Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
RAG: LLM performance boost with retrieval-augmented generation
Published: August 15, 2024
Share
Large language models answer questions about everything from baseball to bass guitars. That range originates from pretraining on millions of diverse documents. However, generalist LLMs’ shallow understanding of many topics diminishes their business value for domain-specific tasks. Developers sometimes mitigate this challenge by giving the model additional context through retrieval-augmented generation—better known as RAG.
As the name suggests, retrieval-augmented generation augments the quality of generated responses by retrieving valuable information before submitting the prompt.
Imagine someone asked you to name the president of the United States in 1881. Now imagine someone asked you the same question while you held a history book with a list of presidents and their dates served. That’s how RAG works.
RAG takes place in two phases: the preparation phase and the inference phase. This guide covers the basics of each.
Inference: RAG in action
Without retrieval augmentation, a user writes a prompt and sends it to the large language model (LLM). RAG systems insert an extra step. Before the prompt reaches the LLM, the RAG system searches its available resources for relevant information. While RAG systems could use APIs, web searches, and more, they typically use a prepared, topic-specific knowledge base, which is the architecture we’ll focus on here.
Here’s how it works.
Getting the query embedding
After a user submits a prompt or query, the RAG system gets an embedding for their entry.
What are embeddings? Embeddings are long strings of numbers that allow AI models—including all foundation models and generative AI models—to interpret text. Model pipelines break text into individual words and punctuation, collectively called “tokens.” Neural networks don’t directly understand the tokens. They don’t know what the letter “T” is. Nor do they understand the word “token” nor the lyrics to “The Lion Sleeps Tonight” by The Tokens. They only understand numbers—and they get these numbers from an embedding model.
Data scientists train embedding models on unstructured text through a process called “self-supervised learning.” This process clusters words that often appear together closely in the model’s high-dimensional space. Embeddings for conceptually similar words like “baseball” and “football” lay close together. Embeddings for conceptually divergent words such as “pie” and “aircraft” lay much further apart.
At inference time, the embedding model uses those token-level embeddings to calculate a text-level embedding for the user’s prompt or query.
Retrieving the most relevant documents
After the RAG pipeline generates an embedding for the query, it sends it to a vector database. The vector database compares the submitted embedding to the embeddings for documents stored within the database to find those closest to the query.
Developers can adjust several parameters here. They can set a maximum and minimum number of documents to retrieve. They can also allow the vector database to return a dynamic number of documents according to their distances, or include or exclude potential documents according to tags or metadata.
In a well-tuned system, the database will return a manageable number of document chunks to add to the prompt.
Assembling the final prompt
The RAG pipeline uses templates to assemble the final prompt.
This template will include:
- The original query.
- The relevant document chunks.
- Additional instructions or information (optional).
This template should delineate the original query from the added context. It may also include additional instructions or information to improve the response. For example, a RAG system built to operate on time-based questions must include a current time stamp. Developers may also instruct the model to use only the context given and not rely on any external knowledge.
Once completed, the pipeline sends the enriched prompt to the LLM and returns the response to the user.
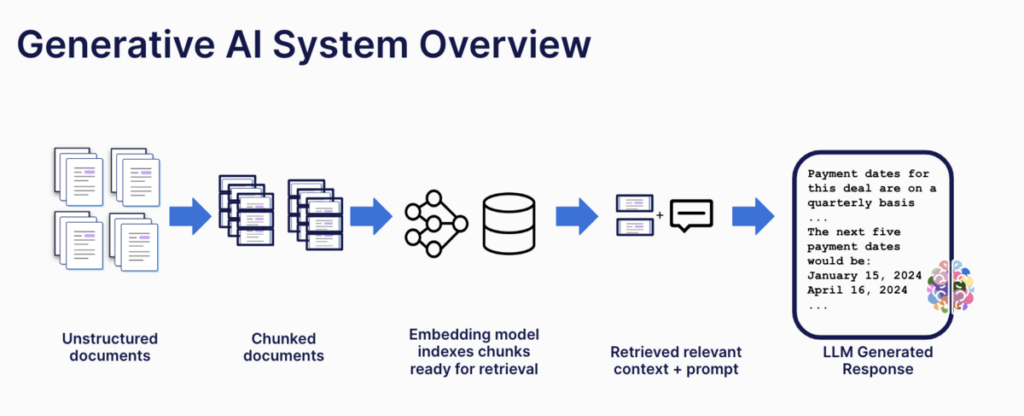
Preparing a RAG system
To retrieve the right context, you must first prepare the right context. RAG systems do this in three steps:
- “Chunking” the documents.
- Getting embeddings for the chunks.
- Storing the chunks with their embeddings.
Let’s explore each.
Document chunking for retrieval-augmented generation
Before anything else, developers building a retrieval-augmented generation system must break documents into chunks.
Why?
Let’s go back to our history book analogy. You wouldn’t want to read an entire textbook just to find the name of the U.S. president in 1881. Instead, you want the “chunk” of the book that lists the presidents by date.
When working with LLMs, developers must work within the model’s “context window.” This is how many words or “tokens” the model can consume and produce for each query. The model can’t yield a result for prompts that exceed their context window.
Newer models boast considerably longer context windows, but the per-token cost of using these models still creates an incentive to minimize how much context you inject.
When chunking documents, developers have three main options:
- Token window chunks. The developer directs the pipeline to break documents into chunks with a fixed number of words. This breaks passages mid-sentence, but developers typically direct the pipeline to repeat the end of each chunk at the start of the next to ensure that each sentence appears unbroken at least once.
- Substring-based chunks. The developer chooses one or more substrings to split text along. Typically, this splits documents into paragraphs or sentences.
- Advanced chunking. Some approaches, like those used in the Snorkel Flow AI data development platform, split documents according to their layouts—keeping together proximate headings, text, and tables.
With the documents chunked, the pipeline can move on to the next step: embeddings.
Embeddings for RAG systems
In this step, the pipeline uses a model to retrieve an embedding for each document chunk. (See “Getting the query embedding” above for more on how embedding models work.)
Vitally, this step must use the same embedding model the pipeline will use during inference.
Attempting to use one model for initial embeddings and another for retrieval will break the system in one of two ways:
- Length mismatch. Embedding models use vectors of a particular length—some as little as 100, others more than 4,000. The retrieval model can only compare vectors of the same length.
- Space mismatch. Embedding models separate concepts in high-dimensional space, but their allocation differs. The coordinates for “sports” in one embedding model could be the space for “baking” in another.
Fortunately, this is a very difficult mistake to make. Most RAG frameworks ask the user to specify their embedding model during setup and automatically use the same for inference.
Document storage in a vector database
Once each document has been chunked and each chunk has an embedding, it’s time to store it in a vector database.
In the retrieval step (discussed above), the vector database fetches likely relevant chunks based on the prompt’s embedding. “Relevance,” in this case, means the smallest distance between the prompt’s embedding and the embedding for each record in the database.
Vector databases avoid making individual distance calculations for every record by clustering chunks and assigning them to their nearest central point. The database first calculates the distance between the query embedding and the central points. Then it calculates the distance for individual records assigned to the central points closest to the query embedding—sharply reducing the total number of calculations necessary.
Vector databases can—and usually do—store additional metadata with the document chunks, but that is a topic for a more advanced deep dive.
Common problems with RAG systems
Douwe Kiela (a co-creator of the RAG concept) would call the application described above a “Frankenstein’s monster” system. It combines off-the-shelf components that work better than prompting alone, but far less well than an optimized system could achieve.
RAG applications typically fall short in two ways:
- They retrieve suboptimal context. Generalist embedding models excel at separating disparate content but struggle to parse content within a domain.
- They use context poorly. An LLM with the right context doesn’t always know how to process it. Advanced applications may require more power or specialization.
Snorkel AI CEO Alex Ratner compares this challenge to a doctor diagnosing a patient. The doctor needs the right context (a medical record) and proper training (an MD and years as a specialist) to make the right diagnosis.
Both of these challenges can be solved. Snorkel researchers and engineers have demonstrated the power of fine-tuning LLMs and fine-tuning embedding models in RAG applications. In one specific case study, Snorkel helped boost the response accuracy of a bank’s RAG system from 25% to 89%.
Optimizing RAG Implementation for Knowledge-Intensive Tasks
Retrieval-augmented generation (RAG) has emerged as a powerful tool to enhance the performance of large language models (LLMs) in knowledge-intensive tasks. By integrating external data and leveraging semantic search, RAG systems can provide more accurate and contextually relevant responses. However, to fully realize the potential of RAG LLM systems, organizations must address key challenges such as training data quality, computational and financial costs, and the integration of structured and unstructured data.
Enhancing RAG with Up-to-Date Information
RAG can incorporate up-to-date information from external knowledge bases. This is particularly valuable for conversational agents and other applications where real-time or recent data is critical. By continuously updating the knowledge base, organizations can ensure that their RAG systems remain relevant and accurate, even in fast-changing domains.
Streamlining the Retrieval Process
The retrieval process is a cornerstone of RAG systems. To optimize this process, developers must focus on improving semantic search capabilities and ensuring that the system can efficiently handle both structured and unstructured data. Advanced techniques, such as fine-tuning embedding models and using domain-specific training data, can significantly enhance the relevance of retrieved documents, leading to better LLM responses.
Balancing Computational and Financial Costs
While RAG systems offer substantial benefits, they also come with computational and financial costs. Organizations must carefully balance these costs by optimizing their RAG implementation. This includes selecting efficient embedding models, minimizing the size of the knowledge base, and leveraging cloud-based solutions to scale resources dynamically. By doing so, businesses can achieve high performance without incurring prohibitive expenses
Integrating RAG with Conversational Agents
Conversational agents stand to gain significantly from RAG LLM systems. By integrating RAG, these agents can access a wealth of external data and provide more informed and contextually appropriate responses. This is particularly useful in customer service, healthcare, and other domains where accurate and timely information is critical. Developers should focus on creating seamless workflows that allow conversational agents to retrieve and utilize information efficiently.
Overcoming Challenges in RAG Implementation
Despite its potential, RAG implementation is not without challenges. Organizations must address issues such as suboptimal context retrieval and poor context utilization. Fine-tuning both LLMs and embedding models can help overcome these challenges, as demonstrated by Snorkel AI’s success in boosting response accuracy from 25% to 89%. Additionally, investing in high-quality training data and domain-specific knowledge bases can further enhance system performance.
Future Directions for RAG Systems
As RAG technology continues to evolve, future developments are likely to focus on improving the integration of structured and unstructured data, enhancing semantic search capabilities, and reducing computational and financial costs. Organizations that stay ahead of these trends will be well-positioned to leverage RAG systems for a wide range of knowledge-intensive tasks, from contract analysis to customer support.
Retrieval-augmented generation: get better answers from LLMs
Retrieval-augmented generation shows great potential to help solve or minimize business challenges. RAG improves the accuracy and usefulness of LLM responses by inserting a step between the user’s query and the prompt reaching the LLM. In this step, the system retrieves and injects vital context to guide the model to a correct response.
While these systems require meaningful setup (and pose challenges) they can generate significant value. One Snorkel AI customer reduced a tedious hours-long procedure down to just a few minutes thanks to a finely-tuned RAG application.
Further reading on retrieval-augmented generation
Here is some further reading on RAG to get you up and running:
- Which is better, retrieval-augmented generation or fine-tuning? Both.
- Retrieval-augmented generation (RAG): a conversation with its creator
- How we achieved 89% accuracy on contract question answering
- Retrieval-augmented generation for knowledge-Intensive NLP tasks
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!