Join our inaugural Reading Group in San Francisco on April 29. Register now
4 new papers show foundation models can build on themselves
While the surest way to improve the performance of foundation models (FMs) is through more and better data, Snorkel researchers have explored how FMs can learn from themselves.
Foundation models contain a great deal of additional information that can be relied on for further benefit. This piece will discuss advancements in how to use FMs to improve themselves (or other models like the multimodal zero-shot model CLIP) as well as how to distill typically large foundation models into smaller, more easily deployable versions.
Let’s dive in.
Enhancing CLIP with CLIP
In the standard approach, data scientists improve foundation models by fine-tuning them, but this is expensive and often requires large amounts of labeled data. Instead, Snorkel affiliate Prof. Stephen Bach and his students study pseudolabeling techniques that don’t require much (or any!) labeled data [12].
They consider a full range of training strategies that combine zero-shot outputs from foundation models with techniques such as semi-supervised, transductive zero-shot, and unsupervised learning,
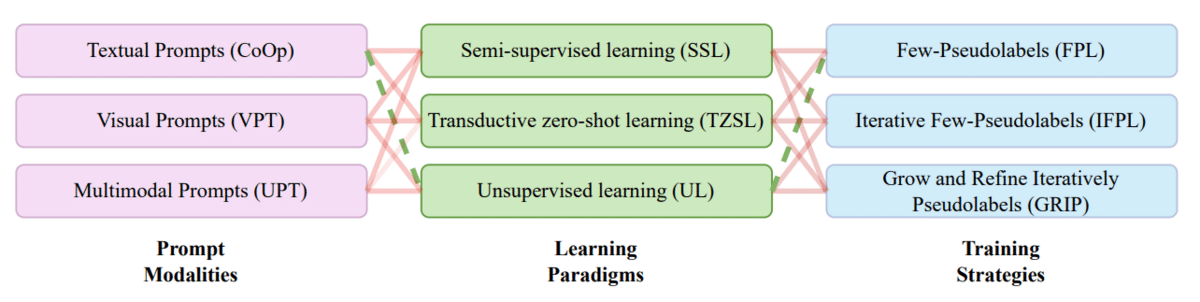
Figure 6 [1]: Design space for pseudolabeling-based improvement of foundation models.
In Figure 6, we show the full design space for improving models like CLIP. This involves a pipeline broken down into three stages with multiple component choices at each.
- The prompting stage asks the model for output.
- The learning stage uses techniques like semi-supervised learning that use few or no labels.
- The training stage employs pseudolabeling to optimize performance.
These techniques end up dramatically self-improving foundation models—for example, CLIP’s accuracy improves by nearly 20 points!
Zero-shot robustification of zero-shot models
Foundation models pick up a variety of biases or spurious correlations from their pretraining corpora. These end up harming zero-shot predictions.
For example, the waterbirds dataset from the WILDS benchmark [2] tests model robustness by asking to distinguish between waterbird and land bird species. Here, the background of the image, while not predictive of the bird species, acts as a spurious feature. Much of CLIP’s training data associates waterbirds with water backgrounds.
As a result, zero-shot predictions of water birds on land backgrounds tend to produce errors.
How can we ensure that CLIP understands that relevant features should be used for prediction, while spurious ones should not?
Snorkeler Fred Sala and his group propose an approach [23] that uses an auxiliary language model to directly ask for what concepts are relevant, and which are spurious. These can be embedded with CLIP and used to modify zero-shot image embeddings so that the effect of relevant concepts is boosted, while that of spurious ones are removed (Figure 7).
This simple idea can dramatically improve zero-shot performance, improving the worst-group accuracy by nearly 17% across nine image and NLP datasets.
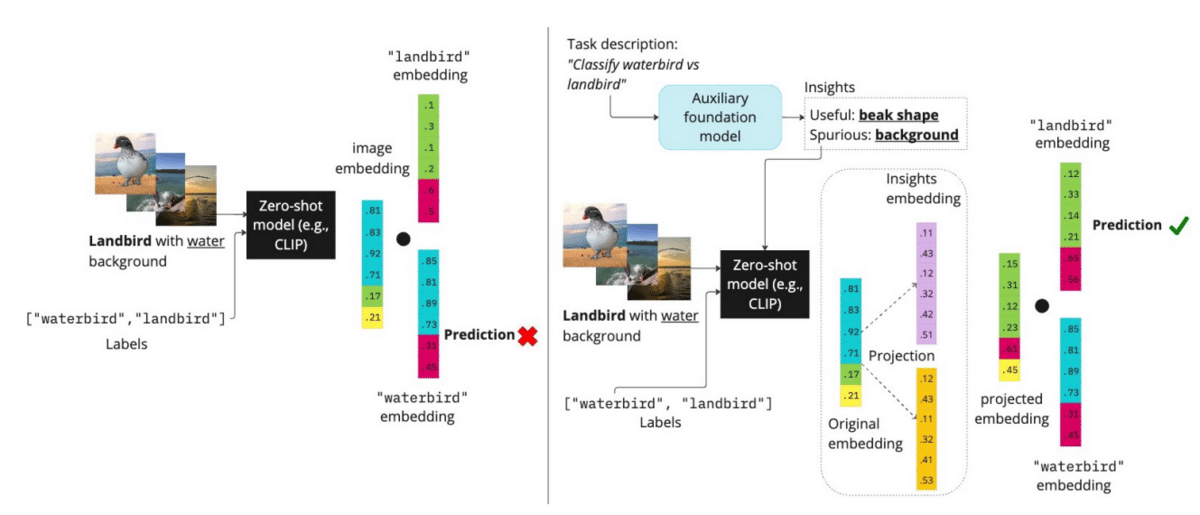
Figure 7 [23]: Pipeline for improving zero-shot models by asking language models for information on what concepts are relevant—and which are likely to be spurious.
Distilling Step-by-Step
Even once we improve them, foundation models present a further challenge: they are so large that they are difficult to deploy for many organizations.
Traditionally, data scientists overcome this obstacle by distilling them into smaller models. This can require large amounts of data to successfully preserve performance. But new research has found another way.
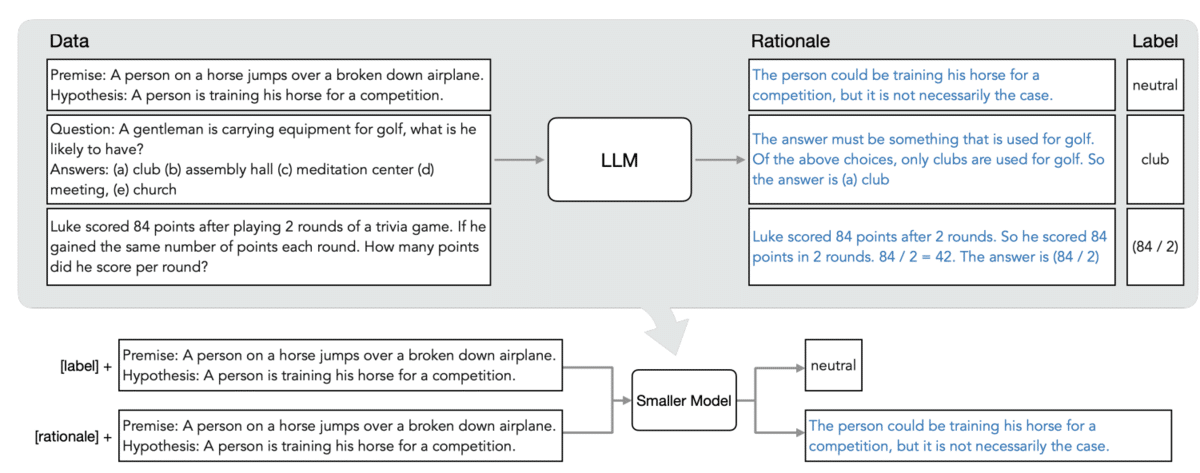
Figure 8 [4]: Distilling foundation models by relying on chain-of-thought provided rationales provided by language models.
In their recent work, Alex Ratner, student Cheng-Yu Hsieh, and others propose building distillation with foundation model-provided rationales.
Rationales describe the reasoning process used to select a particular answer or prediction. They are increasingly popular in helping language models provide better answers, made famous by techniques like chain-of-thought reasoning. In distilling step-by-step, large language models (LLMs) provide rationales that are used inside the distillation process, resulting in smaller, more deployable models that offer extremely high performance (Figure 8).
Snorkelers continue to push FM boundaries
Snorkelers continue to push forward the state of the art in AI and machine learning. In the three papers outlined above, they’ve found new ways to get foundation models to improve themselves, enabling data scientists to craft higher-quality models.
We’re incredibly excited about all of these advancements—and there’s much more to come! Keep watching this space to see what Snorkel researchers do next.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!
Bibliography
- C. Menghini, A. Delworth, S. Bach, “Enhancing CLIP with CLIP: Exploring Pseudolabeling for Limited-Label Prompt Tuning”, 2023.
- P. W. Koh et al, “WILDS: A Benchmark of in-the-Wild Distribution Shifts”, ICML 2021.
- D. Adlia et al, “Zero-Shot Robustification of Zero-Shot Models With Auxiliary Foundation Models”, 2023.
- C. Hsieh et al, “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes”, 2023.

Fred Sala
Frederic Sala is Chief Scientist at Snorkel AI and an assistant professor in the Computer Sciences Department at the University of Wisconsin-Madison. His research studies the fundamentals of data-driven systems and machine learning, with a focus on data-centric AI, foundation models, and automated machine learning. He and his group received the 2024 DARPA Young Faculty Award, a best student paper runner-up award at UAI '22, the outstanding Ph.D. dissertation award from the UCLA Department of Electrical Engineering, the NSF Graduate Research Fellowship.