Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Snorkel AI: Putting Data First in ML Development
Today I’m excited to announce Snorkel AI’s launch out of stealth! Snorkel AI, which spun out of the Stanford AI Lab in 2019, was founded on two simple premises: first, that the labeled training data machine learning models learn from is increasingly what determines the success or failure of AI applications. And second, that we can do much better than labeling this data entirely by hand.At the Stanford AI lab, the Snorkel AI founding team spent over four years developing new programmatic approaches to labeling, augmenting, structuring, and managing this training data. We were fortunate to develop and deploy early versions of our technology with some of the world’s leading organizations like Google, Intel, Apple, Stanford Medicine, resulting in over thirty-six peer-reviewed publications on our findings; innovations in weak supervision modeling, data augmentation, multi-task learning, and more; inclusion in university computer science curriculums; and deployments in popular products and systems that you’ve likely interacted with in the last few hours.Through all this academic tinkering and industry spelunking, we realized two things: first, that this concept of labeling and building training data programmatically, rather than by hand, had transformational potential to make machine learning more iterative, auditable, faster to deploy, and ultimately, more practical. And second, that these ideas changed not just how you label training data, but so much of the entire lifecycle and pipeline of ML: how knowledge and feedback is injected; how models are constructed, trained, versioned, and monitored; how entire pipelines are developed iteratively; and how the full set of stakeholders in any ML deployment, from subject matter experts to ML engineers, are incorporated into the process.In other words, we saw that this shift to programmatic training data required a top-to-bottom rewrite of the entire ML development and deployment process. With the support of some amazing investors (Greylock, GV, In-Q-Tel, and others) and incredible early customers, we’ve spent the last year doing just this: building and deploying Snorkel Flow, an end-to-end platform to support this new vision of the ML process.
The Training Data Bottleneck
Snorkel Flow was motivated first and foremost by a growing realization that training data had become the key bottleneck in much of ML pipeline and AI application development.

Today’s ML successes often rest on a hidden cost: massive, hand-labeled training datasets.
In the last decade, we’ve seen a tectonic shift in AI and ML towards powerful but data-hungry representation learning models. These models—often deep learning architectures—are not only more powerful at obviating traditionally manual development tasks like feature engineering and bespoke model design, but also have never been more accessible in the open source. However, there’s no such thing as a free lunch: these models are highly complex, with tens to hundreds of millions of parameters, and they require massive labeled training datasets to learn from. And, other than in special scenarios where labels are naturally derivative of existing processes, these training datasets need to be labeled by hand.
The hand-labeled training data interface to ML has enabled tremendous progress but is also ridiculously broken.
Consider a simple example: a legal analyst at a bank wants to train a contract classification model, and wants to inject a simple heuristic into the ML model: that if “employment” is in the title, the contract should be labeled as an “Employment contract.” Simple, right? Not so. Theoretically, to communicate this specific feature to a machine learning model via only labeling individual data points could require thousands of examples (roughly, inversely proportional to the sparsity of the feature space). From this perspective, it’s like playing 20 questions rather than just communicating the answer directly—fine if you have a massive question-answer bank, but otherwise wholly impractical.
Manually labeling training data is prohibitively expensive–especially when expertise and privacy are required.
Building training datasets often requires armies of human labelers at massive cost and time expense. For example, ImageNet—one of the foundational projects behind ML’s current explosive progress—took over two years to create. However, labeling cats, dogs, stop signs, and pedestrians is one thing; labeling data like medical images, legal and financial contracts, government documents, user data, and network data requires stringent privacy protections and subject matter expert labelers. This means for sectors like financial services, government, telecommunications, insurance, healthcare, and more, creating training data (and by extension, using ML) is either a hugely expensive on-premise activity—or more often, one that is just not feasible to tackle, let alone practical.Iterative development is not possible with hand-labeled data. From an engineering and data science perspective, manually labeled training data fundamentally breaks the ability to quickly iterate, which is absolutely essential in real world settings where input data, output goals, and annotation schema change all the time. From a business perspective, training data is an expensive asset that can’t be reused across projects, can often depreciate to worthless overnight due to changing conditions or business goals, and that presents growing risks—everything from COVID-related delays to issues of bias.
A New Input Paradigm for ML: Programming with Data
With Snorkel Flow, rather than needing to hand-label any training data, users develop programmatic operators that label, augment, and build training data to drive the ML development process.

Programmatically labeling and building training data. With Snorkel Flow, the idea is to instead communicate this domain knowledge directly via a programmatic operator like a labeling function. For example, our legal analyst could write a labeling function that labels documents as “Employment contracts” if the word “employment” is in the title, and otherwise abstains; or, a range of more complex and powerful labeling functions relying on internal knowlegebases, models, legacy heuristics, and more. This approach of effectively programming ML with data is simple, direct, interpretable, modifiable, and agnostic to the model used (which is especially important given the ongoing Cambrian explosion of powerful new open source model architectures).The directness of rules with the flexibility of ML. Rule-based systems have long been used in industry for certain tasks—as an input, individual rules have the desirable property of being direct and interpretable. However, rules can also be brittle, and lack the robustness, flexibility, and sheer power of ML approaches. With Snorkel Flow, you get the best of both worlds: rules (and other interpretable resources) as inputs, and powerful ML models that generalize beyond these rules as the output.
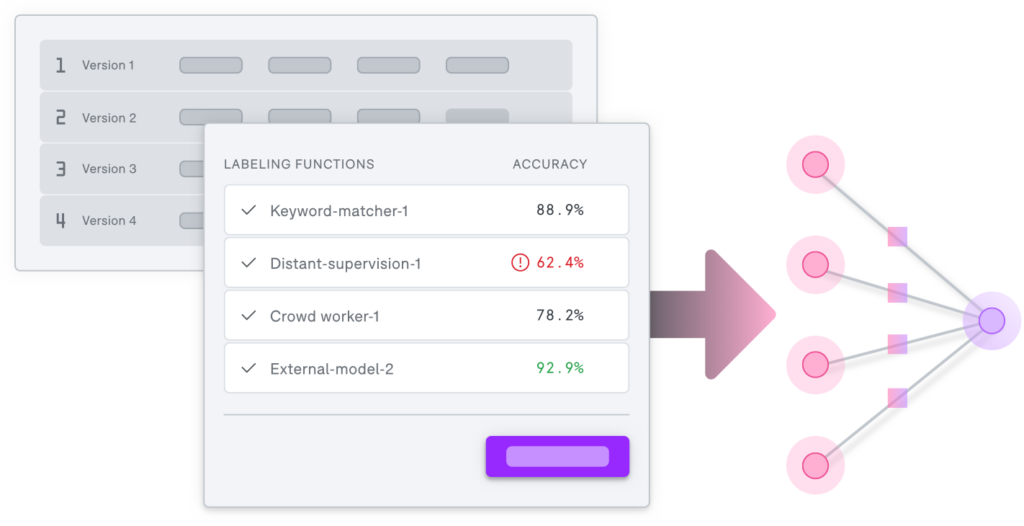
A more powerful yet weaker supervision. At the same time that this programmatic supervision is advantageous in several transformational ways, it is also messier and raises fundamental new technical challenges. The labeling functions and other programmatic operators that users write will have varying unknown accuracies and expertise areas, will overlap and disagree with each other, and may be correlated in tangled and unknown ways. We focused on the algorithmic and systems solutions to these issues over four-plus years of research, showing both empirically and theoretically that with the right techniques, these deep technical challenges can be overcome. The result: training data that is as good as or better than hand-labeled data, and immensely more practical to create and maintain.Beyond labeling: data augmentation, slicing, monitoring, and more. In high-performance production ML, training data is about a lot more than labeling. For example, data augmentation is a cornerstone technique wherein transformed copies of data (e.g. rotated or blurred images) are used to expand the sizes of training datasets, and make resulting models more robust. Slicing or structuring training datasets into more or less important and difficult subsets is also a critical part of managing production ML. Finally, monitoring and adapting not just models but also the training data that informs them is a critical necessity in any production-grade ML application. All of these operations have been the subject of our research and deployments for years, and now find a centralized home in our end-to-end machine learning platform for AI application development, Snorkel Flow.
The Snorkel Flow Platform: A New, Data-Centric Way to Build ML
Through years of deployment experience, we realized that this new programmatic approach is not just about training data—it transforms the entire way one builds, deploys, monitors, and maintains ML-driven applications. Over the last year we have been building the end-to-end platform supporting this new approach to ML: Snorkel Flow.

An ML development process centered around the data. Snorkel Flow enables users to drive the end-to-end process of developing and deploying ML-powered applications by iteratively and programmatically labeling, augmenting, and building training data. Users start by developing programmatic operators, ranging from simple labeling functions developed in a push-button UI (e.g. expressing rules or heuristics), to complex custom operators bringing diverse sources of signal to bear (e.g. existing models, labels, knowledge bases, etc.) via the Python SDK. Snorkel Flow automatically cleans and manages the output of these operators–also integrating any hand-labeled data or other sources of signal if available–and then uses this to train state-of-the-art models, either push-button or via SDK. For more details, see this page.An iterative, actionable development and monitoring loop. A key design principle behind Snorkel Flow is that successful ML development processes must be fundamentally human-in-the-loop–push button automagic solutions simply do not work in the real world–but that these loops should give users clear, actionable guidance at each turn. In Snorkel Flow, monitoring and analysis guides users to rapidly identify and correct error modes in their training data and models. The net effect: AI as an iterative development process, rather than a one-and-done exercise bound by the data.Building and deploying end-to-end AI applications, beyond just models. One of the key principles is Snorkel Flow is that ML application development is all about the data—and not just the training data, but the various pre-processors, post-processors, connectors, and overall workflows around the ML models that make up any real production application. Snorkel Flow provides an end-to-end environment for building these full data workflows, and deploying them as APIs with the push of a button.A developer-first platform that is all about cross-functional teams. Successful AI solutions require collaboration across teams and roles- from the subject matter expert’s knowledge and objectives to the machine learning engineer’s deployment pipeline. Snorkel Flow is built to be both developer-first—with full SDK and CLI access and configurability at every stage—as well as empowering and explicitly including other key roles, with push-button UIs and specific managed workflows for integrating subject matter experts, business stakeholders, and others.
Snorkel AI: The Pathway Forward
What we’ve built with Snorkel Flow so far has been entirely dependent on partnerships with some amazing early customers (including several top US banks, government agencies, and other large enterprises), an incredible group of top-tier investors (Greylock, GV, In-Q-Tel, and others) who have actively supported us the whole way, and a truly once-in-a-lifetime team of engineers from places like Google, Facebook, NVIDIA, etc. and academics from places like Stanford, UW, Brown, Wisconsin, etc.Moving forward, we are excited to continue partnering with a select set of the best teams and organizations from sectors like finance, government, telecommunications, insurance, and healthcare to deliver rapid bottom-line value while also helping us evolve our platform. If you are interested in being one of these early partners, please reach out here.And, of course, could our company really be based in Palo Alto if we didn’t say the following: “We’re hiring!”? Please check out our jobs page if you’re interested in being part of a highly technical, world-class team at the cutting-edge vanguard of a new intersection of ML, data, and systems with significant and immediate real-world impact.There’s a lot more coming that we are very excited to announce—in the meantime, stay tuned!

Alex Ratner
Alex Ratner is the co-founder and CEO at Snorkel AI, and an affiliate assistant professor of computer science at the University of Washington. Prior to Snorkel AI and UW, he completed his Ph.D. in computer science advised by Christopher Ré at Stanford, where he started and led the Snorkel open source project. His research focused on data-centric AI, applying data management and statistical learning techniques to AI data development and curation.