Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Large language models: their history, capabilities and limitations
Published: May 25, 2023
Share
Since the public unveiling of ChatGPT, large language models (or LLMs) have had a cultural moment. The potential of these enormous neural networks has both excited and frightened the public; the same technology that promises to help you digest long email chains also threatens to dethrone the essay as the default classroom assignment.
But what are large language models? Where did they come from? How do they work? And how can you make them work better?
Let’s go answer some of these questions.
What are large language models (LLMs)?
Large language models are foundation models (a kind of large neural network) that generate or embed text. The text they generate can be conditioned by giving them a starting point or “prompt,” enabling them to solve useful tasks expressed in natural language or code.
Data scientists and researchers train LLMs on enormous amounts of unstructured data through self-supervised learning. During the training process, the model accepts sequences of words with one or more words missing. The model then predicts the missing words (see “what is self-supervised learning?” in the linked article) in a process that results not only in a set of valuable weights for the model, but also an embedding for each word fed to it.
At inference time, users provide “prompts” to the LLM—snippets of text that the model uses as a jumping-off point. First, the model converts each token in the prompt into its embedding. Then, it uses those embeddings to predict the relative likelihoods of all possible tokens that could follow. It then selects the next token on a semi-random basis and repeats this process until the model selects a STOP token.
You can imagine this as a number line that stretches from zero to one. Starting from the left, the large language model will stack up the probabilities of the tokens from largest to smallest. The first chunk of the line, from 0 to 0.01, might be “hello.” The second chunk, from 0.01 to 0.019 might be “world,” and so on. Then, the model picks a random point on that number line and returns the token associated with it.
In practice, large language models usually restrict themselves only to tokens with relatively high likelihoods. This is why when fed the prompt “I went to see the New York,” the first token GPT-3 generates will almost always be a sports team or performance venue associated with the city.
A brief history of large language models
Large language models grew out of research and experiments with neural networks to allow computers to process natural language. The roots of natural language processing stretch back to the 1950s, when researchers at IBM and Georgetown University developed a system to automatically translate a collection of phrases from Russian to English. In the decades since, researchers experimented with a number of different approaches—including conceptual ontologies and rule-based systems—but none of them yielded robust results.
In the 2010s, this research intersected with the then-bustling field of neural networks, setting the ground for the first large language model.
BERT, the first breakout large language model
In 2019, a team of researchers at Google introduced BERT (which stands for bidirectional encoder representations from transformers).
Their new model combined several ideas into something surprisingly simple and powerful. By making BERT bidirectional, it allowed the inputs and outputs to take each others’ context into account. By using a neural network architecture with a consistent width throughout, the researchers allowed the model to adapt to a variety of tasks. And, by pre-training BERT in a self-supervised manner on a wide variety of unstructured data, the researchers created a model rich with the understanding of relationships between words.
All of this made it easy for researchers and practitioners to use Google’s BERT. As the original researchers explained, “the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks.”
At its debut, BERT shattered the records for a suite of NLP benchmark tests. Within a short time, BERT became the standard tool for NLP tasks. Less than 18 months after its debut, BERT powered nearly every English-language query processed by Google Search.
Bigger than BERT
At the time of its debut, BERT’s 340 million parameters tied it as the largest language model of its kind. (The tie was a deliberate choice; the researchers wanted it to have the same number of parameters as GPT to simplify performance comparisons.) That size is quaint according to modern comparisons.
From 2018 to the modern day, NLP researchers have engaged in a steady march toward ever-larger models. Hugging Face’s Julien Simon called this steady increase a “new Moore’s Law.”
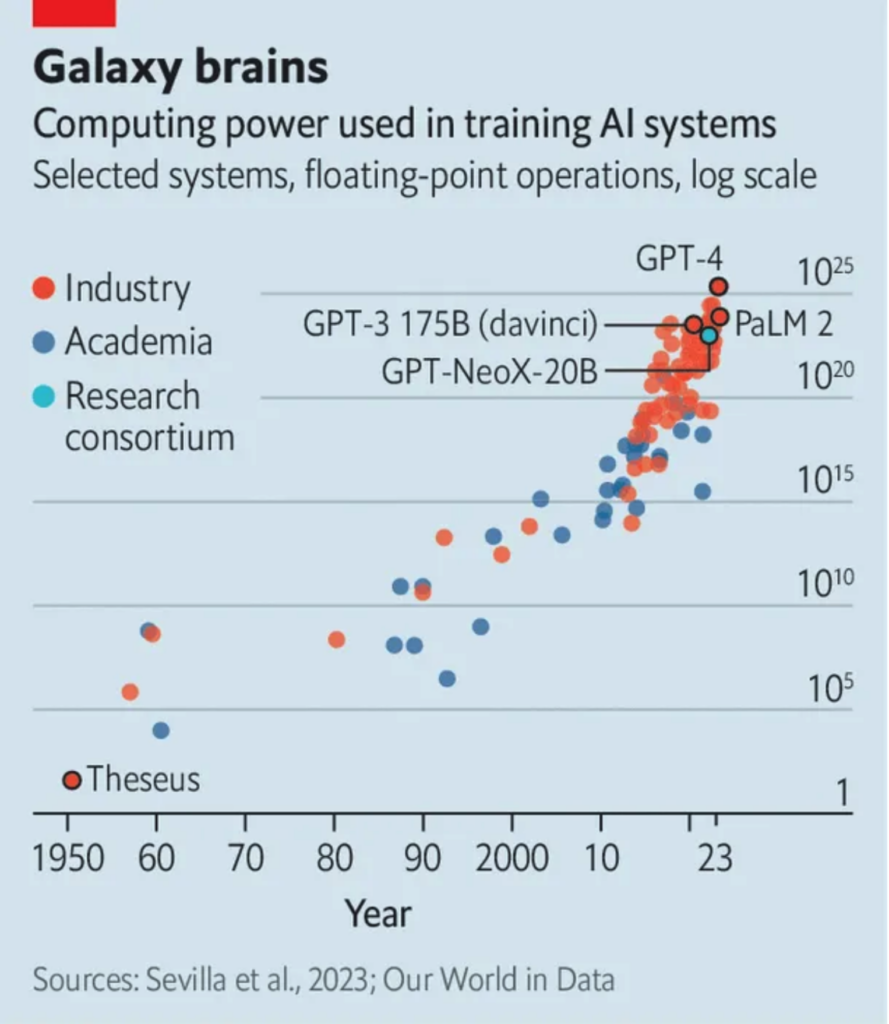
As large language models grew, they improved. OpenAI’s GPT-2, finalized in 2019 at 1.5 billion parameters, raised eyebrows by producing convincing prose. GPT-2’s impressive performance gave OpenAI pause; the company initially withheld the full-sized version of the model, due to “concerns about large language models being used to generate deceptive, biased, or abusive language at scale.” Instead, they released a smaller, less-compelling version of the model at first, and followed up with several increasingly-large variations.
Next, OpenAI released GPT-3 in June of 2020. At 175 billion parameters, GPT-3 set the new size standard for large language models. It quickly became the focal point for large language model research (you’ll see it referenced many times in this document), and served as the original underpinning of ChatGPT.
Most recently, OpenAI debuted GPT-4. At the time of this writing, OpenAI has not publicly stated GPT-4’s parameter count, but one estimate based on conversations with OpenAI employees put it at one trillion parameters—five times the size of GPT-3 and nearly 3,000 times the size of the original large version of BERT. The gargantuan model represented a meaningful improvement over its predecessors, allowing users to process up to 50 pages of text—an achievement later built upon by “long context models” like Gemini 1.5, which could handle a million or more tokens per request.
The ChatGPT moment
While researchers and practitioners devised and deployed variations of BERT, GPT-2, GPT-3, and T5, the public took little notice. Evidence of the models’ impacts surfaced on websites in the form of summarized reviews and better search results. The most direct examples of the existing LLMs, as far as the general public was concerned, was a scattering of news stories written in whole or in part by GPT variations.
Then OpenAI released ChatGPT in Novermber 2022. The interactive chat simulator allowed non-technical users to prompt the LLM and quickly receive a response. As the user sent additional prompts, the system would take previous prompts and responses into account, giving the interaction conversation-like continuity.
The new tool caused a stir. The scattering of LLM-aided news reports became a tidal wave, as local reporters across the U.S. produced stories about ChatGPT, most of which revealed the reporter had used ChatGPT to write a portion of the story.
Following the frenzy, Microsoft, who had partnered with OpenAI in 2019, built a version of its Bing search engine powered by ChatGPT. Meanwhile, business leaders took a sudden interest in how this technology could improve profits.
Chasing ChatGPT
Researchers and tech companies responded to the ChatGPT moment by showing their own capabilities with large language models.
In February 2023, Cohere introduced the beta version of its summarization product. The new endpoint, built on a large language model customized specifically for summarization, allowed users to enter up to 18-20 pages of text to summarize, which was considerably more than users could summarize through ChatGPT or directly through GPT-3.
A week later, Google introduced Bard, its own LLM-backed chatbot. The event announcing Bard pre-empted Microsoft and OpenAI’s first public demonstration of a new, ChatGPT-powered Bing search engine, news of which had reached publications in January.
Meta rounded out the month when it introduced LLaMA (Large Language Model Meta AI). LLaMA wasn’t a direct duplication of GPT-3 (Meta AI had introduced their direct GPT-3 clone, OPT-175B, in May of 2020). Instead, the LLaMA project aimed to enable the research community with powerful large language models of a manageable size. LLaMA came in four size varieties, the largest of which had 65 billion parameters—which was still barely more than a third of the size of GPT-3.
In April, DataBricks released Dolly 2.0. Databricks CEO Ali Ghodsi told Bloomberg that the open-sourced LLM replicated a lot of the functionality of “these existing other models,” a not-so-subtle wink to GPT-3. In the same interview, Ghodsi noted that his company chose the name “Dolly” in honor of the cloned sheep, and because it sounded a bit like Dall-E, another prominent model from OpenAI.
The age of giant LLMs is already over?
Shortly after OpenAI released GPT-4, OpenAI CEO Sam Altman told a crowd at the Massachusetts Institute of Technology that he thought the era of “giant, giant” models was over. The strategy of throwing ever more text at ever more neurons had reached a point of diminishing returns. Among other challenges, he said, OpenAI was bumping up against the physical limits of how many data centers the company owned or could build.
“We’ll make them better in other ways,” he told the crowd.
Altman isn’t alone. In the same piece, Wired cited agreement from Nick Frosst, a cofounder at Cohere.
We at Snorkel have long believed that ever-larger language models are not a panacea. Our researchers have pioneered work that has shown that smaller, larger language models can be made more effective than their behemoth siblings through specialization.
Since Altman’s statement at MIT, research and development on LLMs has morphed. Firms working on the largest “frontier” models tend to train them on visual or audio media in addition to text. They also tend to no longer publicly disclose the models’ parameter counts and spend more time and effort preparing training data than they did in the past.
Meanwhile, they have also debuted a growing number of models that achieve results similar to the largest models on a smaller footprint. Meta’s Llama 3.1 405B, for example, achieved benchmark results similar to GPT-4 with less than 25% as many parameters.
Key terms
As a new field, large language models have spawned their own collection of specialized terms. This section will define several of the most important.
Attention
Attention is a mathematical mechanism for deciding how strongly to consider the impact of each token fed through a neural network—in this case, a large language model. Researchers devised this approach to solve the problem of vanishing or exploding gradients when fed long sequences of tokens. In practice, early natural language processing models began to “forget” tokens more than 20 steps away from the target token, which limited their effectiveness.
Researchers have formulated several ways to calculate attention, but it is most often handled through a small module that is itself a neural network.
Embeddings
Embeddings refer to numerical representations of words that capture the words’ semantic meanings and contextual relationships. These high-dimensional vector representations (12,288 dimensions, in the case of GPT-3) allow words to gravitate closer to words with similar meanings and for meanings to be flexible in different contexts.
The word “bank,” for example, can refer to a place where someone keeps a resource, the way an aircraft turns, or the place where a river meets the land. The high-dimensional representation allows for the embedding to capture all of those meanings, and for the model to recognize which meaning it should use in the current context.
Embeddings are also used to represent larger textual units, such as sentences, paragraphs, or entire documents. These embeddings aim to capture the overall meaning or context of a sentence or document.
Transformers
Transformers are a kind of neural network architecture that form the core of most large language models. Unlike recurrent neural networks (RNNs), which process the input data one element at a time, transformers can process the entire input at once.
Transformers can consist of two main components: an encoder and a decoder. The encoder converts an input sequence into a vector representation called an encoding. The decoder takes the encoding and generates an output sequence. Language models can be a decoder (e.g., GPT), an encoder (e.g., BERT), or consist of both (e.g., T5).
Both the encoder and the decoder components are composed of multiple attention layers. Each attention layer uses a function to compute “self-attention” scores for each element in the input or output sequence. This “self-attention” score measures how similar each element is to each other element.
The attention layer then uses these scores to create a “context vector,” a weighted average of the input or output elements. The attention layer then passes the context vector through a feed-forward network, which applies a non-linear transformation to produce the layer’s final output.
Prompt
A prompt refers to the input or instruction a user provides to a large language model to generate a response or perform a specific task. It serves as a starting point or a cue for the model to understand what the user expects and guide its subsequent language generation. A prompt can take many forms depending on the application or task. It can be a complete sentence, a question, a partial phrase, or even a few keywords.
Instruction tuning
Recently, many large language models are further trained to follow instructions in the form of prompts. This step comes after the initial self-supervised training in which the model predicts missing words. The idea is to train the language model to answer a wide variety of prompts in order to learn how to answer new, unseen ones at test time. This technique was proposed concurrently by two teams, one from Google and one from the BigScience research project, including researchers from Snorkel.
RLHF (reinforcement learning with human feedback)
Reinforcement learning with human feedback (better known as “RLHF”) is a technique that instruction-tunes a model based on human preferences. For example, a researcher seeking to improve a large language model through RLHF would ask the model to generate multiple responses to a given prompt and then ask one or more humans to rank the responses from best to worst. This creates a reward function for the model to optimize against, and reward functions can be difficult to define for generative tasks.
DPO (direct preference optimization)
Direct preference optimization (DPO) is another alignment technique (see above). Instead ofa complex reward system, DPO trains the model by deeming responses as “good” or “bad,” making it faster and easier to fine-tune the model.
Mixture of experts
Several models that developers and researchers have released since the debut of GPT-4 have used a “mixture of experts” approach.
Mixture of experts (MoE) describes any machine learning model that uses inputs from multiple models to make its prediction. In classical machine learning, this might combine a random forest model with a logistic regression model and a support vector machine.
In the age of LLMs, this typically means a collection of smaller neural networks, each of which has “specialized” on a particular corner of its pretraining and fine-tuning data. While it’s tempting to think of this in terms of topics (math, science, history, etc.) these specializations rarely map cleanly to human-recognizable categories.
Most MoE LLMs also use only a minority of their “expert”models to consult on any given calculation—and that minority could shift several times while responding to each prompt.
Long context model
Researchers have developed a growing number of models that can intake a previously impossible amount of text. In some cases, these context windows stretch into the millions of tokens—enough to contain The Hobbit and the entire Lord of the Rings trilogy with room for more. Experts in the field have come to call these “long context models.”
Small language models
What qualifies as “large” has changed over time. BERT debuted with 340 million parameters. Frontier models in 2024 boasted parameter counts four orders of magnitude larger. Due to this, experts in the field started referring to some LLMs as small language models. Individual experts disagree on where to draw the line, but most agree that 7 billion parameter models like Llama 3 7B fall squarely in the “small” category.
What can large language models do?
The most popular large language models are known for their ability to generate text, but the capabilities of LLMs aren’t limited to writing essays in the voice of your favorite celebrities. Whether through clever prompting or building an additional neural layer on top of the pre-trained base model, LLMs can perform a number of useful tasks for machine learning practitioners.
Sentiment analysis
You can use large language models to perform sentiment analysis by fine-tuning them on a text dataset with sentiment labels. For example, you can fine-tune a large language model on a dataset of movie reviews with associated ratings. Then, you can use the fine-tuned model to predict the rating of a new movie review.
You can also use large language models to perform sentiment analysis by in-context learning. This means that you provide some examples of the task before asking the model to generate an answer. For example:
I love this movie. It was so funny and entertaining: Positive
This movie was terrible. The plot was boring and the acting was awful: Negative
This movie was okay. It had some good moments but also some flaws: Neutral
The movie was great. I enjoyed it a lot: Text categorization
Large language models can help machine learning practitioners categorize text in two main ways—through fine-tuning on a labeled dataset, or through clever prompt programming. If you’re trying to categorize a short piece of text, an approach similar to the in-context learning example shown in the sentiment analysis section above could work. For longer pieces of text, you can feed the LLM the text to categorize, followed by a question such as “Which of the following categories does the above text most closely resemble: business|sports|news.”
Text editing
Large language models can edit text or suggest improvements or corrections to an existing piece of writing. For example, you can use a large language model to check your spelling and grammar or to rewrite sentences to make them clearer or more concise. This can be done in several ways—the easiest of which is to use Grammarly or one of several other consumer-focused, LLM-backed services aimed at this task. Some LLM APIs also have “edit” modes, or you could build your own system by fine-tuning a pre-trained model on a specific domain or task, such as academic writing or technical documentation.
Language translation
Language translation was one of the original uses of large language models, and the most recent generation of LLMs has only made translation easier. Many publicly available LLMs will render passable translations with a simple prompt—though some clever prompting techniques can improve the translation quality.
Information extraction
There are two main ways to use large language models for information extraction: fine-tuning and querying.
In the fine-tuning approach, you would use a dataset with labeled examples of the kind of information you want to extract, for example, a dataset that has person names annotated with a [PER] tag. Then you could use the fine-tuned model to predict the tags for new texts.
The querying approach allows you to extract information without fine-tuning. Simply formulate your extraction task as a natural language prompt, such as “Who is the following quote attributed to?” Well-crafted prompts will lead to better outcomes, but even a simple command will work much of the time.
Fine-tuning is more accurate and consistent but requires more data and computational resources. Querying is more flexible and generalizable but may produce incorrect or incomplete answers. Depending on your task and available resources, you may choose either method or a combination of both.
Summarization
Summarization was an early use case for natural language processing, and researchers built several models specifically for that purpose. However, modern large language models make it even easier.
Like other capabilities listed here, one approach to using LLMs for summarization is to fine-tune one on a summarization dataset—pairs of longer texts summarized in shorter passages. However, the interfaces for most popular large language models will let you get summaries “off the shelf” with a simple prompt. You could feed a product review to an LLM and ask it for the main pros and cons of the product, feed it a large block of text and ask it to list the top five most important bullet points from that text, or simply say “summarize this.”
Depending on your needs, you may need to massage your prompt, but a small amount of tinkering should produce a usable result.
How to heighten performance from generalized large language models
Generalized large language models are a lot of fun to play with, but their erratic behavior can become a serious problem when you’re trying to build an LLM-backed application with predictable outcomes. Researchers have found several prompt-based tricks to narrow and sharpen large language model responses. This is generally known as “prompt programming” or “prompt engineering.”
According to the paper “Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm,” successful prompt programming generally aims to reinforce the desired behavior, often through redundancy. Some of this can be subtle and finicky; in one example proposed in this paper, the author found more reliable performance by changing the beginning of a prompt from “Translate French to English:” to “Translate this French sentence
to English.” The former, he said, increased the likelihood that the LLM would continue in French instead of translating the passage.
But some of the methods devised by researchers are less subtle and more discrete, including those listed below.
As the state-of-the-art on LLMs has advanced, some of these methods have become unnecessary, but they may still be useful for older models or smaller self-hosted models.
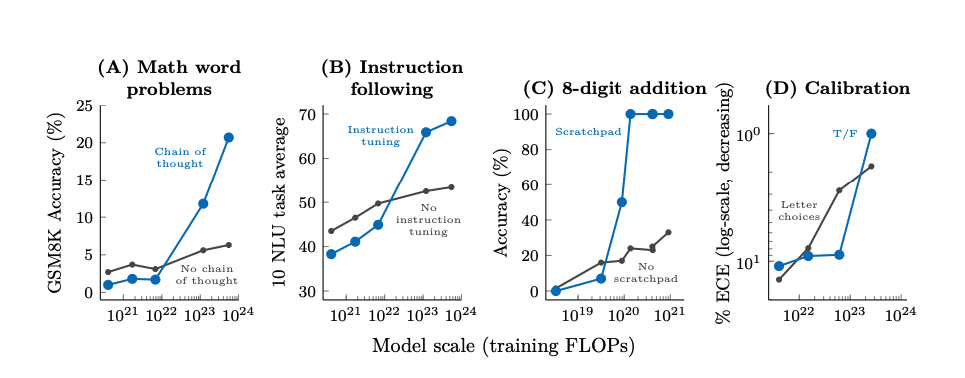
effect until a certain model scale. Charts from the paper “Emergent Abilities of Large Language Models” by Jason Wei, et. al.
Multi-step reasoning
Reasoning tasks, especially those with multiple steps, have challenged language models. However, chain-of-thought prompting can help. This approach guides large language models to generate a series of intermediate steps before providing the final answer. Chain-of-thought prompting generally improves performance over standard prompting. Additionally, adding explanations after the final answer in few-shot prompting has also shown performance improvements.

Instruction following
“Instruction following” is a way of coaxing large language models to perform more predictably by using prompts that specify the user’s intention and the desired output format. For example, to make a language model write a summary of a text, one could use a prompt like this:
Translation:
Translate the following sentence from English to Spanish.
Sentence:
I like to read books and play games.
Output:
Me gusta leer libros y jugar juegos.The instruction following prompt strategy can improve the performance of language models by making them more aligned with the user’s goals, more truthful, and less toxic. It can also reduce the need for fine-tuning or task-specific data. While it requires human expertise and creativity to design effective prompts for different tasks and domains, this framework is easily automated with string substitution techniques.
Model calibration
In this prompting strategy, the user asks a large language model to produce the answer to a question but also to evaluate the model’s own confidence in this answer. This can be achieved in two ways: the first is to simply ask the model for the probability of its answer being true. The second is to ask the model the probability that it knows the answer to a specified question, and only ask the specified question if the probability is high.
Memetic proxy
The memetic proxy approach helps narrow the large language model’s execution by putting it in the semantic space of a particular character. To use memetic proxy, you prompt the model to answer as a particular persona. This could be a well-known public figure, such as a celebrity or politician, or a well-known archetype, like a teacher. For example: “Explain foundation models to me like a teacher would explain them to a third grader.”
Other examples can get more elaborate, such as telling the model that the user entered their question into an “expert generator” and asking the model to simulate the output of the expert generator.
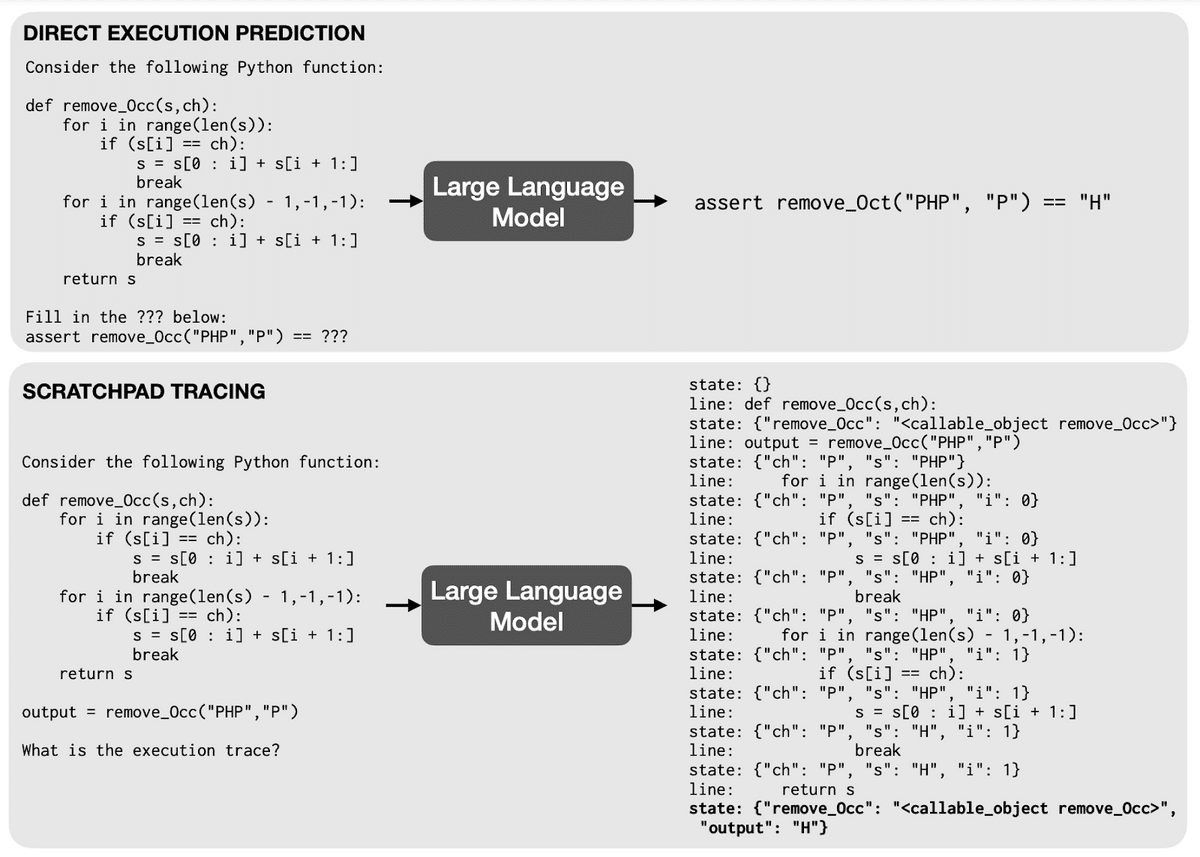
Program execution
The “program execution” strategy improves performance for large language model tasks that involve executing programs by forcing the model to use a “scratch pad.” For example, instead of asking the LLM for the output of a Python function given a particular input, the user can ask the LLM to show the execution trace. This induces the model to generate predictions for each intermediate step the function would perform and increase the likelihood that the final line generated by the LLM is correct.
Developer resources for large language models
Now that large language models are widely available, developers want to use them. This section will cover some of the tools and resources available to allow data science practitioners to make use of large language models.
OpenAI libraries
OpenAI offers libraries to interact with its foundation models—including its GPT class of large language models—for Python and Node.js. The community around OpenAI has published open-source versions of these libraries for many more languages, including Java and Go.
Google Vertex AI client libraries
Google’s Vertex AI cloud platform offers a unified place for developers to build, train, and deploy AI applications.
The company offers libraries for interacting with Vertex AI in the following programming languages:
- C#
- Go
- Java
- Node.js
- Python
Llama
Meta AI open-sourced its Llama family of large language models. While not offering a direct API like OpenAI, Google, or others, developers can access Llama models by downloading the model weights and running a version locally. Developers can also access Llama and Llama variants through Hugging Face and several cloud providers.
HELM (Holistic Evaluation of Language Models)
This Stanford group compiled an extensive collection of LLM benchmarks and applied them to many LLMs. Visitors can use HELM leaderboards to help identify the best model to form the foundation for an upcoming project.
Hugging Face
Hugging Face provides an open-source platform for natural language processing and foundation models. The platform hosts hundreds of LLMs, many of which are specialized for specific topics or tasks, such as scientific data, text classification or question answering. Developers can use Hugging Face to access pre-trained models directly or fine-tune them on their own data. In addition to hosting its robust platform, Hugging Face has a Python library to make it easier to integrate these models into projects.
LlamaIndex
LlamaIndex offers open-source retrieval-augmented generation framework designed to connect large language models with your own data. It enables users to create custom knowledge bases and applications by indexing and querying various data sources.
LangChain
The LangChain Python package provides functionality for developing applications powered by large language models. The package can combine different LLMs and sources of computation or knowledge to create powerful applications. For example, you can use LangChain to create chatbots, question-answering systems, or a pipeline to generate distilled, usable content from a loose collection of documents.
AutoGPT
The AutoGPT Python package uses ChatGPT to create autonomous agents that can generate and execute their own tasks. AutoGPT accepts a single prompt from the user, then generates a task list and executes those tasks. It completes tasks by chaining together calls to ChatGPT and interacting with other sources of computation or knowledge, such as the internet, files, or databases.
How to adapt large language models to specific tasks
Large language models can form the foundation of your project, but they’re unlikely to get you all the way there. Off-the-shelf LLMs are trained on enormous amounts of data across many domains, and therefore tend to perform poorly on domain-specific tasks. But there are several ways to coax what you need from them.
Self-supervised fine-tuning
In this approach, the machine learning practitioner feeds a pre-trained large language model a large amount of unlabeled, domain-specific data to fine-tune its weights. For example, if you wanted a version of LLaMA that answered legal questions with high accuracy, you could fine-tune the base model on a corpus of court filings.
Among other improvements, this would sharply reduce the frequency with which the LLM confuses words with multiple meanings. For example, LLaMA fine-tuned on court filings would be unlikely to interpret the word “suit” as formal wear.
While self-supervised fine-tuning can improve performance, it may also propagate errors or biases from the pre-trained model. It could also undo some of the benefits of instruction tuning done on the base model.
Supervised fine-tuning
In this approach, the machine learning practitioner retrains a pre-trained language model on a smaller, task-specific labeled dataset.
To do this, the practitioner prepares a labeled dataset that contains examples of the desired inputs and outputs. For example, if we want to use a language model for sentiment analysis, we can prepare a dataset that contains sentences and their corresponding sentiment labels (positive, negative, or neutral). If we want to use a language model for summarization, we can prepare a dataset that contains documents and their corresponding summaries.
From there, the practitioner defines a loss function and retrains the model by feeding it batches of the training inputs and outputs. This will update the model’s weights, and move its outputs closer to those of your training data.
Distillation
Distillation is the process of transferring knowledge from a large model to a smaller one. While large models, such as large language models, have high knowledge capacity, this capacity might not be fully utilized or fully relevant to our task. We can compress relevant knowledge from that model into a smaller one that’s more efficient and faster, while retaining most of its performance.
To do this, we first select a large model that we’d like to distill. This model will act as a teacher for the smaller model. Second, we select a smaller model to act as the student. Third, we train the smaller model using the outputs of the large model as “soft” targets. This means that instead of using the hard labels (such as the correct class or token) as the ground truth, we use the probability distribution over all possible labels or tokens that the large model produces. This way, the smaller model can learn not only from the most likely output but also from the uncertainty and confidence of the large model.
Frequently asked questions about large language models
This section will answer some common questions about generative AI.
Is GPT a large language model?
The GPT family of models are large language models. ChatGPT is not a large language model; it is a program with many components, the core of which is a large language model.
What are large language model capabilities?
Large language models have a wide variety of capabilities. Some that we covered in this piece include sentiment analysis, text editing, text categorization, translation, summarization, and information extraction.
Why is GPT better than BERT?
“Better” is relative. The most recent GPT models are larger, more robust, and boast language generation abilities. However, BERT models—despite their lack of text-generation abilities—are better suited for many tasks. They occupy a smaller footprint, cost less, and will perform some vital NLP tasks at higher accuracy than GPT models when properly fine-tuned and adapted.
Is BERT a large language model?
BERT is a large language mode, but it is not built for text generation in the same way that some other large language models are. Developers can build systems to use BERT to generate text, but it is less effective than other options.
What are the drawbacks of GPT?
The GPT series of models have a number of drawbacks. While GPT-2 and later versions of the model have displayed impressive language generation abilities, their increasing size makes them expensive to run. The models also have a tendency to “hallucinate” answers, which is a drawback baked directly into their architecture. When prompted, GPT models generate the next most likely series of tokens according to their internal weights. If the models enter an area where they lack knowledge, they will answer just as confidently as when the model has been trained on directly-relevant data.
This problem is not limited to the GPT series of models. It is a common problem of large language models generally.
What is the GPT-3 competitor from Google?
LaMDA (Language Model for Dialogue Applications) is Google’s rival for the GPT-3 large language model. Google also produces Bard, which is its LaMDA-backed chatbot that competes with ChatGPT.
What are the popular large language models?
The two most “popular” large language models are probably GPT-3/3.5/4 and BERT—for very different reasons and applications. The general public and some creative developers have made use of the GPT series of models through ChatGPT, the Bing search engine, and OpenAI’s playground and developer libraries for text generation applications. However, many companies and businesses still use BERT for many applications that don’t get quite as much attention.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!