
Fine-tuning large language models for specialized domains and tasks demands a lot of time and cost—and often requires a lot of manual human labeling. That’s why I and my fellow students and advisors at Brown developed Bonito: we wanted to make this process faster, cheaper, and easier.
Bonito converts unannotated text from specialized domains into synthetic instruction-tuning datasets. We have experimentally proven that Bonito’s synthetic data significantly boosts the performance of large language models (LLMs) on specific tasks and domains.
I recently presented my team’s work to researchers at Snorkel AI during a live webinar. You can watch a lightly-edited version below—and I recommend it; the Snorkelers asked some great questions!
If you don’t have time for the full video, I have summarized the main points of my presentation here.
Why we built Bonito
Key idea: Meta – templates!
Zero-shot task adaptation presents a significant challenge in machine learning—particularly in natural language processing.
Data scientists who want strong zero-shot performance in specific domains must create high-quality models through instruction-tuning. Building data sets for this task can be incredibly expensive, especially in specialized domains where collecting training data is costly and time-consuming.
This is where Bonito comes into play. It offers an innovative solution that enables us to achieve low data cost while still developing a high-quality model.
Essentially, Bonito allows us to have our cake and eat it too.
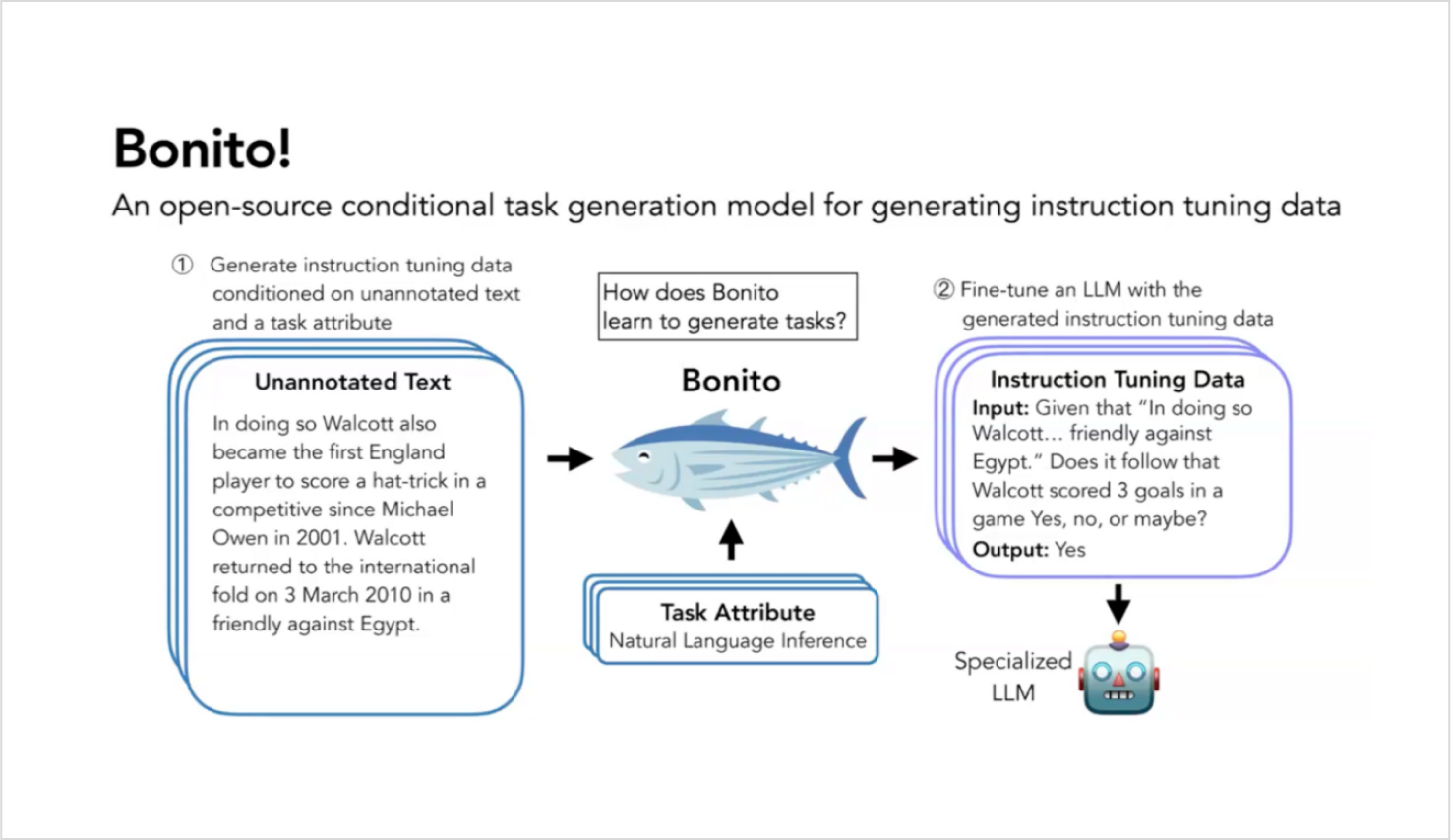
How Bonito works
Adapting pretrained models
The process began with training the Bonito model on common natural language processing task types, each of which relies on examining a passage of text. These tasks include question-answering, natural language inference, and summarization.
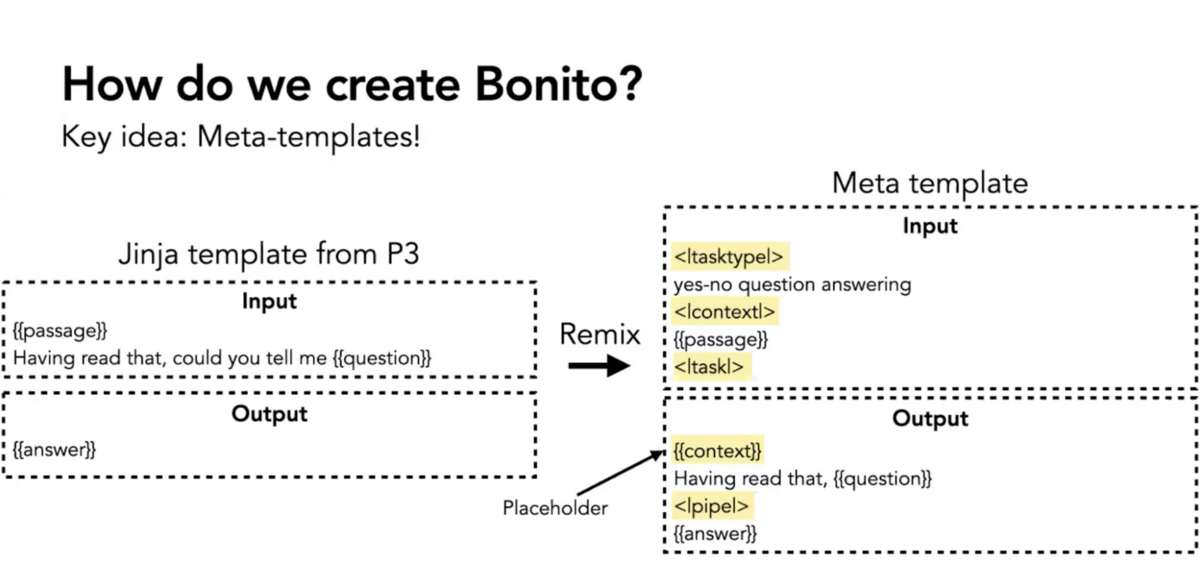
We identified templates in NLP datasets that reason over passages. These templates have placeholders for the columns in the dataset such as question, answer, summary, and more. We then reorganized or remixed these placeholders to create meta-templates.
The meta-template allowed us to take a passage and a task type and return a fully populated instruction-tuning pair. Using these meta-templates, we created 1.6 million training examples across 16 task types. We call this the “conditional task generation with attributes” dataset. We used it to fine-tune Mistral 7B to create Bonito, a model well-trained to create instruction-response pairs.
Here’s an example of how this works. Suppose we have a complex paragraph from the PubMed dataset, and we want to generate a yes-no question-answering task. We send this paragraph along with the task type to Bonito. Bonito then generates a challenging instruction with an accurate response.
By repeating this process, we synthesize a dataset from the specialized domain. We then use this data to train another model and adapt it to the target tasks.
Bonito in action: experiments and results
To evaluate Bonito’s effectiveness, we conducted multiple experiments using various datasets.
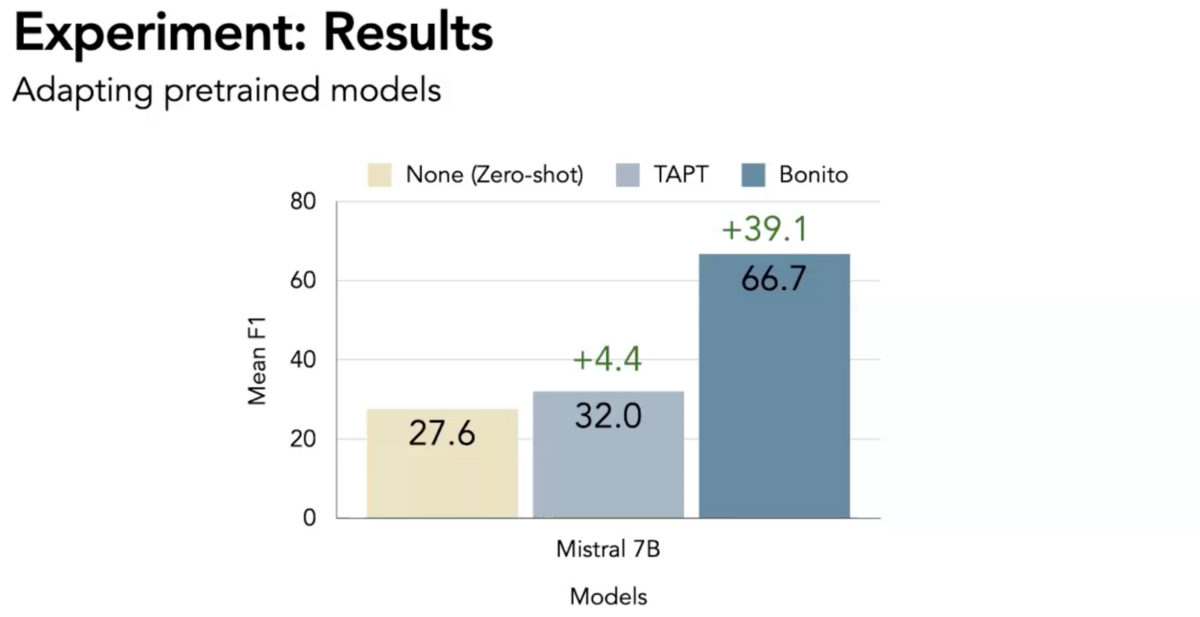
The results were impressive across all tasks. On average, the baseline Milstral 7B model achieved an F1 score of 27.6 on a test set. On the same test set, versions of Mistral 7B fine-tuned with Bonito synthetic data achieved an average F1 score of 66.7—a 39.1-point improvement.
We also examined Bonito’s ability to further adapt previously instruction-tuned models. For example, we adapted the Milstral 7B + P3 model with yes-no domain-specific Bonito instructions. The baseline models achieved a mean F1 of 52.8. The Bonito-enhanced models achieved an F1 of 67.8—a 15.1-point improvement.
These results become more impressive when compared to self-supervision. Self-supervision actually decreased model performance by interfering with previous instruction tuning. Our Bonito-enhanched models did not suffer from this challenge, known as “catastrophic forgetting.”
Bonito’s future
As we refine and develop Bonito, we see areas for potential growth and improvement.
First, we aim to enhance the quality of synthetic datasets generated by Bonito. While the current version has shown promising results, we believe we can reduce the noise in the generated datasets. This could involve mechanisms to identify and filter for high-quality instruction response pairs.
Second, we see the potential to expand Bonito’s capabilities to handle a broader range of tasks.
Third, we may explore how Bonito can adapt to completely new domains. While our current experiment setup ensures that the training and test datasets do not overlap, we’re curious to see how Bonito performs when faced with truly new domains.
Last, we aim to make Bonito more accessible. We plan to continue to develop and maintain it as an open-source model, making it available for other researchers and developers to use, modify, and improve upon.
Bonito: easing the creation of fine-tuning datasets
The development of specialized language models is and will continue to be an important task in machine learning. Our open-source model, Bonito, presents a promising solution by creating synthetic datasets in specialized domains. By doing so, it offers a cost-effective approach to achieving high-quality models.
While we have made significant strides with Bonito, there is still much more to explore. The path of future development is exciting and full of potential. We look forward to continuing our research in this fascinating area.
Additional resources
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Nihal Nayak
Ph.D. candidate
Nihal V. Nayak is a fifth-year Ph.D. student in the Department of Computer Science at Brown University, where he is advised by Stephen H. Bach. His research focuses on zero-shot generalization in deep neural networks and, more broadly, on learning with limited labeled data. His work has been published in leading machine learning conferences and journals, including ICLR, TMLR, ACL Demo, EACL Findings, and MLSys.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

