
Data science teams have made incredible progress in AI in recent years. A decade ago, you needed ML Ph. D.s in-house to build production deployable models. Between the proliferation of available models and team upskilling, that’s no longer true. But now those same teams must contend with enterprise LLM challenges.
This summer, I gave a presentation titled “Leveraging Foundation Models and LLMs for Enterprise-Grade NLP” at Snorkel AI’s Future of Data-Centric AI virtual conference. I’ve summarized more core thoughts from this presentation below.
The challenge with LLMs in the enterprise context
Perhaps the most exciting advancements lately are those surrounding large language models (LLMs), a topic Snorkel has researched and worked on for many years.
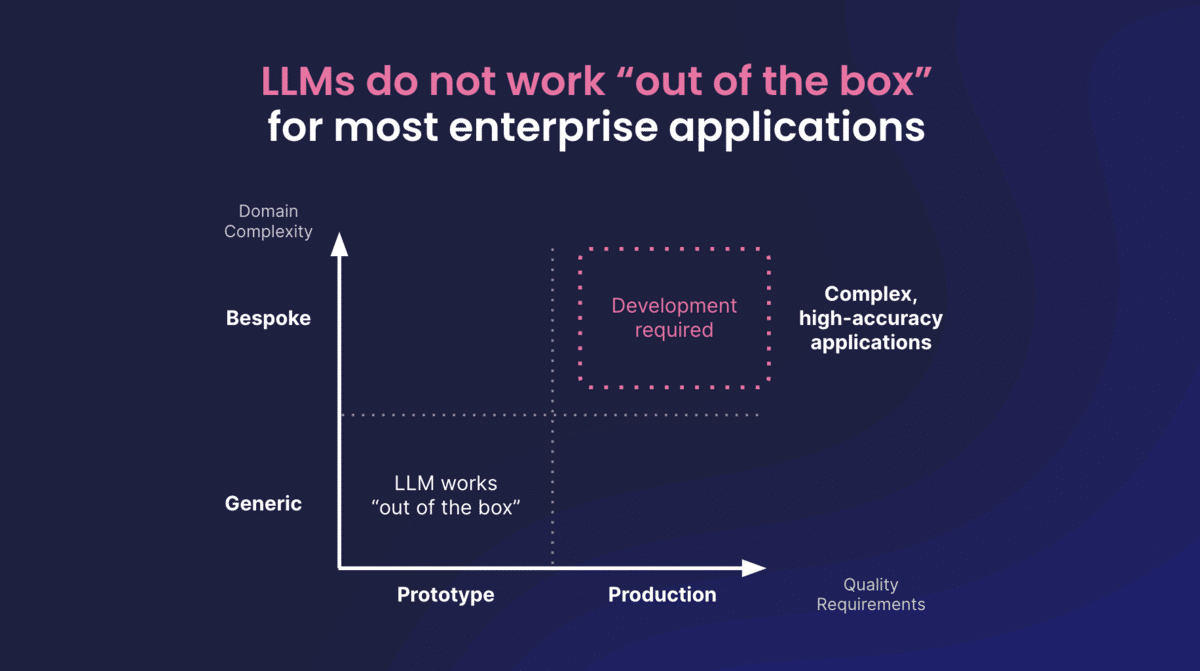
As exciting as these developments are, generic LLMs still don’t work out of the box for enterprise applications. Off-the-shelf LLMs are trained on generalized data. Businesses aim to solve specific problems, and generalized, out-of-the-box tools often fall short.
Enterprises set a high bar for quality and accuracy for core business processes and use cases. In domains such as banking, credit decisioning, insurance underwriting, patient risk assessment, clinical trial analysis, and others, the cost of a mistake becomes quite high.
There are two key challenges our customers still encounter with off-the-shelf LLM solutions.
- Low accuracy. Generalist models tend to achieve low accuracy on specialist tasks. How do you meet your accuracy requirements with generic LLMs when they lack the transparency necessary to track down model hallucinations and detect biased outputs?
- Deploying models within cost and governance constraints. When it comes time to put AI into production, different companies often have vastly different levels of infrastructure readiness and compute budgets. Off-the-shelf LLMs come with high costs. Additionally, some enterprise use cases require handling sensitive or confidential data, making public LLM APIs a non-starter.
How do you work through these challenges?
Snorkel believes that data-centric development is the best way to address these challenges. In a world dominated by multi-billion parameter LLMs, the older model-centric approach of tweaking model features and architectures to correct errors has become unsustainable. Instead, the data development layer has become more important for adapting enterprise-quality AI solutions.
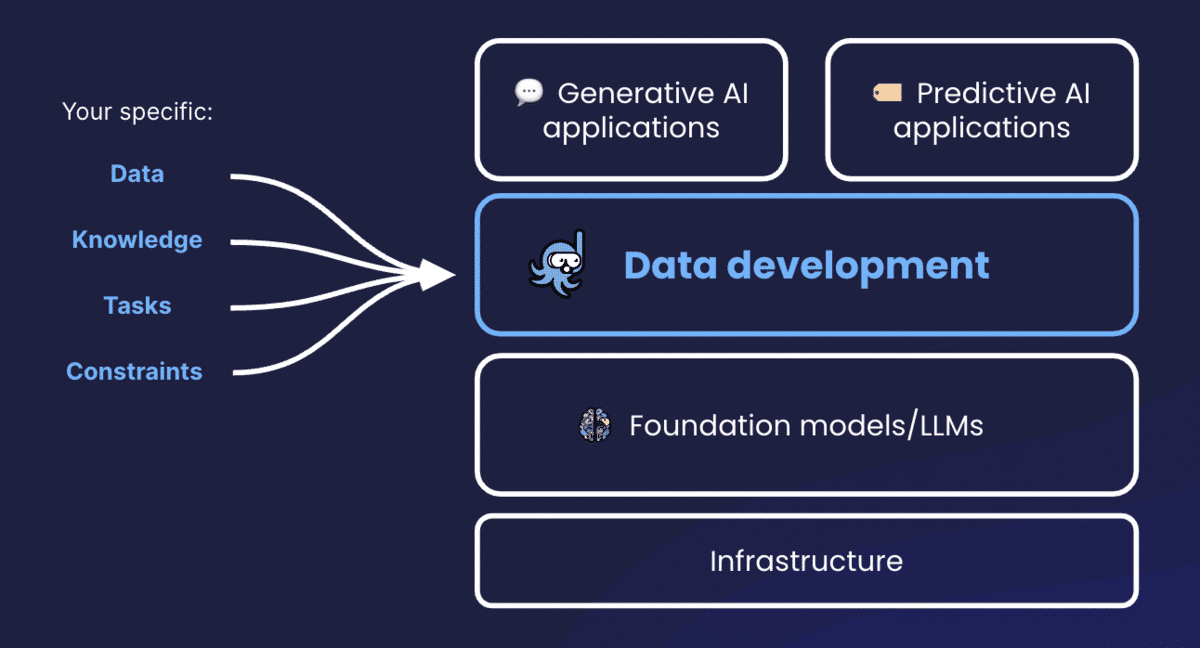
The data is the one constant you can control
The data development layer is now the key to enterprise-grade AI. Organizations need ways to harness and tailor the power of LLMs (a special subset of foundation models) to their data, their internal knowledge, and their bespoke tasks and constraints. The Snorkel Flow AI data development platform enables you to leverage data-centric techniques and programmatic data development to adapt LLMs to your needs.
Snorkel makes LLMs accessible in ways that can be used on-premises, but we also work with major cloud providers to facilitate a variety of tailored solutions.
While GenAI inspires a lot of excitement, most enterprises still find the majority of their AI value lies within predictive applications. In our experience, many businesses already have clear predictive use cases outlined with measurable ROIs. It’s the kind of AI that helps drive value for enterprises’ needs right now, today.
Often, businesses already have well-defined testing and evaluation criteria, so they know exactly what they’re looking for. Snorkel can help gather in-house knowledge and resources and translate them into domain-specific applications powered by robust LLMs.
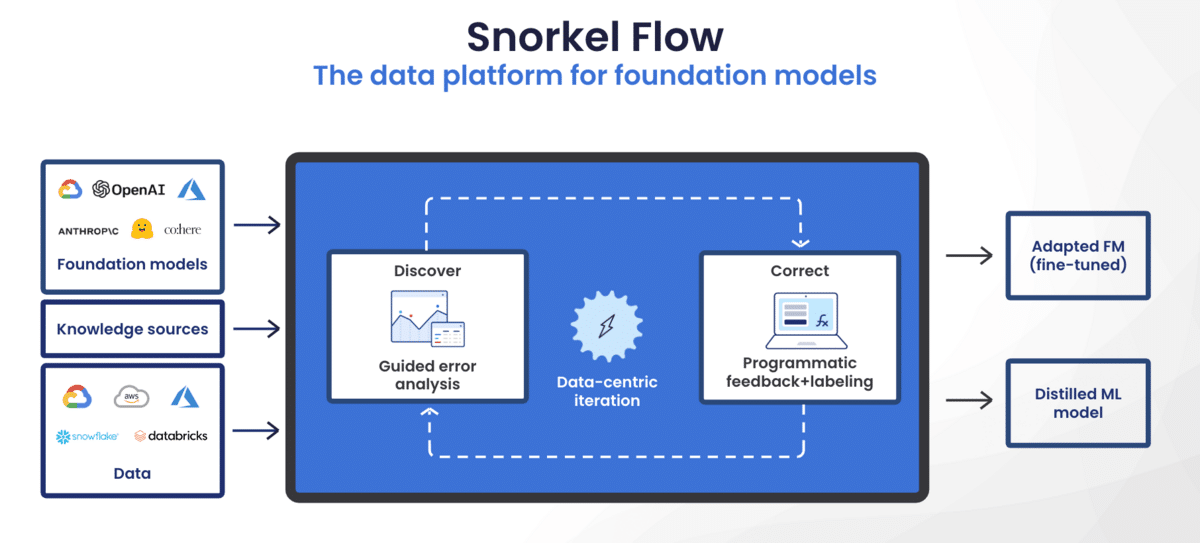
Snorkel Flow allows you to use any LLM with your data. Our data-centric tools allow users to create an iterative, programmatic loop. These features help you find, understand, target, and correct LLM errors in a systematic, scalable way.
Two Paths: Adapt or Distill
The platform offers two paths. You can deploy an adapted LLM, fine-tuned using data-centric iteration; or you can train your own distilled, bespoke ML model for your own in-house needs.
Adapt
Companies can use Snorkel to directly fine-tune LLMs and adapt them to their requirements. If your infrastructure enables deploying an LLM, but you’re still struggling to clear the accuracy bar you need with an off-the-shelf model, this is a great choice. Snorkel Flow helps you start with an LLM as a foundation, then use programmatic data development to iterate, address errors, and retrain the LLM on your data that meets your accuracy targets.
Snorkel offers a library of models to choose from. For example, users can choose GPT-3 and plug in their data to see what the predictions and accuracy look like. Then, through programmatic labeling and the iteration loop, you train your chosen model from there.
Once you meet your accuracy needs, you’re ready to deploy.
Distill
If you’re not yet ready to deploy an LLM due to cost and governance constraints, you can use the knowledge of an LLM to train another smaller, more easily deployed model. You still leave with a specialist model but at a lower cost than deploying something on the scale of GPT-3.5 or Llama 2 into production.
With distillation, you can get started with an LLM and plug in your data to get an initial baseline. In Snorkel Flow Studio, you’ll get immediate predictions, from which you can start drilling down on errors and analysis. But you don’t have to deploy the LLM you started with. Instead, you can choose a model from Snorkel’s library and then retrain that model until the accuracy meets your standards for deployment.
This approach results in models that cost orders of magnitude less to use at inference time. Advanced LLM distillation techniques can even create smaller models that often achieve higher accuracy than their parent models.
With Snorkel Flow’s tools and templates, you can connect with common LLM providers through one-click integrations. Our SDK also allows you to bring in custom models.
Case study
One of Snorkel’s customers, a pharmaceutical company, wanted to automatically extract information from plain-text clinical studies. The company not only wanted to extract the patient group and results, they also wanted to see the relationship between the two. They tried GPT-4 out-of-the-box, which achieved 66% accuracy—not nearly enough in a medical setting.
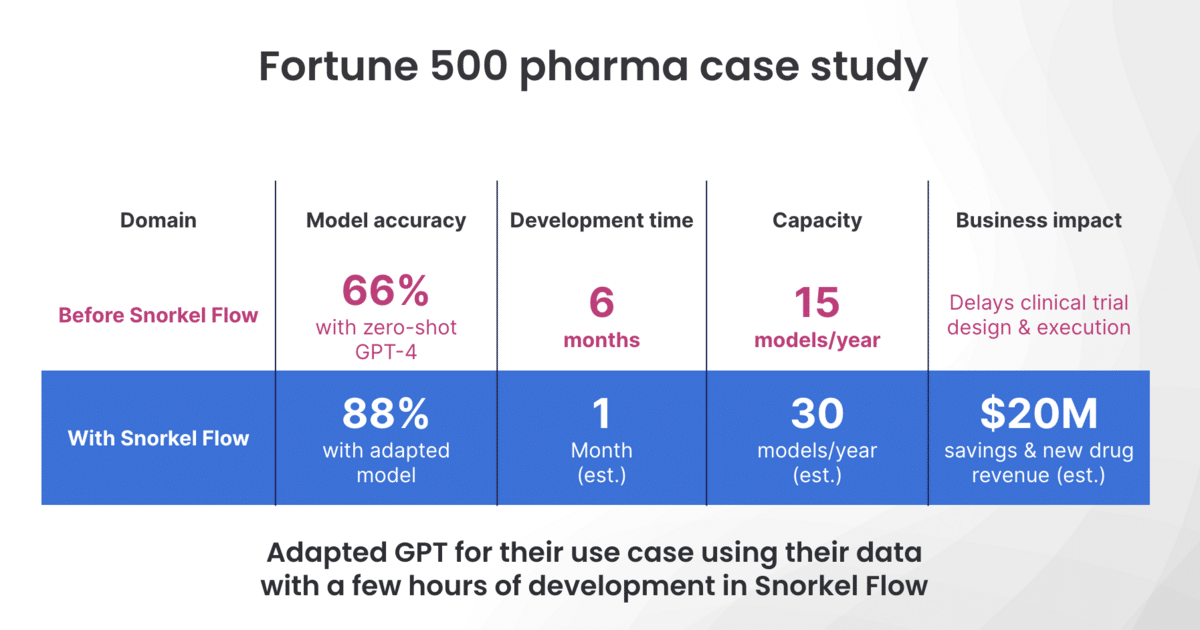
They then used Snorkel Flow with GPT-4 to train a smaller, production-ready model. They plugged in the off-the-shelf predictions, performed the iteration loop, identified and addressed errors, and refined and added to their labeling functions. This increased their results to 88%—a 22 percent increase—in just a few hours.
Which Snorkel Flow features contributed the most to that dramatic improvement?
Model-guided error analysis
LLMs lack transparency out of the box. It is challenging to locate and address errors efficiently. Snorkel Flow creates that transparency. The platform points users toward critical error slices. It then helps you understand how you can refine them and how to do so to get the biggest performance boost.
Programmatic labeling
In addition to models like GPT-4, Snorkel Flow labeling functions can use models like BioBERT, SciBERT, public ontologies like Wikidata, and many other resources to improve results by distilling the information into accurate probabilistic labels.
A smaller end model
Ultimately, this company deployed a smaller model that distilled the power of multiple LLMs to fit their data and their needs. That smaller model was more easily deployed and took advantage of cutting-edge AI without the accompanying governance and infrastructure demands.
Enterprise LLM challenges: data and customization are key
While LLMs are exciting, they still don’t meet the accuracy needs of many enterprises; they haven’t been trained on their particular data. They also challenge many organizations’ resource and infrastructure limits as well as their governance and privacy constraints.
The data-centric development tools in the Snorkel Flow platform offer a solution. They give users the ability to either adapt an LLM to their use cases or distill it and use it to train a smaller model. Snorkel’s programmatic, iterative data development tools allow users to iterate on their training data and evaluate errors to continually improve and adapt their models. This produces models with the power of today’s LLMs and FMs but tailored to your particular business needs.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Hoang Tran
Senior Machine Learning Engineer
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor’s degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

