

Daniel Wu is Head of AI and Machine Learning for Commercial Banking at JPMorgan Chase & Co. He presented at Snorkel AI’s Future of Data-Centric AI virtual event in August 2022. Below follows a transcript of his presentation, lightly edited for improved readability.
Machine learning has become the state-of-the-art technique for many tasks, including computer vision and NLP. Even though more and more components in an ML lifecycle are being designed to run on autopilot, it is beneficial to incorporate human knowledge into the ML system. In some use cases, this is even a necessity.
Our discussion of data-centric AI would not be complete without discussing human-in-the-loop machine learning. After all, it was the desire to simulate human intelligence that inspired the field of AI.
Human-in-the-loop (HITL) machine learning describes the process when a human is involved in developing, evaluating, and improving a machine-learning solution; including annotating data, designing algorithms, applying heuristics, and providing feedback. As illustrated in the bar chart (below), human-in-the-loop machine learning is an active research topic that has seen an increasing number of publications in the last 10 years.

Human-in-the-loop machine learning is a big topic with many open challenges. In this talk, I plan to cover a brief overview of human-in-the-loop machine learning and show two sophisticated examples of applying it to computer vision and NLP tasks. Before diving into human-in-the-loop machine learning, let’s think about why it is beneficial or necessary to involve humans in the machine-learning loop.
First and foremost, we are all here because we recognize that data is central to AI. While AI is competent at independently learning from large, high-quality datasets, such datasets are rare in the business world and are very expensive to create. In fact, in a survey done by Kaggle back in 2017, about 50% of data scientists complained that “dirty” data was the biggest challenge for their daily job.
While we dream about working with a large dataset of high quality, we most likely need to deal with the lack of quantity or quality in the dataset that we have. Therefore, the most common application for human-in-the-loop today is to augment rare and/or low-quality data with human annotations. Secondly, human intelligence is capable of many skill sets that are still unavailable to AI at this time, such as creativity, imagination, understanding—not just semantics, but also abstract meanings.
Similarly, creative extrapolation is not possible for AI at this stage. Hence human-in-the-loop enables this learning process and knowledge transfer from human intelligence to AI. AI applications can become “black boxes,” in which the processing that converts data into a decision or insight is completely hidden. This is problematic for data-sensitive activities, such as finance and banking, and for some decision-making. Regulatory compliance and disclosure needs are associated with certain industries. So, in these cases, human-in-the-loop allows humans to see how the AI tool arrives at a particular outcome with a given set of data.
In high-stakes decision-making, it is essential to have a human in the loop to comply with regulations and to fulfill social responsibilities. When properly applied, human-in-the-loop can really improve fairness, transparency, and accountability. In addition, humans’ involvement in evaluation facilitates continuous improvement that leads to better consistency, accuracy, and robustness of the solution. As we’ll see in the two concrete examples, when you properly apply and design human-in-the-loop, it can greatly improve the efficiency and reliability of machine learning.
Finally, an organization that can reap the benefits of human-in-the-loop would have a great competitive advantage stemming from all of the above, and also establish the trust that is needed for increasing AI adoption.

So, let’s quickly look at some of the real-world human-in-the-loop applications in different fields. The most common use-case that everybody is aware of when we talk about human-in-the-loop is annotation. This is the most known human-in-the-loop application, hence I’m not going to go into details on this.
In social media, human involvement is essential to help the machine learn to identify text, images, and videos for hate speech, cyberbullying, explicit or harmful content, “fake news,” and so on.
In healthcare, medical imaging and AI-based recognition of “normal” versus “abnormal” features of images are being extensively developed, and such developments require intervention by subject-matter experts to train the model and to look for specific features of an image that point to abnormalities. Even the best-trained models must be backed further by human confirmation, because diagnosis and treatments deal with lives, and mistakes are not acceptable.
In transportation, we develop self-driving cars with a massive amount of image, video, and sensor data that are collected and annotated by humans. We’ll also see a human-in-the-loop application to video object detection that can be used to develop autonomous driving solutions. (below)
Beyond the above essential applications, human-in-the-loop AI systems can have entertainment value as well. At Stanford’s Human-Centered AI Initiative, they design systems that combine technology with human interaction to develop new tools to create musical and artistic content. In finance, which is a highly regulated industry, human experts are needed to ensure the integrity of the automation process. Best-in-class AI solutions enable financial institutions to use combinations of machine learning and human review protocols. Human-in-the-loop helps to ensure compliance with organizational and governmental requirements.
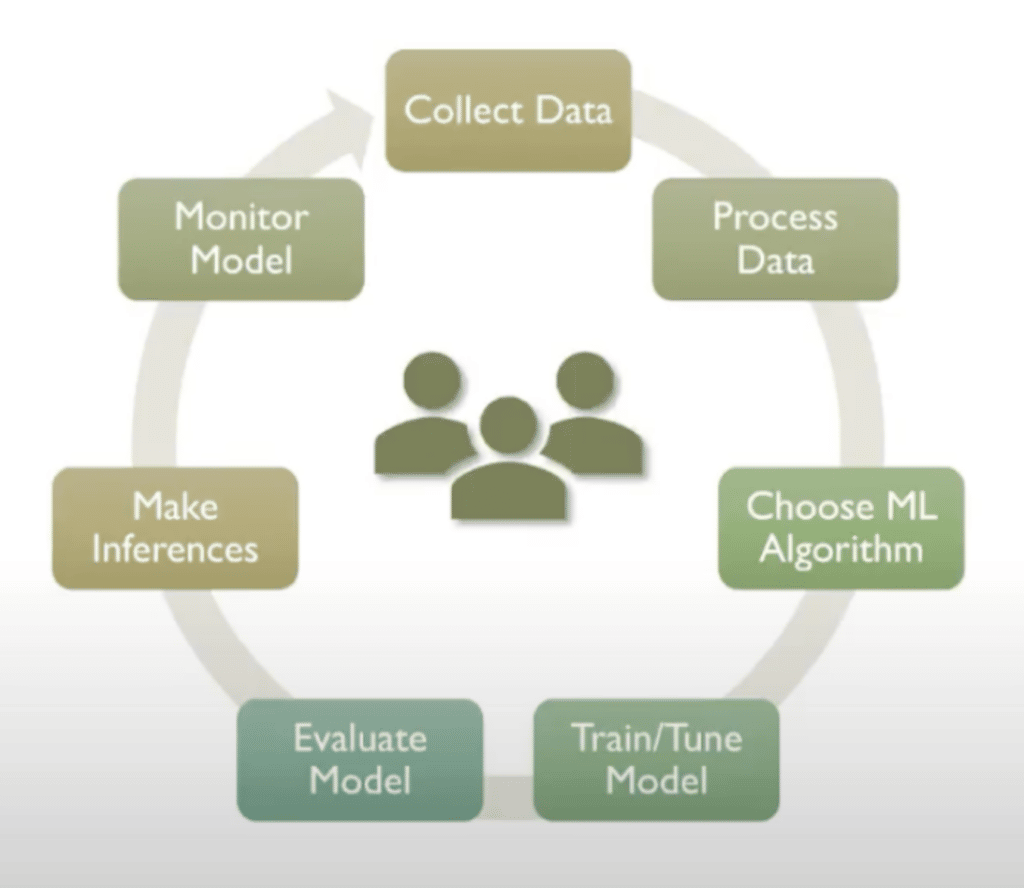
Next, we’ll take a quick look at where humans can be involved in the machine-learning lifecycle. A typical machine-learning lifecycle goes through these stages: involving collecting data, processing data, choosing algorithms, training and tuning models, evaluating models, making inferences, and monitoring models.
Integrating a priori knowledge into the learning framework is an effective way to deal with sparse data, as the learner does not need to induce the knowledge from the dataset. It can be injected in the form of training data, dictionaries, vocabulary, taxonomies, and rules, just to name a few. Recently, more and more practitioners integrate pre-training knowledge into their learning framework, which is also an effective form of integration of a priori knowledge.
A common form of human-in-the-loop machine learning is to create a continuous feedback loop between human and machine. In supervised learning, which is still the most commonly applied machine learning paradigm today, human-in-the-loop can be applied throughout the stages of supervised learning, from data collection, data cleansing, validation, standardization, and quality control.
Semi-supervised learning, with active learning, is also a popular way of applying a human-in-the-loop approach. One way to implement semi-supervised learning from an unlabeled dataset is to have humans label just a small set of data to seed a model, then apply the high-confidence predictions from an interim model or use a transfer-learning model to label more through data labeling. Then send the low-confidence predictions for human review, which is active learning.
In reinforcement learning, the agent learns from rewards it receives from its environment. And we all know that reward engineering is a very challenging task and it actually determines the success or the failure and how effectively the agent can learn. Recently, Peter Beale and his group at [the University of California] Berkeley developed an interesting interactive, deep-reinforcement learning algorithm named Pebble. It empowers a human supervisor to directly teach an AI agent new skills without the usual extensive reward engineering or curriculum design efforts. Our second example that we look at will showcase humans’ involvement in training an intelligent agent to perform semantic parsing in NLP these hierarchical reinforcement learning.
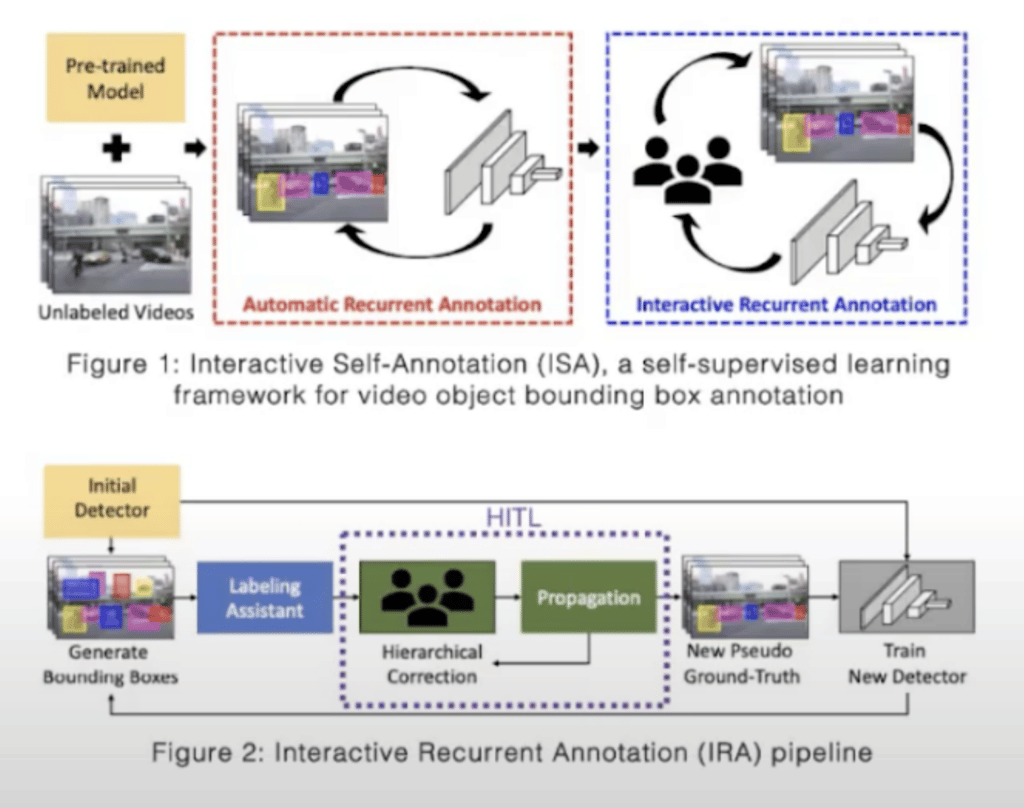
Let’s first look at an example of applying human-in-the-loop to computer vision. Applying human-in-the-loop requires a lot of thought and careful design for it to be cost effective. And in computer vision, especially in video object detection and annotation, manually collecting object annotations is a very time consuming task. This becomes tedious, especially when the target size is small or the target is partially occluded in crowded scenes, which usually happens on those street scenes. This particular work proposes a simple yet efficient interactive self annotation framework based on self-supervised learning to generate ground-truth bounding boxes for video objects. Their method can cut down both annotation time and human labor costs.
The generated ground-truth information can be used for various tasks related to video object detection. The proposed ISA framework consists of two separate processes. Both are recurrent annotation processes. One is automatic recurrent annotation (ARA), and the second is interactive recurrent annotation (IRA). The goal of ARA is to build an object detector that can support the IRA, and the IRA is the part where the human gets looped in. So in ARA we basically build a pipeline to iteratively train an object detector through self-supervised learning. And to begin with, they use an off-the-shelf object detection model to begin the training loop and iteratively improve the performance of the model.
Once the model is trained, the model detector is improved through ARA. The bounding box and the model itself would be used in the second phase, which is the interactive phase, where human annotators are involved in correcting the bounding boxes in a very efficient way. And mistakes are corrected to guide the object detector to come up with better bounding boxes. They apply hierarchical corrections. This is a very smart way of annotation. Instead of correcting frame by frame by the human annotators, they basically only ask the human annotators to look at the key frames, correcting those bounding boxes in the key frames, and then propagate a correction throughout the rest of the video.
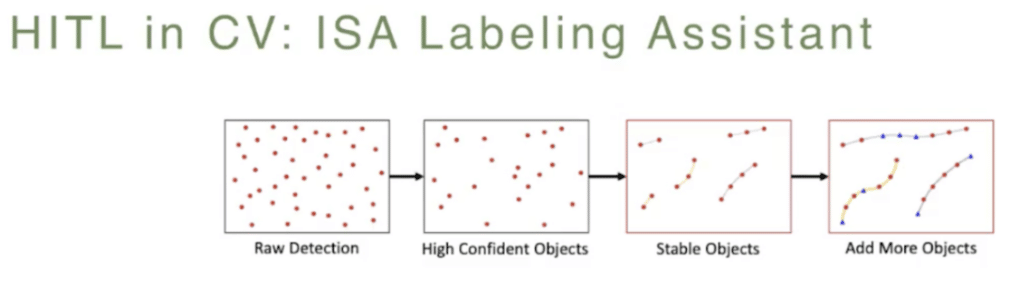
And through this, an important part of this framework is a labeling assistant. I’ll just quickly talk about the design of this module. This pipeline involves three steps. First, it will have the raw detection by the model. And then we filter out the the bounding boxes for the objects with low-confidence scores. After that, they apply object tracking by detection algorithms to create “tubelets.” These are sequences of associated bounding boxes across the time of the video. And then they remove unstable tubelets. These are the tubelets with a temporal length of less than five frames. Throughout this process there may be objects that are accidentally removed or missed through the detection, so they have the final step of adding back these objects, or these bounding boxes, in previous and the next frames.

So a quick look at the tool, or the labeling assistant. Here’s a sequence of three frames in the video sequence. And from top to bottom, the top row shows the raw detection by the model. As you can see, it’s very, very noisy and there’s a lot of low-confidence predictions, especially near the bottom of the frame, which is really not interesting or important for our task. Then the second row here shows, across the time, how bounding boxes with low confidence scores were removed by the labeling assistant automatically. And finally, by applying the object tracking, they were able to recreate or find the mislabeled objects. Also, connecting the objects that should have been labeled. For example, in the middle-right center of this frame, you notice that the object was accidentally removed but then later added back.
So this is a very powerful tool to automatically create good proposed bounding boxes before we involve humans to correct the annotations that were done by the model.
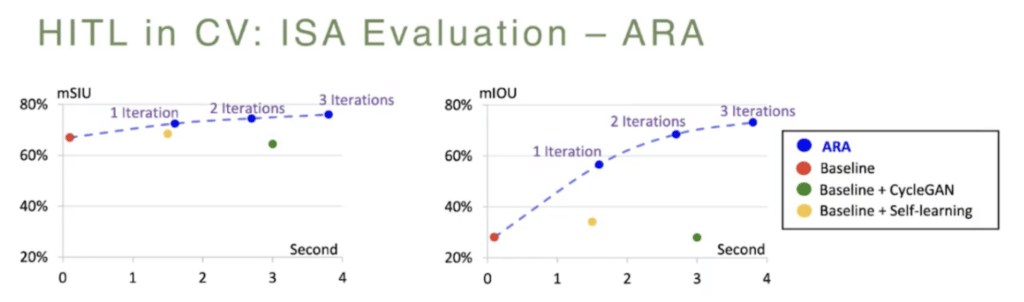
So, quickly look at the evaluation. They evaluate ARA and IRA independently. With ARA they evaluate using the CityScapes dataset. The observation is that with ARA, which is the first phase of automatically training the model to create high-quality bounding boxes, they were able to see the detection results converge after just three iterations with good quality bounding boxes. They also perform cross domain evaluation using the baseline model pre-trained on the Berkeley Deep Dry (BDD) dataset. And then later they try to adapt to a new domain, which is the CityScapes domain, using a different adaptation methodology. The result is that this interactive approach through ARA actually outperforms all these other approaches, which is basically just: train the model once or through a model adaptation approach. The performance gain is actually pretty significant here, as you can see.
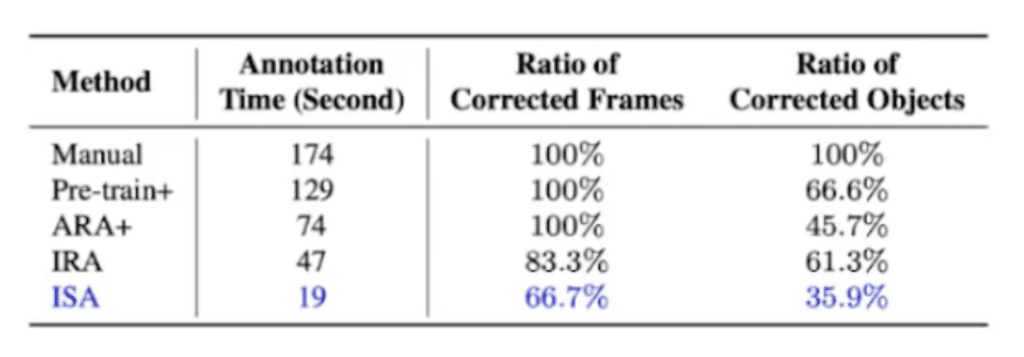
With IRA evaluation they look at a different dataset, which is the dashcam accident dataset. What they found out is that the entire ISA framework involving both ARA and IRA is nine times faster than the manual annotation. (Manual annotation basically means that you ask humans to annotate, frame by frame, all objects.) They also concluded that on average running through the entire process takes about 19 seconds, whereas ARA takes about four seconds and IRA takes about 15 seconds. Which makes sense because IRA involves human-in-the-loop. ISA also requires the least amount of correction by the human, eventually.
They also observed that the benefit of the first phase, automatic recurrent annotation, compared to just applying the IRA without the ARA, is still 2.5 times faster, and they also reduced the corrected object ratio significantly. They’ve observed that the benefit of IRA is that if you apply the second phase, meaning human-in-the-loop, ISA is still 3.9 times faster than just applying ARA. And it also reduced the ratio of corrective frames significantly.
Overall, involving human-in-the-loop with this very careful design, with a combination of automation tools, plus involving humans at the right time making only the necessary corrections, greatly improved the model performance as well as the result and the amount of human annotation.

Quickly moving on to the next example: applying human-in-the-loop to NLP tasks. This is a task to perform interactive, semantic parsing. Semantic parsing aims to map natural language through formal domain-specific meaning representation, such as knowledge base or database queries, API calls, and general purpose calls.
In this particular example, we’re looking at if-then recipes. And if-then recipes allow people to manage a variety of web services with physical devices and ultimate-event driven tasks. This work focused on recipes from IFTTT, which stands for “if this, then that,” where a recipe has four components, which are: trigger channel (tc); [trigger] function (tf); action channel (ac); and [action] function (af). So to the right, there’s an example. A user can just provide a brief description of the task, which is “create a link note on Evernote for my liked tweets,” and that should be parsed into the recipe that has the four components. And this is an important step toward a more complex natural language programming task.
However, natural language description can be very noisy and ambiguous, or lack enough information. Prior work usually focused on just doing the parsing in one turn, and here to the right, at the bottom, we can see an example of a very vague description. The user simply says “record Evernote.” However, the ground-truth label still includes the trigger channel and trigger function, which is basically missing from the user description. And the prior state-of-the-art one-turn model cannot accurately predict or parse what the triggers are, which is understandable because it’s missing from the user description. So, the proposed approach is to apply hierarchical reinforcement learning and involve a human in the loop to provide the necessary information for the agent to be able to parse ambiguous descriptions into a well formed recipe.
So the challenge here is: when should the agent ask the user a question? And the next challenge is: how do we ask a minimum number of questions? After all, involving humans is very expensive and we also want to provide a good experience for humans. And so we want to minimize the interaction to the extent possible.

To quickly look at the result that gets produced: they try out two different agents, implemented through hierarchical reinforcement learning. The agent on the left follows a fixed subtask order, which means there’s no high-level policy learning. And the agent on the right follows a two-level hierarchical policy. As you can see, the agent on the right is the most efficient agent, which basically just focuses on the missing information. It identifies that the triggers are missing, and it’s asking only two questions to be able to accurately parse the very vague description into the ground-truth label.
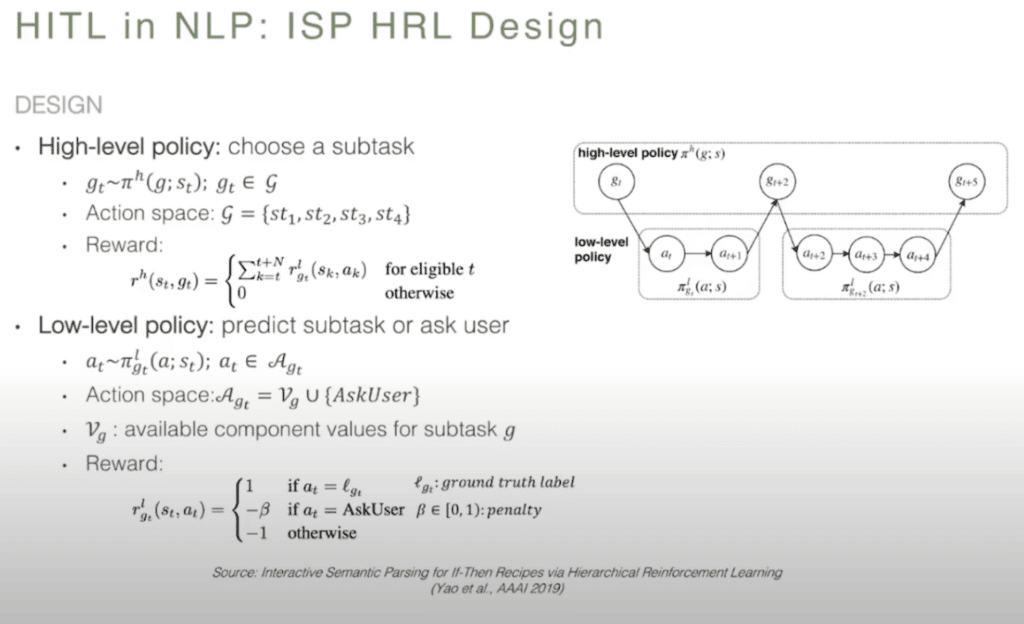
Here’s the high level design of the HRL algorithm. The high-level policy predicts the subtask, basically it has one of those four predictions to make. Either it is the trigger channel function or the action channel function, and it determines which subtask to tackle first. Whereas these lower-level policies focus on predicting the subtask or deciding [whether] to ask the user a question.
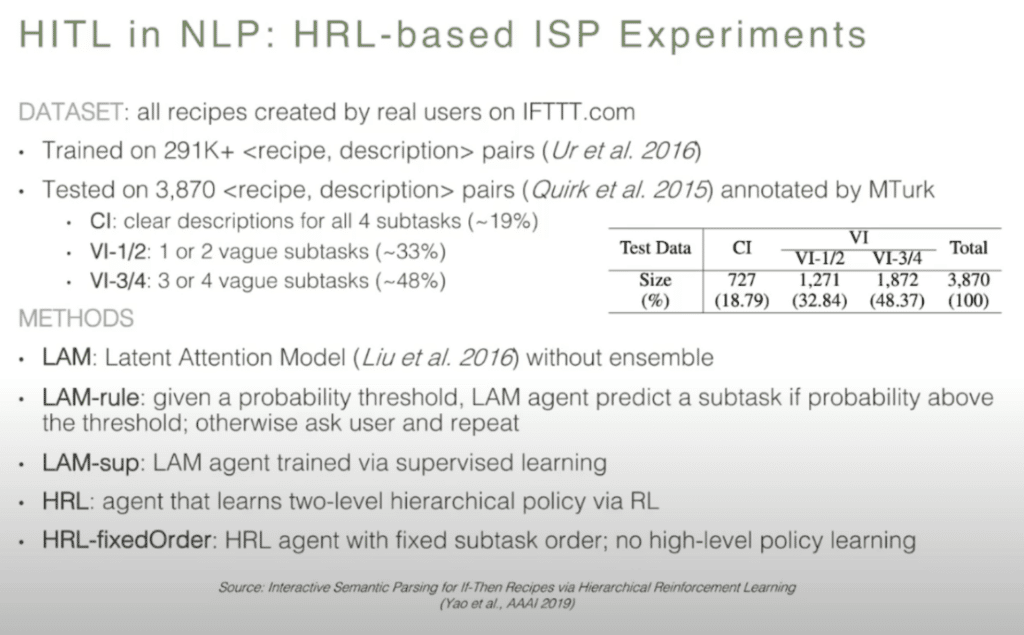
So, the experimentation setup: they use the dataset. All the recipes are actually created by real users from the IFTTT website. Interestingly, over 80 percent of the descriptions are very vague. The study they did was CI, which means that there’s a very clear description provided, and VI 1/2 or VI 3/4 means that there’s some vagueness in the description. They apply different approaches, including the baseline approach, which is the latent attention model, which was state-of-the-art prior to this study, and then they created four other agents to simulate the intact action with a human and produce a valid result.

So, the experimentation setup: they use the dataset. All the recipes are actually created by real users from the IFTTT website. Interestingly, over 80 percent of the descriptions are very vague. The study they did was CI, which means that there’s a very clear description provided, and VI 1/2 or VI 3/4 means that there’s some vagueness in the description. They apply different approaches, including the baseline approach, which is the latent attention model, which was state-of-the-art prior to this study, and then they created four other agents to simulate the intact action with a human and produce a valid result.
So, very quickly, they implemented a user simulation module because involving humans in the actual interactive training process is very costly. They also evaluated all the different models or agents based on these metrics. “C+F accuracy” means that all four components are properly predicted. Whereas “overall accuracy” will allow for some of the subtasks [to] be mispredicted. They also look at the number of questions, on average, asked of the human labeler or annotator.

So, a quick summary on their evaluation: We can see that all agents outperform the previous state-of-the-art model, which just does the prediction with one turn overall. The two HRL-based agents perform much better than non-interactive models. And they tend also to handle the ambiguity better, looking to the right two columns with the VI 3/4 sections of the data. Clearly the HRL agent is smarter in asking fewer questions and achieving better accuracy in this parsing.

So with that, let’s quickly look at some of the directions that human-in-the-loop AI should start exploring.
One is, it will be beneficial to start collecting and sharing more human feedback datasets for different tasks. So, more researchers and practitioners should start leveraging these datasets, also, for more complex feedback mechanisms, rather than just very superficial judgments. Finally, we need to apply human-centered and human-computer interaction design principles to human-in-the-loop ML design.
With that, I’ll conclude the talk. Thank you.

Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

