
Read on to see how Google and Snorkel AI customized PaLM 2 using domain expertise and data development to improve performance by 38 F1 points in a matter of hours.
In the landscape of modern enterprise applications, large language models (LLMs) like Google Gemini and PaLM 2 stand at the forefront of transformative technologies. LLMs are already revolutionizing how businesses harness Artificial Intelligence (AI) in production. While LLMs are an incredible starting point, they often require some level of customization to address tailored, domain-specific use cases while delivering the accuracy required to deploy in production.
The main lever for optimizing LLMs and delivering both production-level accuracy and competitive advantage lies in a company’s own data. Developing AI applications has traditionally been a linear, “model-centric” process in which machine learning models could be optimized by tuning specific parameters. That’s simply not feasible with multi-billion parameter LLMs. Enterprises that build and use LLMs for complex, business-critical AI applications must continuously monitor, evaluate, and update their models using their data.
In an ideal world, every company could easily and securely leverage its own proprietary data sets and assets in the cloud to train its own industry/sector/category-specific AI models. There are multiple approaches to responsibly provide a model with access to proprietary data, but pointing a model at raw data isn’t enough. Data often needs to be developed further—cleaned, filtered, sampled, labeled, and sliced—to prepare it for customized LLMs. Human expertise (and often specific domain and company expertise) is required to curate valuable human-generated data and filter out the noise.
This is where Google Cloud’s partnership with Snorkel comes in.
Google has established itself as a dominant force in the realm of AI, consistently pushing the boundaries of AI research and innovation. Google’s thought leadership in AI is exemplified by its groundbreaking advancements in native multimodal support (Gemini), natural language processing (BERT, PaLM), computer vision (ImageNet), and deep learning (TensorFlow). These breakthroughs have paved the way for transformative AI applications across various industries, empowering organizations to leverage AI’s potential while navigating ethical considerations.
Vertex AI, Google’s comprehensive AI platform, plays a pivotal role in ensuring a safe, reliable, secure, and responsible AI environment for production-level applications. Vertex AI provides a suite of tools and services that cater to the entire AI lifecycle, from data preparation to model deployment and monitoring. By integrating robust security measures, promoting transparency through explainable AI, and adhering to stringent ethical guidelines, Vertex AI empowers businesses to develop and deploy AI solutions with confidence. Its focus on reliability ensures that AI systems perform as expected, mitigating potential risks and fostering trust in AI-powered solutions.
Snorkel Flow is an AI data development platform built with Google Cloud AI that allows users to programmatically develop data to build and adapt AI models dramatically faster than manual methods. Using domain-specific data and subject matter expertise, data scientists can optimize Google LLMs by systematically identifying error modes and working with internal experts to programmatically develop data to address those efficiently.
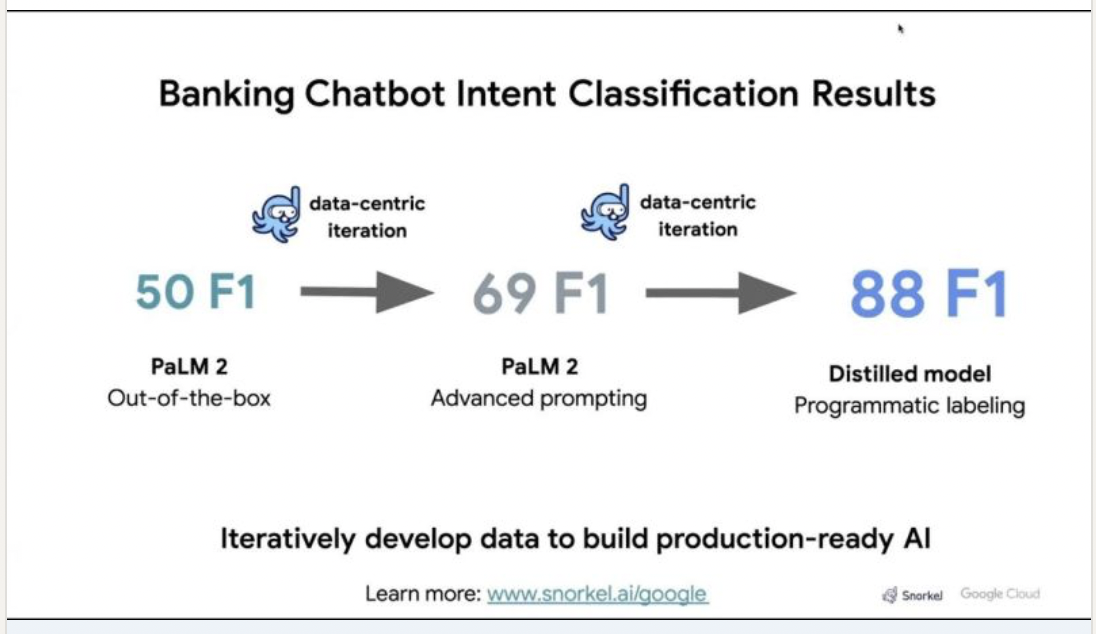
Google and Snorkel recently collaborated on an iterative approach to customizing the PaLM 2 LLM with proprietary data, internal expertise, and multiple data-centric techniques using Snorkel’s platform.
With just a few hours of data development, the team was able to build a model that achieved production-level performance and a 38-point F1 score improvement over an out-of-the-box version of PaLM 2.
This demo steps you through the iterative approach and we cover the steps in detail below.
Case study: Banking Chatbot Intent Classification
This example was inspired by real-world projects undertaken by financial institutions that worked with Snorkel AI and Google. It is centered on a fictional bank that wanted to improve its customer service chatbot to reduce friction for customers on self-serve tasks such as finding out when their new ATM card should arrive.
The use case uses the banking77 dataset, which involves classifying freeform responses using 77 pre-defined customer intents. Some intents are much more common than others, while certain rare classes carry outsized importance. This use case mirrors real-world AI projects involving classification and extraction with up to 1000 classes that require expertise and data unique to the enterprise to achieve production-level performance.
The data development lifecycle
We’ll walk through steps that a data scientist follows when using LLMs and further customizing them for a domain-specific use case via data development.
This iterative process includes using and evaluating the performance of PaLM 2 out-of-the-box, identifying error modes and further prompting the model to refine its outputs, and using Snorkel’s systematic error analysis to develop data to improve overall performance.
Before these iterative steps, the first action is to import and access unstructured data stored in Google Cloud from the Snorkel Flow platform via a native Google Cloud BigQuery connector.
Step 1: Evaluate out-of-the-box PaLM 2 model results
As with many AI applications today, the first step is to run and evaluate an LLM over the task of choice. We started with a pre-built prompt template in Snorkel Flow connected to PaLM 2. This template includes a placeholder for a customer utterance along with a request that the model assign the utterance to one of the 77 intent classes.
Snorkel Flow integrates with Vertex AI Model Garden to send the request to Google’s PaLM 2 Bison API, then receives the response and extracts the model’s prediction for data scientists to analyze.
In this demo, for certain utterances the model’s predictions fell outside of the established schema provided in the prompt. Hallucinations like these remain a challenge with generative models, even the best-of-the-breed models. As a default, Snorkel Flow maps these responses as “other” or “unknown” with an option for users to programatically map predictions to the relevant set of classes using heuristics.
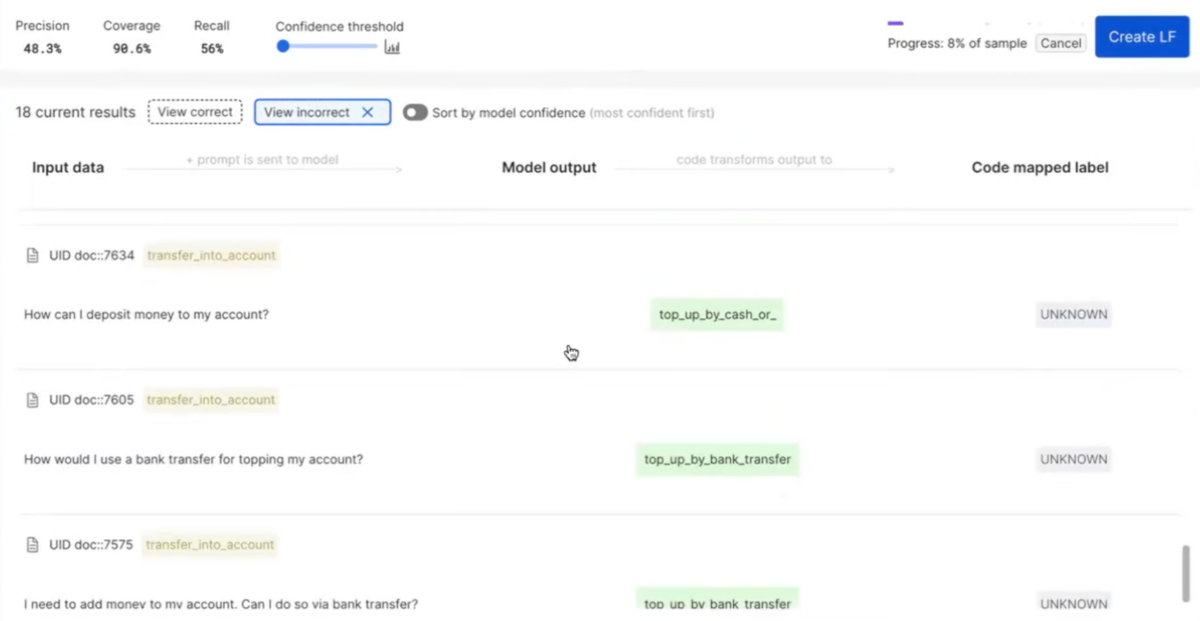
This initial pass using PaLM 2 achieved a score of 50 F1. That’s solid out-of-the-box performance with a simple prompt, but nowhere near our fictional bank’s minimum threshold of an 85 F1.
Step 2: Guided Error Analysis
With data science workflows, the next step is usually somewhat ad-hoc. Data scientists try different techniques to find where the model is incorrect and identify ways to adjust those errors whether via the model or the data. However, this process can feel like whack-a-mole and be tedious.
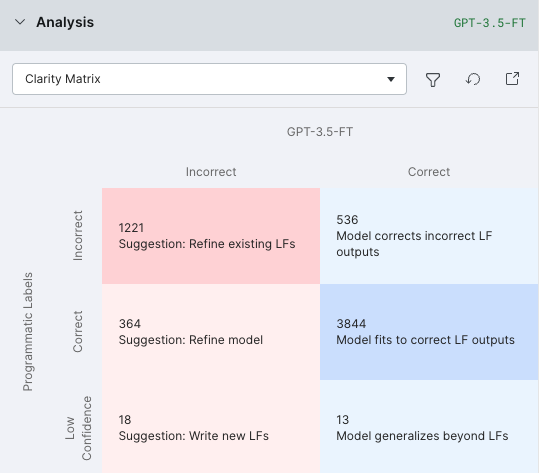
With Snorkel Flow’s guided error analysis tools, data scientists are able to identify the exact slices of data where the model isn’t performing well and systematically point the user to the next actions that will help address those issues.
Once we had initial predictions from the PaLM 2 model, we used error analysis tools like the Clarity Matrix to identify the most common types of errors the model was making. This helped visualize and understand how to further prompt the model so it didn’t make these mistakes.
Step 3: Advanced Prompting
Using the guidance from the error analysis tool, we experimented with prompting techniques such as chain-of-thought reasoning to fix some of the mistakes the base model was making. We were able to take advantage of Vertex AI rate limits to parallelize multiple such experiments simultaneously, speeding up iteration by up to 10x.
Surprisingly, the F1 score declined. Using analysis tools in Snorkel Flow again, we investigated and found that some of the ground truth labels in the evaluation set were wrong. Noisy data is a well-known limitation of the banking77 dataset and not uncommon with human labeling. One of the first cases the Snorkel team worked on had 30% noisy ground truth, which is why the tags feature was added to the platform.
We used Snorkel Flow to efficiently identify and amend incorrect ground truth. Our team filtered for rows where the model made confident predictions that disagreed with the ground truth labels to identify where the evaluation data was off.
With these corrections in place and advanced prompting, our engineered prompts achieved a 69 F1.
Step 4: Contd. Error Analysis and Programmatic Data Development
At this point, error analysis tools pointed to errors that were only addressable via the data that the model relied on. For example, the model had to learn that questions about tracking cards and shipping issues should be tagged “Card Arrival.”
Instead of throwing the work done with LLM prompting away, we can continue using its predictions as a source of labels and continue improving the model’s performance by developing the data the model relies on. One approach is to manually label data. Identifying the utterances to label, which can be in the millions for real-world use cases, can take months.
With Snorkel Flow, this labeling process can be done programmatically. This process uses labeling functions, which are snippets of code that harness sources of signal to apply a label. Sources of signal can be something as simple as a binary substring search (“does this document contain the string ‘account balance?’”) or as complicated as external ontologies, vector embeddings, or responses from a prompted LLM like we did in this case.
Our programmatic labeling pipeline uses weak supervision to sort through the different sources of signal and apply a probabilistic label to each data point for which it has at least one signal.
Snorkel Flow users start with a small number of labeling functions, then iterate to improve model performance. The platform’s analysis tools enable users to find underperforming data slices and then add, remove, or modify labeling functions to address them. Users continue iterating until the model satisfies their needs.
In our case, the prompt from step 2 set the foundation of the labeling function suite. In addition, Snorkel Flow automatically generated a collection of labeling functions based on text embeddings. Our engineer addressed the remaining gaps with keyword-based labeling functions.
Results: Optimizing PaLM 2 with domain-specific data results in a 38 F1 boost
Iterating over the data for a few hours resulted in a model that achieved an F1 score of 88—three points above our bar for production deployment. For the sake of the demo, we trained a smaller (TF-IDF) logistic regression model data developed in Snorkel Flow. The platform also provides an option to directly fine tune PaLM 2 with a single click.
Most importantly, these results showcasing the value applied AI teams can realize using Google Cloud and Snorkel extend beyond demonstration. Online retailer Wayfair used Snorkel Flow and Google Cloud to improve the F1 score of their product tagging model by 20 points while reducing overall data development time by roughly 90%.
Better together
Together, Snorkel AI and Google Cloud enable Fortune 500 enterprises to operationalize unstructured data and accelerate AI to keep pace with rapidly evolving needs.
In our case study above, we helped a fictional bank build a model that boosted its ability to serve customers via chatbot. For this example, the specialized model would be deployed to Vertex Endpoints using Vertex AI. This approach could have been used to develop high quality training sets, which could then be used to train a Google Dialogflow agent as outlined in this step-by-step guide authored by Google Premier Consulting Partner Zencore.
AI demands continuous work. After deployment, the fictional bank would discover some shortcoming. The 77 classified intents may miss an important customer need. The model may often misclassify one or more intents in the wild. The bank may introduce a new product or rename one. Over time the way customers talk to the chatbot would drift. All of these would require another round of data development to update the model.
The partnership between Snorkel AI and Google Cloud aims to help enterprises accelerate the development of private generative and predictive AI applications grounded in the factuality of their proprietary data. With Snorkel Flow, Google Cloud customers can develop, fine-tune, and adapt ML models of all sizes—including multi-billion parameter PaLM 2 foundation models —using their own proprietary data and subject matter expertise.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.
Dr. Ali Arsanjani is the director of AI/ML partner engineering at Google Cloud. Paroma Varma co-founded Snorkel AI and now serves as the company’s head of Advanced ML.


Paroma Varma
Co-Founder and Head of Research
Paroma Varma is the co-founder and Head of Research at Snorkel AI, and earned her doctorate in electrical engineering from Stanford University. Her research focused on democratizing machine learning for domain experts who lack access to large datasets necessary for training intricate models, thus making complex AI technologies more accessible and impactful for a broader audience. She applied these methods in diverse fields such as medical imaging and autonomous driving.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

