Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Task Me Anything: innovating multimodal model benchmarks
The proliferation of multimodal foundation models has enabled new capabilities in image recognition. However, different models have different strengths. Data scientists can struggle to determine which models to consider for their application—or even how to assess them. That’s why my colleagues and I at the University of Washington developed “Task Me Anything.”
This innovative solution allows users to generate bespoke benchmarks tailored to their needs.
I recently presented my work to an audience of Snorkel researchers and engineers. You can watch the entire talk (embedded below). I have also summarized the main points here.
Task Me Anything: Addressing the benchmarking dilemma
The AI community has developed a variety of benchmarks to measure multimodal model performance. This can make it difficult for data scientists to identify the right benchmark for their task—never mind the right model.
“Task Me Anything” tackles this head-on by providing a user-centric generative benchmark creation system.

Key features:
- Programmatic benchmark generation: Task Me Anything programmatically generates tasks and measurements, ensuring accurate and relevant metrics for your tasks.
- Combinatorial task space: The system builds tasks by combining libraries of questions, objects, and conditions—which can expand to fit new use cases.
This approach produces benchmarks aligned with the users’ unique requirements, easing the process of selecting the right model for the project, and then prioritizing data development for fine-tuning.
The Task Me Anything workflow
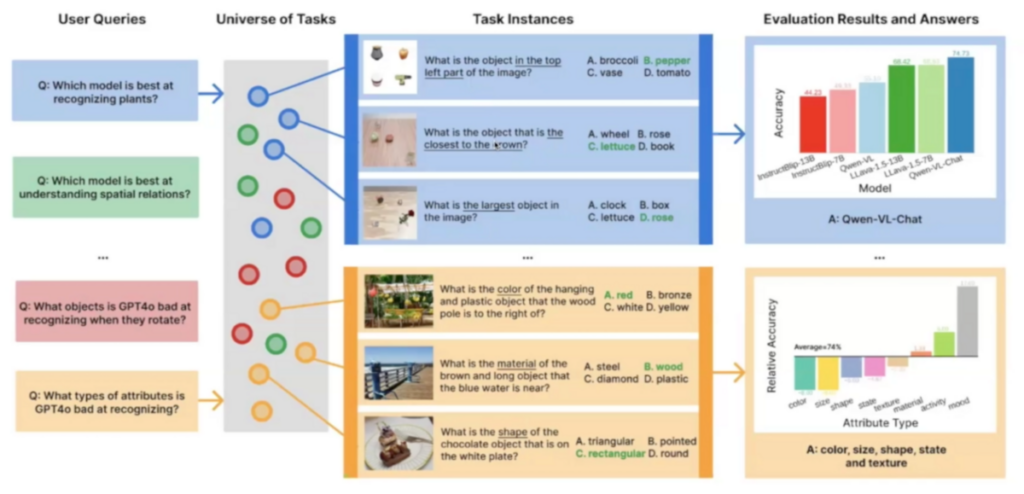
Using Task Me Anything follows a four-step process—from determining user queries to evaluating the model.
- Step 1: User queries. Users input their queries. These could range from determining which model best recognizes airplanes to which objects GPT-4 struggles to identify when rotated.
- Step 2: Task identification. Users identify relevant tasks to generate from Task Me Anything’s task space. These include visual concepts, objects, attributes, and relationships.
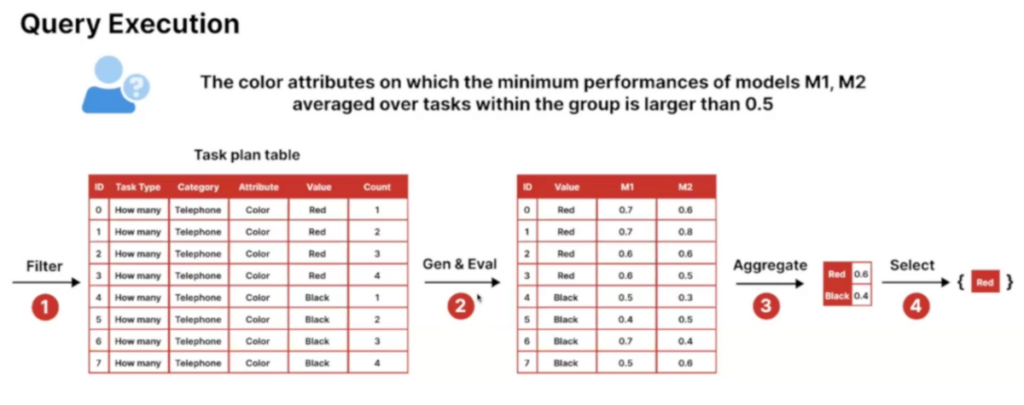
- Step 3: Task generation. The system generates tasks programmatically based on Python dictionaries known as task plans. Tasks often follow a visual question-answering format, combining images, questions, choices, ground truths, and negative answers.
- Step 4: Model evaluation. With tasks generated, the pipeline evaluates models against the custom benchmark.
Users can run through this pipeline multiple times to fulfill different needs. They may use their first run to select which model most closely matches their use case and begin fine-tuning it. They may use later runs to identify where their model falls short and prioritize data development efforts.
Digging deeper: technical details
The Task Me Anything process starts with detailed task plans. These plans serve as blueprints for which objects of interest, task types, and other attributes to include in a task.
With a task plan established, the pipeline will use appropriate software to build the final task— for example using Blender to generate realistic 3D scenes that include varied coffee cups in different orientations. This creates a challenge for easily-measurable outcomes for models’ recognition capabilities.
The system’s task space includes:
- More than 300 object categories.
- More than 600 attributes.
- Around 300 relationships.
- 28 task generators.
Combining these elements, Task Me Anything can generate over 700 million unique tasks. Users can apply these tasks to answer the following kinds of questions:
- Top K: Identify the top K objects a model struggles to recognize.
- Threshold queries: Determine objects or attributes a model struggles with, based on a specified accuracy threshold.
- Model comparison: Compare two models to highlight the areas where one outperforms the other.
- Model debug: Pinpoint tasks where a model’s performance drops significantly below its average, facilitating targeted debugging and improvement.
Using active learning for efficient approximation
Teams using Task Me Anything typically have a limited budget for model evaluation. They cannot examine every task in detail. To get around this, Task Me Anything leverages approximation techniques to evaluate models efficiently and effectively.
As a baseline, the pipeline randomly selects a subset of tasks for evaluation. From that random sample, a second stage trains a machine learning model to predict performance on the remaining tasks. A final active learning step takes the approximation a step further by iteratively evaluating a small batch of tasks, training a predictive model, and using this model to guide subsequent evaluations.
Together, these three stages ensure the optimal use of limited evaluation budgets.
Real-world applications and findings
Through extensive testing, Task Me Anything has yielded significant insights into the performance of multimodal models. Here are some key findings:
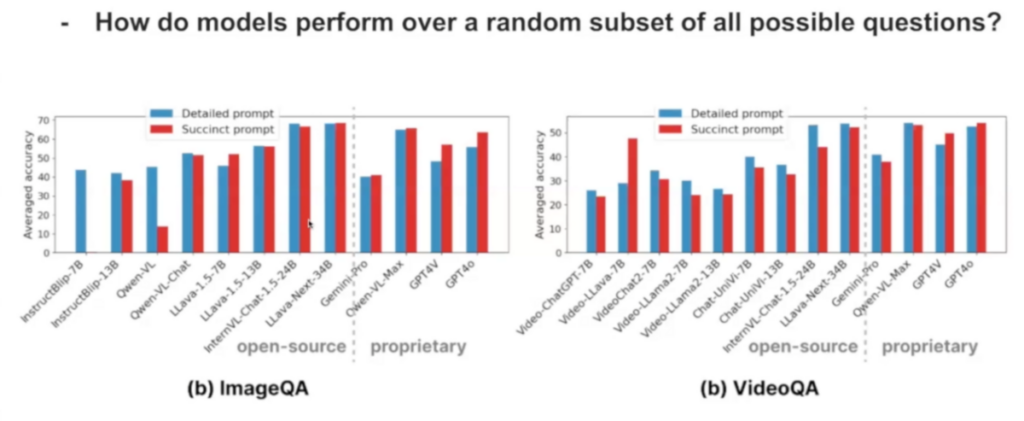
- Sensitivity to prompts: Models exhibit a high degree of sensitivity to the design of prompts. Models like GPT-4 tend to perform better with concise, human-like prompts, while smaller open-source models may respond better to more detailed instructions.
- Differing strengths: Through our nuanced breakdown of tasks, we’ve found that different models achieve different strengths. Some excel in recognizing spatial relationships. Others perform better in identifying interactional relations.
- Large vs. small models: Generally, larger models outperform smaller ones. However, we found exceptions in specific areas, such as relational recognition.
- Struggles with specific objects: We identified that specific attributes and objects challenge specific multimodal models. GPT-4 tends to better recognize animals in motion than furniture and plants when rotating.
Find and customize the right model faster with Task me Anything
Task Me Anything offers flexibility and precision in benchmarking multimodal models. It empowers users to generate custom benchmarks aligned with their specific needs and provides valuable insights into model capabilities. This system not only addresses current benchmarking challenges but also sets a framework to assess future research and development in AI.
This framework is also extensible. We already have plans to add assets to address domains like math, healthcare, and 3D vision.
For developers looking to identify and fine-tune the best foundation model or large language model for their application, Task Me Anything offers the tools necessary to make well-informed decisions.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Jieyu Zhang
Jieyu Zhang (https://jieyuz2.github.io/) is a PhD student at the University of Washington. His research interests include data-centric AI and agentic AI. He has published multiple first-authored papers in NeurIPS, ICLR, ICML, and so on. He is a recipient of the Apple AI/ML Scholarship and OpenAI Superalignment fellowship. His work has been awarded as the best paper at the LLM Agents workshop @ ICLR 2024 and the best paper at ICDM 2020.