Paroma Varma, co-founder at Snorkel AI, and Ali Arsenjani, director of AI/ML partner engineering at Google, discussed the role of data in the development and implementation of LLMs. These models don’t work out of the box, they noted, particularly for enterprise applications. Customization is crucial, and injecting unique organizational data (their ‘secret sauce’) into these models can help tailor them for specific use cases.
The conversation, edited for reading clarity, included notes about how much time data scientists spend preparing data and the responsibility that comes with using AI. Ali and Paroma also focused heavily on the need for specialized models for different verticals or sub-verticals.
Paroma Varma: I’m super excited to have Dr. Ali Arsanjani with us today. He’s the director for AI and ML partner engineering at Google. Google has set the foundations for all the work that’s happening with LLMs today, and Snorkel is incredibly proud to be a Google partner. We appreciate all the support that we’ve had during our partnership, going back even to the early days when Snorkel was a research project.
Thank you so much for spending the time with us and welcome, Ali.
Ali Arsanjani: Thank you so much, Paroma. It’s such a pleasure to be here with you and talk about how we deliver value to our mutual customers.
It’s very exciting to talk about these things, especially in these times that are crackling with energy around generative AI. People are trying to figure this thing out, and I’m really glad you’re doing this event.
PV: Wonderful, and you said it exactly right. Things are crackling with energy right now around the world of generative AI.
We’ve seen a cycle in the past few months in which people went from thinking that generative AI will solve anything and everything to actually trying it out, and realizing that it’s not actually “one click to solve all problems.” There has to be some work, some customization performed on these large language models before they can be used for real-world use cases. This is especially true in the enterprise—something you’re very familiar with. We’d love to get your thoughts on the forms that this customization has taken.
AA: Absolutely. Every enterprise considers their data to be their “secret sauce.” They painstakingly gather information—whether it’s from their own systems or systems that are related to what they do—and it is their intellectual capital and asset. Often, these large language models are not privy to specialized domains.
Every enterprise considers their data to be their “secret sauce.”
Ali Arsenjani, director of AI/ML partner engineering at Google.
Infusing that industry-specific data into the expertise that these large language models provide is absolutely essential to providing a competitive advantage. Without that data “secret sauce” that every company has, they lose their competitive edge when they get to large language models, because they do not reflect their specialized, domain-specific knowledge.
The idea is to infuse that knowledge with the data. I know Snorkel does a lot to prepare that data so that models can be trained, leveraging your data.
PV: That’s exactly right. I think we’ve always had a belief that data is at the center of the AI development process. Like you said, it’s never been truer than today, when you have these models with millions of parameters that are difficult to tweak. The main lever—the main competitive advantage, as you put it—these enterprises have is in infusing their domain expertise and their knowledge into these large generic models via the data that is unique to every company and every organization.
One thing associated with the data is the idea of domain expertise. Large language models are more general, and they’ve been trained on a lot of generic data that is out there in the public domain.
Have you seen people interested in making these large language models a bit more niche in learning domain-specific factors? Where has that been popular and how have people been addressing that need?
AA: I see a lot of interest in taking that domain-specific knowledge and creating domain-specific models from it.
Fine tuning these foundation models in some way is very popular, whether it’s using adaptive tuning, or low-rank adaptation, or some other form of parameter-efficient fine tuning. You don’t have to build and maintain an entire model. You can have a lightweight model and still infuse the jargon, ontology, knowledge graphs, and data that are unique to your subsector into the language model. And, you can do it in a way that allows you to query it and get results that are relevant to your domain. That’s one quite positive direction that people are taking.
I see a lot of interest in taking that domain-specific knowledge and creating domain-specific models from it.
Ali Arsenjani, director of AI/ML partner engineering at Google.
I’m going to also balance that out with some misconceptions that some people have, because this area is so nascent. People generally think that they need their own completely-fine-tuned models. I’m not sure they realize that fully fine tuning these models can be relatively expensive. And the deployment of these models, if they end up being large models, is not very cheap either. But, if you do a form of parameter-efficient fine tuning, and you can fail fast, you can find the domain initially in which this works well. Then, if you want to fully fine tune the model later once you’re clear on exactly what the value proposition is, then you can do that.
A second misconception is what I’ll call the “Lord of the Rings” misperception because it’s the notion that “one model will rule them all.” People will come to us and say, “when are you going to come out with your latest model?” But these models are improving constantly. They’re being trained every few months. For specific domains, one model will not typically rule them all. It’s going to be a number of smaller models that are for very specific domains.
Even within one company, you have different sectors or subsectors. Think of financial services. You have banking, you have financial markets, you have consumer lending. These are niche areas. Of course, for each of them you can tune a large model. But when you want to have specialized dialogue with them, it might be a good idea to test the parameter-efficient fine tuning for that specific subsector. You can derive a lot of value just from doing that.
PV: We at Snorkel are very aligned with what you are saying, that trade-off. Yes, we want the largest model, but sometimes there are cost and infrastructure challenges associated with getting that model. But you can have these specialized models, even within one area, like financial services, for example. There’s a specific set of models you need for each unique task that you want to do within that area. We think it’s really these smaller, specialized models that are going to be the future of LLMs and of how they will be put into production in the enterprise.
This reminds me, there are a lot of techniques out there for folks to work with LLMs, whether it’s prompting, RAG, fine tuning, which we were just talking about. How would you recommend practitioners think about the differences between these techniques and which ones they should be using, and when?
AA: I have a couple of pictures I want to show—a picture is worth a thousand words! If I can project these pictures, I think they might be helpful.
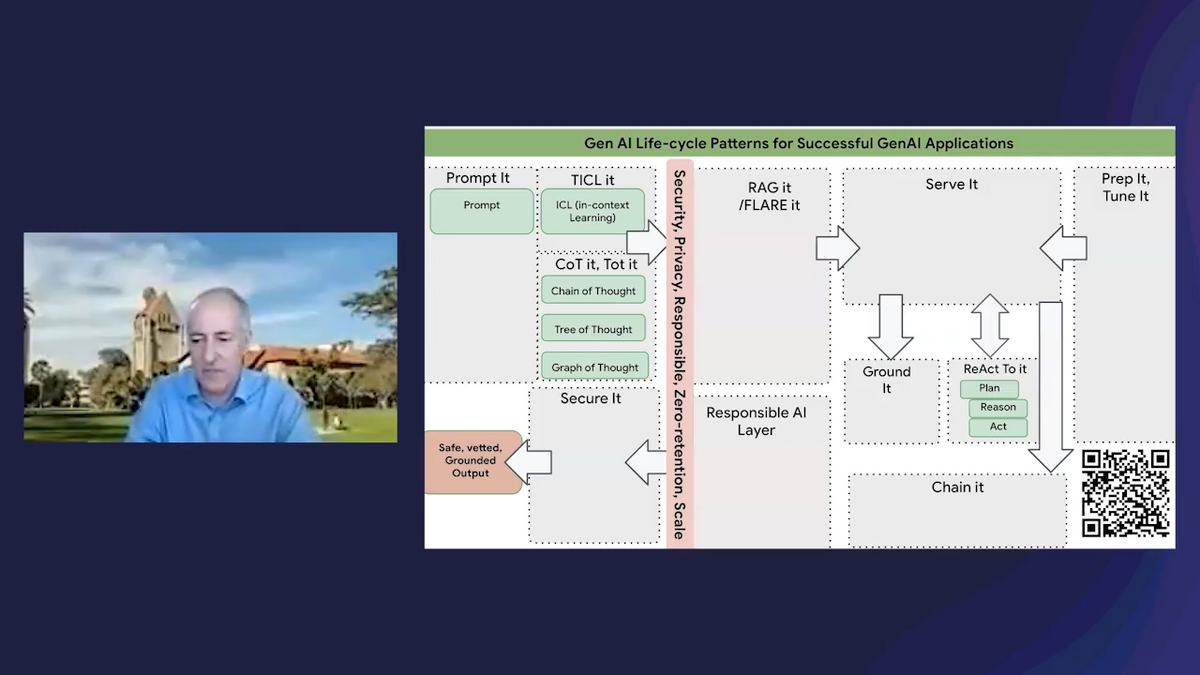
You have these different “patterns,” almost, that you need to implement as you take the journey for generative AI. You don’t necessarily have to implement all of them at once. But this is the superset.
You typically want to prompt models. You want to do some in-context learning with few-shot examples. You might try additional techniques like chain-of-thought, et cetera. But these are all within the realm of prompt engineering.
And then, on the side of serving, you can serve different models. You can serve foundation models, customized models, et cetera. You could get away with just doing prompting and serving these models immediately. But there are a lot more things that are involved as you move toward more and more sophistication in this world.

If you look at this image, it shows different levels of maturity or sophistication or requirements. The first one is just “prompt and serve.” You go to bard.google.com, you enter in something, and you get a response back. That’s it. Or go to, for example, Vertex AI, for a secure, enterprise-production-grade environment. You ask a question and the PaLM-2 model gives you a response. Great. You’re done.
The next step is providing contextual information. The model was trained at some point in the past. You’re in, let’s say, San Francisco today and you want to plan a bike ride, but the model doesn’t know where you’re at or what the weather is like. Maybe it’s a bad idea because it’s raining. So, you want to give the model a little bit more context. Where are you? What does the weather look like? What are your preferences? Do you want to go riding on steep hills or just normal road bike riding? This is retrieval augmented generation (RAG), for you to actually retrieve additional information that might be relevant because you: extract content, go to the APIs, get information about the weather, about the location, about your preferences. You provide the contextual information (along with the prompt) to the model, and now the model can make more sense of it.
A second misconception is what I’ll call the “Lord of the Rings” misperception because it’s the notion that “one model will rule them all.” …For specific domains, one model will not typically rule them all. It’s going to be a number of smaller models that are for very specific domains.
Ali Arsenjani, director of AI/ML partner engineering at Google
The third level could be, “Okay, great. I have the context,” but let me give you an analogy. Let’s say that you are not a physician, and you are going to be asked to see someone for a particular set of symptoms. You’d say, “why me? I’m not a physician.” So, they’ll say, “no problem. Take all of these textbooks, read them over the weekend, and you’re now suddenly a physician.” What are you talking about? That’s impossible. Even if you do RAG—you read all those books—you’re still not a physician.
You have to tune these models. The analogy here would be, if I only know a certain amount of things, I still have to go to medical school and I have to be trained to become a physician. You can tune your model, you can essentially customize your model and train that model in order to know that new domain and understand how to produce specific outputs. That’s level 3. You’re using RAG, but you’re also tuning models for special purposes.
Level 4 is when you’ve done that tuning, you get a response back, but you’re not quite sure whether this response is real. It may be hallucinating! You want to ground the response with factual grounding. You want to do some kind of a search, whether it’s internal documents within your organization or out there on the internet, and bring back citations. The language model is saying, I gave you this answer, and here are the references. You can click on the references and see if this answer is true.
Then, of course, levels 5 and 6 are just more sophisticated, with controlling the LLM in various ways, providing reasoning, acting, planning, and doing LLM ops.
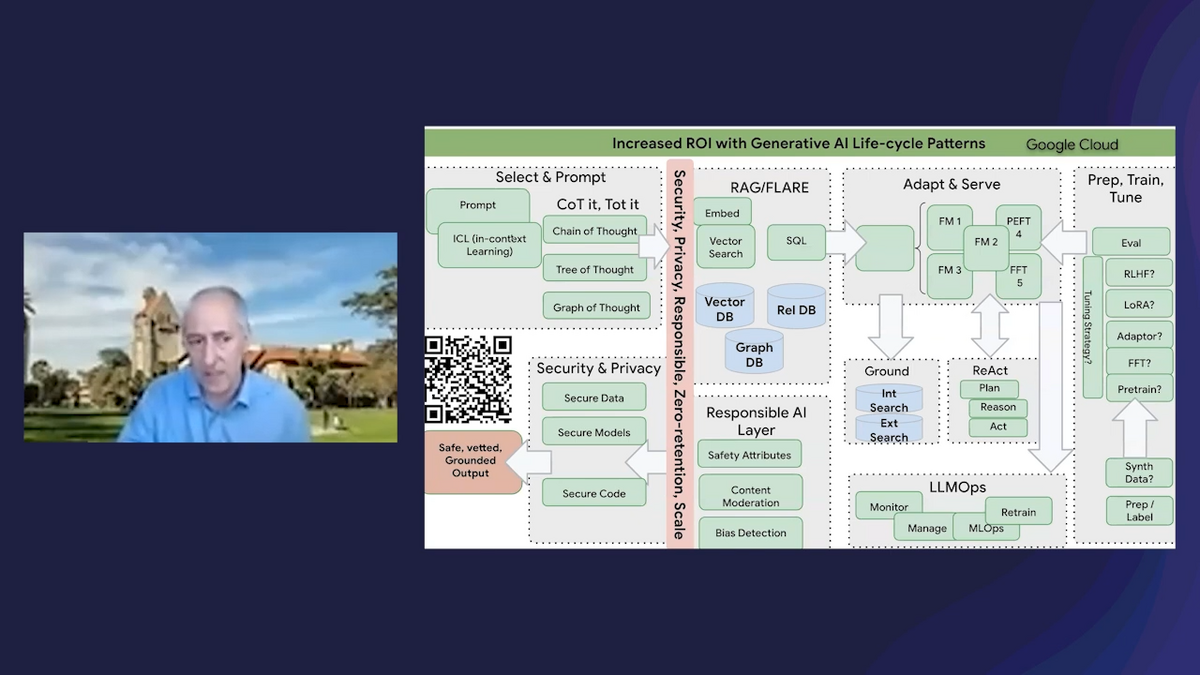
I won’t go into that very specifically, but basically this diagram represents all of what we just discussed, the superset, the whole nine yards. You don’t have to implement all of these at once, but you do have to consider the tradeoffs as you’re going through this journey. There’s the prompting. There’s the RAG. There’s the tuning. There’s the adapting and serving. There’s the grounding. And, of course, you want your outputs to be responsible. You want to check for biases, safety attributes, and you want to be in a secure environment to begin with.

If people want to know more about that, they can take a picture of this QR code and read a blog about it.
PV: Like you said, a picture paints a thousand words. The visual framework that you just provided really drives home the point that there’s no one “silver bullet.” It’s truly a combination of various techniques that appear at different parts of the LLM development and customization pipeline that bring models to where they’re production-ready, where it’s something that you trust, where it’s something that’s aligned and customized to the data and the domain expertise that you have.
This leads into another topic that we wanted to touch on. As we know, these large models don’t work right out of the box with one click. There’s a lot that goes into making them possible. How do you see our shared customers benefiting from the partnership that Google has with Snorkel AI, especially in this landscape that you just laid out?
AA: That’s a great point. That’s a topic I love talking about because it’s the “better together” story. It’s how our companies, working together, can better serve our customers. As you know better than anyone, Snorkel has a whole set of products and provides expertise for specific areas of the ML lifecycle. Of course, you can do the whole thing, but you provide huge amounts of value add, for example, in preparing the data for machine learning training, in labeling the data, in understanding whether there are biases in the data, whether the distribution of data can affect something in the future.
As we know, 80 percent of data science is preparing and validating the data properly. Snorkel provides immense capabilities in that area. And then you can go ahead and tune and deploy on Vertex AI, and ground it, and perform RAG, and all those other things.
Those are some areas that, in combination, customers can use our companies together to augment the ML lifecycle with the specific expertise that we each bring to bear at each stage, in order to prepare data better and position themselves for these domain-specific models, for retrieval augmentation, for grounding, and those sorts of things.
80 percent of data science is preparing and validating the data properly.
Ali Arsenjani, director of AI/ML partner engineering at Google
PV: Thank you so much. It’s always wonderful to hear your perspective on where Snorkel plays a role. One example: Wayfair, one of our joint customers, has taken advantage of our amazing partnership, even on the technology front. Developing their data helped them achieve significant gains with the model that they eventually put into production. We have a blog on our website if folks are interested in learning more about that story.
One last question for us to get into, and it will be a fun one. What is one thing that you’re excited about with the advent of large language models, and what is one thing that you are perhaps not so excited about, or a little bit worried about?
AA: Honestly, the thing that I’m a bit worried about is that the game of generative AI is going to become similar to what the situation is now with antivirus software. If a person uses large language models, they can gain huge productivity. And if they’re doing good stuff, that productivity is going to be good productivity. But if some bad actor utilizes large language models, et cetera, it’s going to create more productivity for them, which is not necessarily good for mankind. That’s what worries me.
Our companies are putting in more guardrails, more safety factors, more checks and balances [to avoid this]. For example, when you send an LLM a message with Google, you get a bunch of safety attributes. You can threshold on them to see: is this something that I want to actually show to my customers? We have a content moderation API, which allows you to vet whether some input is toxic or not. Doing factual grounding, etc. These all help. But at the end of the day, it really is the entire community’s responsibility. We all need to come together, and there will need to be legislation, ultimately, put in place that aims to decrease the ability of bad actors to use language models.
But I’m very excited at the same time because if you put this into good hands, so to speak, we’re all going to be more productive and we can do more, better, faster, and lead more productive lives. At the same time, we can maybe find more time for ourselves and our families and our loved ones and friends, and do things that are not just our day job, but that contribute to humanity.

PV: I really like that perspective and couldn’t agree more. Using AI responsibly is something that everyone should be very aware of and care about and contribute to. Let’s make sure it happens that way.
With the good productivity gains, like you say, I’m excited to see what happens there. A lot of folks have found very interesting ways of using these large language models in their daily lives to improve various workflows—in our day jobs but also outside of work for our hobbies and other interests. It’s going to be fascinating to see what develops, both on the work side and more creative side of the world, with large language models.
Thank you again, Dr. Arsanjani, for this wonderful conversation. My three takeaways, if I had to mention them, were:
- These large language models rarely work out of the box, especially for enterprise applications. Data, as you said, is the “secret sauce” for enterprises and organizations to inject their specific expertise into these large models and make them work for their particular use cases of interest.
- With your visuals, we saw how there’s no one “silver bullet” for making sure that these large language models work for the use cases at hand. Success really depends on knowing what combination of techniques to use; how much you need to customize your model; and when to use RAG, versus prompting, versus fine tuning, and which one is important for which use cases. There’s really an art to it, and that’s something that we’ve been working on together and that Snorkel’s been super excited about.
- And for the last one, I liked your idea that there’s no one model that’s going to “rule them all.” There will be these specialized models—and not just for various verticals, like finance, but even within verticals—that will have to be fine tuned for the specific tasks that users want to do. The models will have to be fed data that’s specific to that organization and that specific use case.
Again, I really enjoyed the chat! Thank you so much for your thoughts and you’re wonderful visuals on this topic. Those really drove home the points that we talked about.
AA: Thank you so much for having me! It’s always a pleasure. Appreciate it.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

