
Large language models have demonstrated remarkable utility in document summarization and research facilitation. However, they are not flawless; such models sometimes generate false information, a phenomenon known as “hallucination,” which poses significant risks in business environments. To address this issue, I developed a proof of concept for clients, integrating generative AI (GenAI) with predictive AI.
The resulting application leverages Snorkel Flow’s programmatic labeling to develop quicker and more effective models. Showcased via a Streamlit front-end, it exemplifies the synergy of predictive and GenAI in achieving thorough and accurate document comprehension—thus offering an enriched user experience.
The challenge: extracting information from complex documents
Snorkel has collaborated with various banks on projects aimed at extracting information from complex, difficult-to-interpret financial documents. Recently, a rising interest in a conversational generative AI interface for managing unstructured data, including formats such as HTML and PDF, has been observed among both potential and existing Snorkel customers. This interest aligned with my own during my attendance at the DataHack Summit 2023 in Bangalore, India.
At this event, numerous delegates shared a familiar concern: hesitancy in using large language models (LLMs) due to issues with accuracy and trust. Their main goal was to develop a chat-based solution that would pioneer the integration of GenAI capabilities, thereby enhancing the customer experience for their clients.
I devised a hybrid pipeline that capitalizes on the strengths of both predictive models and LLMs.
Drawing on my hackathon experiences, I returned to work to create a proof-of-concept document intelligence platform for a leading U.S. bank prospect. This platform concentrated on extracting two critical types of information from the comprehensive annual reports mandated by the SEC, known as 10-K documents.
Delving into the 10-K: unpacking its challenges and importance
A 10-K document is a comprehensive report filed annually by publicly traded companies to the U.S. Securities and Exchange Commission (SEC). It provides a detailed overview of a company’s financial performance and includes information not typically found in the annual report to shareholders.

Nature of 10-K documents: Annual reports filed by publicly traded companies with the SEC, containing dense, technical information.
Content complexity: Includes detailed financial statements, extensive footnotes, and in-depth management discussions.
Challenges in information extraction:
- Complex accounting terminology makes comprehension difficult.
- Lengthy legal disclaimers add to the complexity.
- Large volume of data makes sifting through information a daunting task.
Language ambiguity: Reports often use vague or euphemistic language.
Requirement for expertise: Accurate interpretation demands a strong background in finance and business.
The predictive portion
Using the Snorkel Flow AI data development platform, I built an information-extraction pipeline. This pipeline extracts information about two specific things:
- Legal risks
- Interest rate swaps
For interest rate swaps, the pipeline extracts the company name, the interest rate swap amount, and the swap type (floating to fixed, fixed to floating, or not identified). It also extracts the passage in which it identified this information for the sake of later verification.
The legal risks portion checks each paragraph and predicts whether that paragraph refers to legal risks. If it does, it extracts that paragraph and stores it for examination—along with a prediction for what kind of risk the paragraph represents.
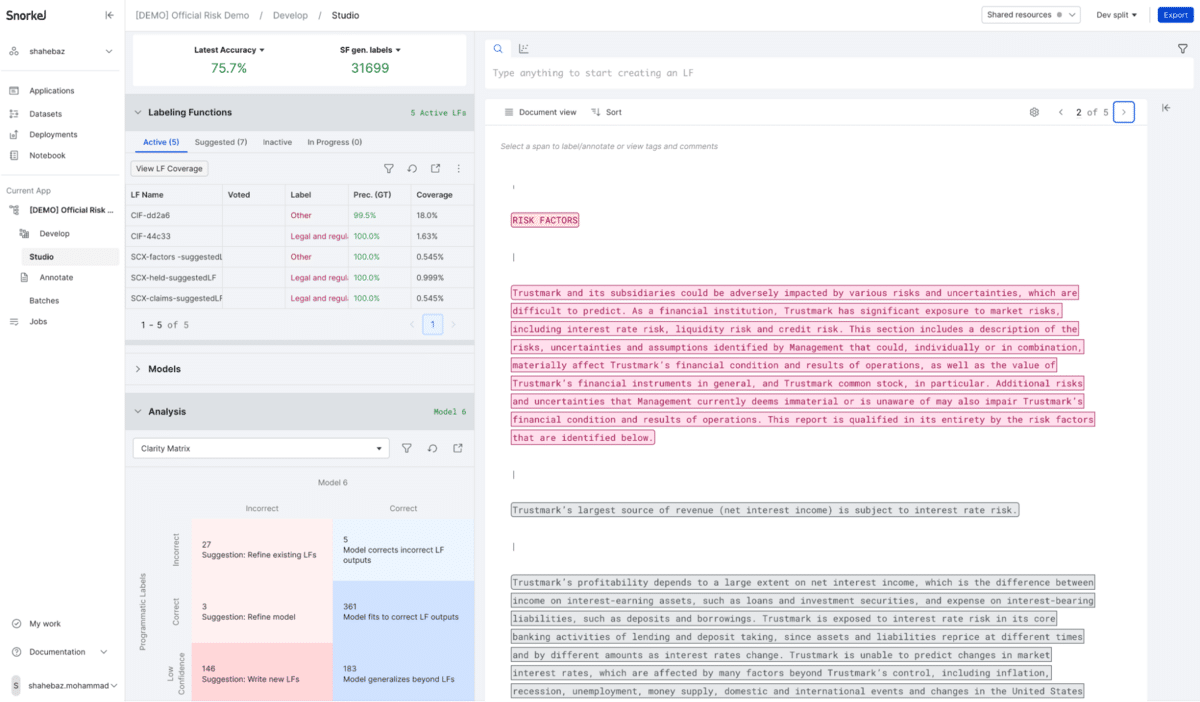
We could expand this portion of the application. It could extract any kind of information typically found in 10-Ks, such as the names of senior management or cash flow statements, but I limited my scope for this proof of concept.
In my demonstration, I store the extracted data in a Pandas dataframe. If we were to productionize this application, we would move these predictions into an appropriate SQL database for long-term use and storage.
On an important note, the pipeline also stores the confidence for each prediction for later reference; knowing whether the model had 70% confidence in a prediction of 95% confidence could have a meaningful impact on decision-making. One of the unquestionable advantages of adopting the aforementioned approach lies in its ability to ensure model transparency, auditability, and successful passage through MRM (Model Risk Management) review.
The chat experience via Generative AI
This portion of the application resembles other “chat with your PDF” tools, with one key difference: the chat interface does not consult the document; it consults our stored predictions.

10K Co-Pilot for Trustworthy Predictive Chatting
This approach has several advantages:
- It allows users to ask useful, natural-language questions as if they were using ChatGPT.
- It reduces inference costs by sharply reducing the number of tokens our app sends to the LLM API.
- It reduces the potential for hallucinations by keeping the investigated context narrowly focused.
In my experiments, it appeared that this approach reduced hallucinations more so than mainstream vector database-driven retrieval augmentation pipelines. While RAG pipelines demonstrate incredible power, they can inject irrelevant information into the prompt that the LLM then incorrectly interprets, resulting in a hallucination.
Because of the deterministic nature of our injected context, the only way that we can inject irrelevant information is if our initial prediction was wrong—the risk of which would be immediately obvious from the displayed confidence score.
The query experience
In addition to enabling users to chat with predictions, I wanted to give users the ability to analyze documents, inspect predictions, and filter them to do more drill-down analysis and then query the extracted data in natural language. This portion of the app enables users to ask a question, such as “Group by company sum of interest rate swap.” The app prompts the LLM to build a query to isolate that data, then runs that query and returns the results. Note that the LLM is only given metadata regarding the underlying data structure and data never leaves your premises.
While this portion of the app could theoretically return a malformed query, it can’t generate a hallucination; the returned data will be extracted directly from the original documents.
This portion of the application also includes enhanced ways to browse the documents, including an annotated PDF view that highlights portions of the document extracted by the models.
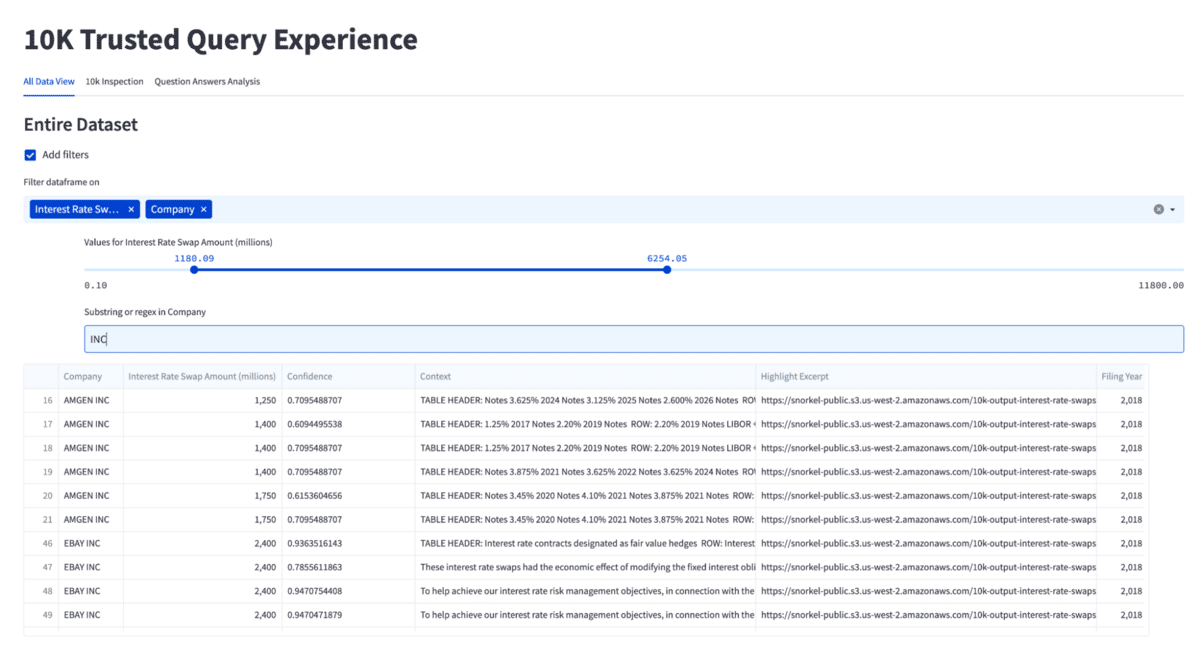
Prediction data analysis View
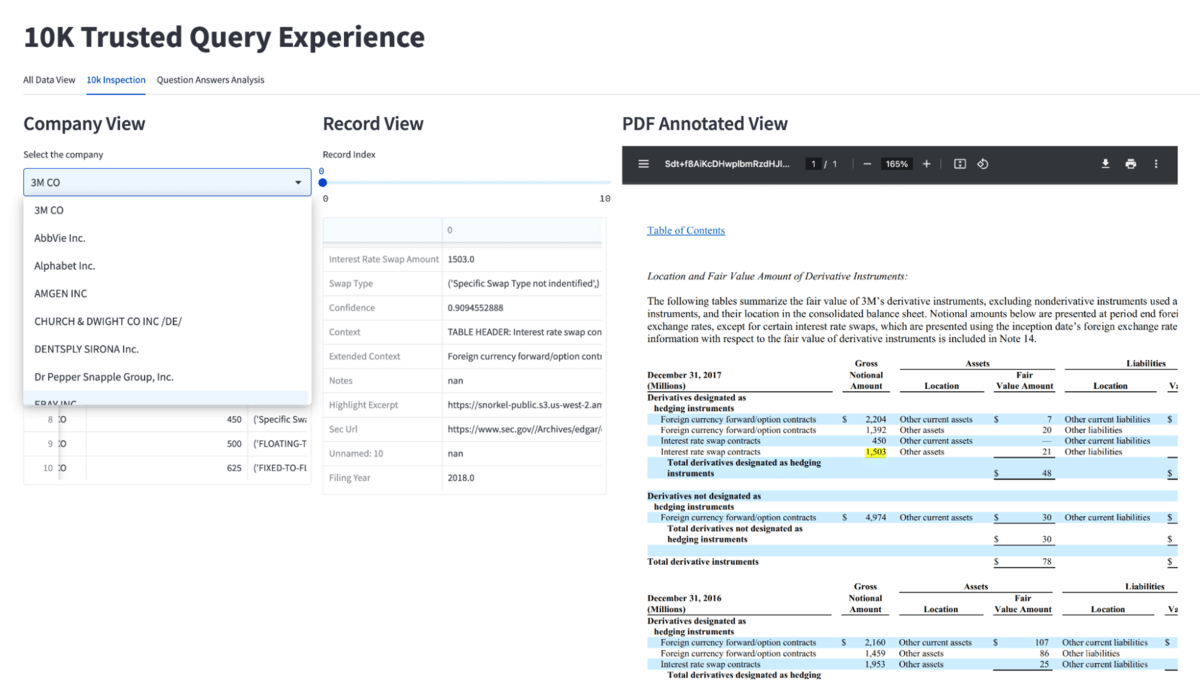
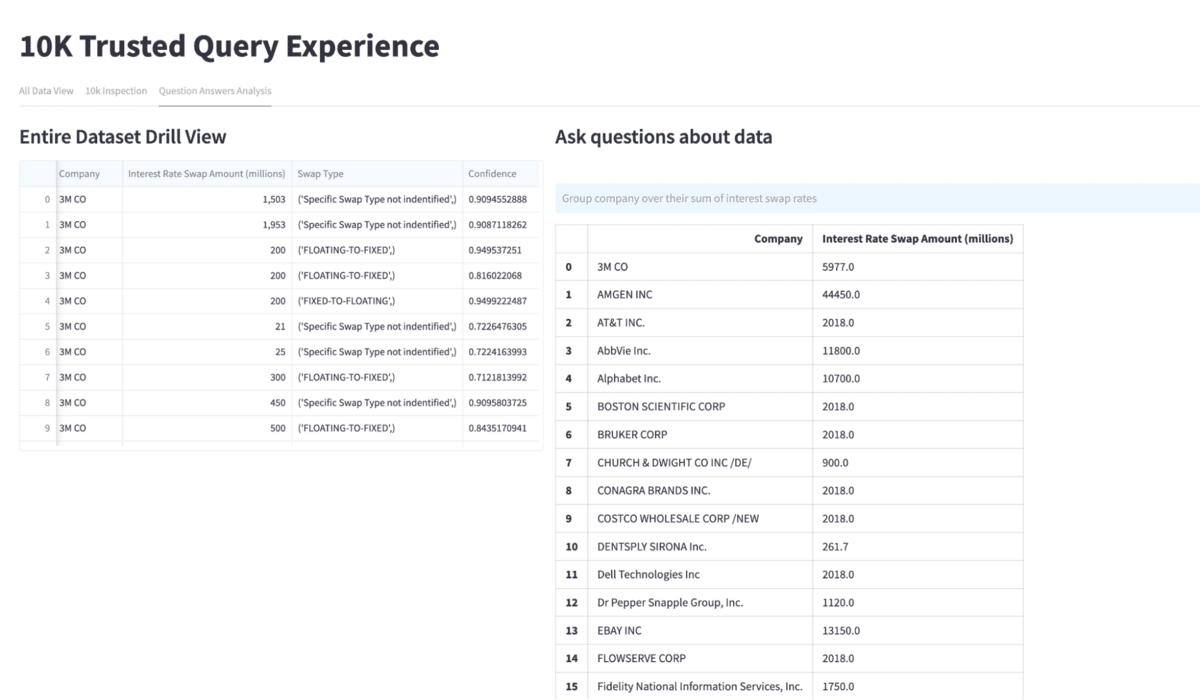
Predictive AI + generative AI: a powerful pair
I set out to build a utility that would allow financial analysts to get the benefits of an LLM chat experience while minimizing the risks that LLMs present. My final demonstration not only achieved that goal but established an extensible framework on which I could build more functionality.
By building a pipeline that first extracts information in a predictive, deterministic way, I’ve been able to greatly reduce the possibility of hallucinations. Including a chat layer has made it much easier for analysts to understand specific passages. With the incorporation of a text-to-query layer, I’ve enabled myself to ask broad questions of the entire dataset and consistently receive accurate answers.
I anticipate that more developers and machine learning engineers will increasingly adopt this design pattern in the near future, recognizing its potential to enhance data processing and analysis while mitigating the risk of errors.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Shahebaz Mohammad
Machine Learning Solutions Engineer
Renowned as a Kaggle Grandmaster and a LinkedIn Top ML Voice, Shahebaz is a seasoned Senior Applied Machine Learning Engineer at Snorkel AI. His prestigious career is studded with significant positions at leading firms like DataRobot, SocGen, H2O.ai, and Analytics Vidhya, affirming his relentless pursuit of AI advancement, and delivering value to Top US Banks.
Beyond his professional endeavors, Shahebaz is a beacon for the machine learning community, sharing insights that bridge theoretical knowledge with practical application, especially in burgeoning fields like Data Centric AI and Generative AI.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

