Reason Over Multi-Step Financial Data
Enterprise financial analysis is one of the most demanding domains for AI agents, requiring financial domain knowledge as well as working over longer context/multi-step data as needed. A financial analyst answering questions from SEC 10-K filings needs to connect data points across multiple tables, identify patterns and analyze trends, perform multi-step calculations, and arrive at a defensible answer. Simple retrieval doesn’t cut it here — this kind of task demands multi-step, domain-rooted reasoning.
At Snorkel AI, we’ve been building expert-curated environments & benchmarks that test models on realistic enterprise tasks. Experts shape every layer of our benchmarks, from environment design – ensuring realism and diversity – to authoring tasks and tuning their complexity. Our SnorkelFinance benchmark evaluates agents on financial question-answering through tool-calling and planning — top models score ~85% on the benchmark. Large generalist models can reason well, but they’re expensive to run and often lack tool discipline — hallucinating column names, ignoring query constraints, or writing bad SQL. What we need is accuracy, efficiency, and reliable tool use, all at once.
To address this, we built FinQA — a financial question-answering reinforcement learning environment with 290 expert-curated benchmark questions across 22 public companies, now available as part of the OpenEnv ecosystem. We also trained a 4B model with RL in FinQA and found it to outperform the 235B model from the same model family.
FinQA is our first open environment on OpenEnv, with complex frontier-level multi-turn enterprise environments coming to customers in the coming months. In this post, we’ll walk through what FinQA is, how it works, and why we chose OpenEnv.
What is FinQA?
FinQA is an RL environment built around financial analyst workflows. An agent is presented with a question about a company’s 10-K filing — for example, “What is the ratio of Domestic Income to Foreign Income for continuing operations before income taxes in 2022?” — and must use a set of tools to explore the available data, query the right tables, and submit a numerical answer.
The environment includes:
- 290 benchmark questions spanning 22 public companies (Alphabet, Amazon, Apple, Bank of America, Boeing, Citibank, and more)
- 4 MCP tools that define the agent’s action space
- Binary rewards with fuzzy normalized numerical matching
The questions range from simple lookups to complex multi-step derivations: computing ratios, year-over-year growth rates, and aggregations across multiple data points. FinQA is also hosted as a Hugging Face space, where you can interact with the tools and step through the environment directly.
Why OpenEnv is great for FinQA
OpenEnv, the open standard for agentic execution environments from the Meta PyTorch and Hugging Face teams, provides a structure that makes it a natural fit for FinQA. Here are a few key design choices that make OpenEnv a great framework for RL environments.
Standardized Gym-Style API
OpenEnv provides a Gymnasium-style step() / reset() / close() API — the same interface RL practitioners already use. FinQA plugs directly into existing training pipelines without custom wrappers.
Direct RL Library Integration
OpenEnv integrates with the major RL post-training libraries — TRL, TorchForge, veRL, SkyRL, and Unsloth — so we didn’t have to build integration adapters for each one.
For example, integrating FinQA with TRL’s GRPO trainer is straightforward:
from trl import GRPOTrainer
from openenv.core.env_server.mcp_types import CallToolAction
from envs.finqa_env import FinQAEnv
env = FinQAEnv(base_url="<http://localhost:8001>").sync()
def rollout_func(prompts, trainer):
for prompt in prompts:
# new episode
result = env.reset()
while not result.done:
# model generates tool call
completion = generate(trainer, prompt)
# extract tool + args
tool_name, args = parse_tool_call(completion)
result = env.step(CallToolAction(tool_name=tool_name, arguments=args))
# 1.0 if correct, 0.0 otherwise
rewards.append(result.reward)
return {"prompt_ids": ..., "completion_ids": ..., "logprobs": ..., "env_reward": rewards}
trainer = GRPOTrainer(model="Qwen/Qwen3-4B", rollout_func=rollout_func, ...)
trainer.train()
Scalable, Containerized Execution
Each FinQA environment runs in an isolated Docker container. This means you can spin up thousands of parallel environments for training — OpenEnv supports up to 16,384 concurrent sessions on multi-node SLURM deployments. For evaluation, even a single container on Hugging Face Spaces works out of the box.
Community and Discoverability
The OpenEnv Hub on Hugging Face is a central place where researchers can discover, deploy, and interact with environments. FinQA being part of this hub means anyone can find it, run it, and submit results. This makes evaluation and reproducibility straightforward.
MCP as the Tool Protocol
OpenEnv uses MCP for tool encapsulation (RFC 003). Since MCP is widely accepted as a tool-use interface, it was straightforward for us to implement the FinQA tools as MCP endpoints.
How It Works: A Walkthrough
The Agent’s Toolkit
FinQA exposes four tools to the agent via the Model Context Protocol (MCP):
| Tool | What It Does |
|---|---|
get_descriptions | Lists all available financial tables for a given company |
get_table_info | Returns column names, data types, and sample values for a table |
sql_query | Executes a SQL query against a specific table (must include filters — no SELECT *) |
submit_answer | Submits the agent’s final answer, ending the episode |
In enterprise settings, data is spread across multiple systems — and the first challenge is often just figuring out what’s available and how to connect it. The agent has to discover tables, understand schemas, and write targeted queries before it can even begin answering the question. We enforce constraints on SQL queries (no SELECT *, filters required) — not because this is a text2sql benchmark, but because the agent needs to learn to extract exactly what’s relevant rather than dumping entire tables. This multi-step process of discovery, querying, and reasoning mirrors real enterprise workflows beyond just financial analysis; whether it’s HR, insurance, or engineering, the pattern is the same.
An Example Episode
Here’s what a typical episode looks like. The methods you see below — list_tools(), call_tool(), step(), and reset() — all come from OpenEnv’s standardized API, which handles episode management, MCP tool serving, and the HTTP transport between the training loop and the environment. We only had to define the domain-specific tools and the reward function.
# Start the environment from a Docker image
async with FinQAEnv.from_docker_image("finqa-env:latest") as env:
# 1. Reset — start a new episode
await env.reset()
# 2. Discover available tools
tools = await env.list_tools()
# [get_descriptions, get_table_info, sql_query, submit_answer]
# 3. Discover available tables for a company
result = await env.call_tool("get_descriptions",
company_name="alphabet")
# Returns: ["us_gaap_RevenueFromContractWithCustomer...",
# "us_gaap_ScheduleOfIncomeBeforeIncomeTax...", ...]
# 4. Inspect the relevant table
result = await env.call_tool("get_table_info",
company_name="alphabet",
table_name="us_gaap_ScheduleOfIncome...")
# Returns: columns, dtypes, sample values
# 5. Query for the specific data
result = await env.call_tool("sql_query",
company_name="alphabet",
table_name="us_gaap_ScheduleOfIncome...",
query="SELECT domestic, foreign FROM data WHERE year = '2022'")
# 6. Submit the computed answer
step_result = await env.step(
CallToolAction(tool_name="submit_answer",
arguments={"answer": "6.118"}))
# step_result.observation.reward = 1.0 (correct!)
# step_result.observation.done = True
The agent gets up to 50 tool calls per episode. The reward is binary: 1.0 if the submitted answer matches the ground truth within tolerance, 0.0 otherwise. Since financial answers come in many formats (LaTeX, percentages, fractions, thousands separators, negative numbers in parentheses), the reward computation normalizes across all of these before comparing. This normalization removes the need for LLMJ-style scoring, allowing for faster and more efficient/cost-effective training.
Plug and Play: Connecting Multiple Environments via OpenEnv
Training Loop (PyTorch, TRL, veRL)
│ reset(), step(), get_reward()
│ ← HTTP (full control) →
│
FinQA Environment (Docker Container)
│
├── HTTP API: Episode management, state, rewards
│ (visible to training loop only)
│
└── MCP Server: Tools for the agent
(visible to agent only)
├── get_descriptions
├── get_table_info
├── sql_query
└── submit_answerw
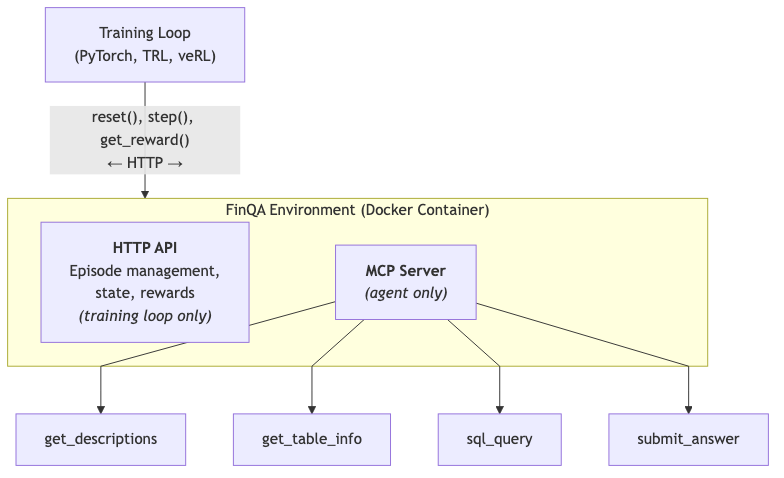
Since the tools are exposed as MCP servers, you can connect multiple OpenEnv environments together in a single RL run — combining FinQA with a code execution environment or a document retrieval environment, for instance — and the agent just sees one set of MCP tools. As more environments get built on OpenEnv, you can mix and match them to build more realistic training setups without writing custom integration code.
RL Training Results: Tool Discipline Beats Scale
FinQA has already been used in practice. In a recent collaboration with the rLLM team at UC Berkeley on the Agentica project, we used FinQA as the RL environment to fine-tune Qwen3-4B. The result: the 4B parameter model outperformed Qwen3-235B at 1/60th the size.
The key insight here is tool discipline over scale. Large models can reason well but lack reliable tool use — hallucinating column names, ignoring SQL constraints, producing nonsensical queries. Training a smaller model with RL in FinQA taught it to use tools precisely and consistently, and we found that training on simple single-table queries generalized to complex multi-table reasoning.
A 4B model runs on a single GPU; a 235B model requires a multi-node cluster. For a firm processing 50,000 analyst queries monthly, that’s roughly a 90% reduction in inference costs with improved accuracy.
Open-Source Model Performance
As a reference, the SnorkelFinance leaderboard paints a clear picture of where open-source models stand on agentic financial reasoning today.
| Model | Score |
|---|---|
| Kimi K2.5 | 81.0% |
| Deepseek v3.2 | 75.9% |
| Qwen3.5 397B | 74.0% |
| Kimi K2 Thinking | 71.7% |
| GPT-OSS 120B | 66.6% |
| rLLM-FinQA-4B | 59.7% |
| Qwen3 235B A22B | 51.37% |
| Llama 3.3 Nemotron Super 49B v1.5 | 44% |
| Codestral 2501 | 27.6% |
| Magistral Medium 2506 | 16.2% |
| Mistral Large 2411 | 13.4% |
Most open-source models struggle with the kind of multi-step tool use that FinQA demands — discovering schemas, writing constrained SQL, and chaining results together. This is exactly the gap that RL training in environments like FinQA is designed to close.
Beyond Accuracy: Multi-Axis Evaluation
Training rewards can often be sparse in complex RL environments, leading to uni-dimensional model training — where the model is only optimized for correctness, without consideration for tool use, efficiency, or reasoning quality. We evaluate models across multiple axes and rubrics, producing denser reward signals that allow us to understand how models fail and systematize behaviours for better model training.


Model evaluation across multiple dimensions for gpt-5.2 & claude-opus-4.6
We break evaluation into three categories:
Agent-level metrics
Agent-level metrics measure the quality of the model’s behaviour end-to-end:
- Step error-free rate : Can the agent call tools without tool errors?
- Efficient tool use : Does it over-query or use a minimal set of calls?
- Correctness : Does the final answer match the ground truth?
- Hallucination rate : Did the model hallucinate invalid columns, tools, databases?
A model with a high step error-free rate but low correctness is able to call tools without errors, but is not able reason and chain tools together correctly. On the other hand, a model with low efficient tool use is over-querying — calling tools they don’t need. Each of these is a distinct, trainable failure mode that RL can target directly.
Per-tool success rates
Per-tool success rates isolate which tools the model struggles with. For example, in FinQA, sql_query can lag behind get_descriptions and get_table_info, which suggests models can discover schemas but struggle to write correct queries. This pinpoints where reward shaping or targeted data would help most.
Infrastructure metrics
API success rate and recursion handling metrics confirm that failures are model-side, not environment-side. These metrics are used for monitoring and debugging, ensuring that the environment is working as expected.
Based on this decomposition, we observed a consistent pattern: models that score well on step-level metrics but poorly on correctness are making valid tool calls but reasoning incorrectly about the data they retrieve. Models that score poorly on tool-use efficiency metrics are over-querying — calling tools they don’t need. Each of these is a distinct, trainable failure mode that RL can target directly.
What’s Next: Snorkel’s Environment Roadmap
We started with FinQA as a lightweight/straightforward example – here’s where we’re headed.
Complex enterprise environments: Real enterprise workflows are multi-turn and multi-system — agents pull data from multiple sources, cross-reference documents, navigate domain-specific constraints, and make decisions and plan over extended horizons. Context is noisy, tools have rate limits and incomplete documentation, and they can fail or return unexpected results — the agent has to handle all of it. We’re building environments that capture this: multi-turn, multi-tool workflows spanning healthcare, insurance, and legal, where agents operate over longer horizons and produce outputs you can’t score with a binary reward. These will all be hosted on OpenEnv. You can find more details on how we think about environment complexity here.
Tighter integration with evaluation infrastructure: We’re collaborating with OpenEnv and Hugging Face to make the path from “train on an environment” to “submit to a leaderboard” as seamless as possible. The goal is a unified platform where building an environment, training on it, and benchmarking against it are all part of the same workflow.
Open benchmarks for the community: As part of Snorkel’s $3M Open Benchmarks Grant — in partnership with Hugging Face, Prime Intellect, Together AI, Factory HQ, Harbor and PyTorch — we’re funding the development of open-source datasets, benchmarks, and evaluation artifacts.

Get Started
FinQA is available now in the OpenEnv repository. You can:
- Run it locally: Clone the repo, download the data, and launch the environment with
uvicorn - Run it in Docker: Build the container and spin up isolated instances for training
- Evaluate your models: Use the inference script to benchmark any OpenAI-compatible model against the 290-question dataset
- Submit to the leaderboard: Run your results and submit to the SnorkelFinance leaderboard
Better enterprise agents need better environments — realistic tasks, expert-curated data, and standardized infrastructure. OpenEnv gives us that foundation, and FinQA is one of our first contributions to it.
If you’re interested in early access to our upcoming enterprise environments, or want to commission a custom RL environment tailored to your industry workflows of choice, get in touch with the Snorkel AI team to start building!
FinQA was developed by the Snorkel AI research team. For questions and collaboration, reach out to us at snorkel.ai. To explore FinQA and other OpenEnv environments, visit the OpenEnv Hub on Hugging Face.

Bhavishya Pohani
Bhavishya Pohani is an Applied Research Scientist at Snorkel AI, focusing on large language model fine-tuning & agentic systems. Before Snorkel, he worked on building deep learning systems at Chubb Insurance.