
Labeling data manually can be a grind. Snorkel Flow slashes labeling time from months to minutes using programmatic labeling and weak supervision techniques. As part of the automated labeling process, data scientists and domain experts collaborate by creating labeling functions. Snorkel Flow offers two unique capabilities that further supercharge collaboration between subject matter experts (SME) and data science teams: Comments and Tags.
Comments and tags facilitate collaboration and communication between the subject matter experts (SME) and the data scientists who write labeling functions. Labeling functions codify known signals – from rules and heuristics to existing models – into a set of guidelines for how data points should be labeled. Data scientists understand how to write the labeling functions, but lack the expertise to know what those functions should do. Subject matter experts understand what the functions should do, but require support to create advanced and code-based labeling functions. Comments and tags help close that gap.
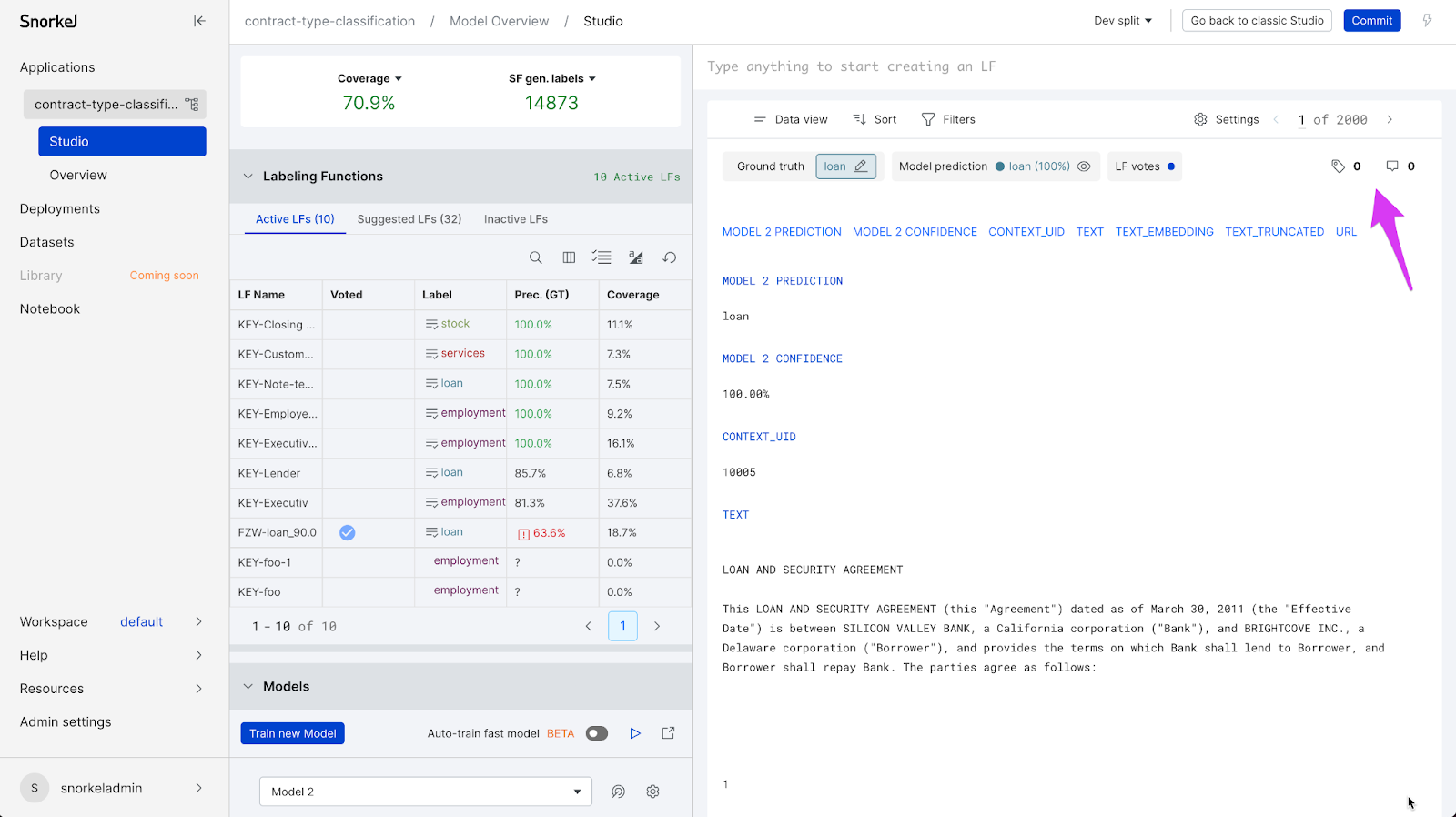
Additionally, viewing, creating, updating and deleting tags and comments can be done programmatically via Snorkel Flow’s python SDK.
Although the usage of comments and tags will vary based on your use case, there are a few best practices when getting started:
1. Use SME comments as inspiration for labeling functions
During the annotation process, encourage SMEs to use comments to explain the rationale behind why they’ve labeled a document a certain way. This serves as a valuable insight for the data scientists as they build and refine labeling functions. Include this instruction in your annotation guidelines.

Additionally, SMEs have the ability to suggest labeling functions that will expedite the programmatic labeling process and help the DS team get started.

2. Capture insights
Encourage your data scientists and SMEs to exchange insights via comments with ease. This lets future team members leverage existing knowledge and expertise from past work on the project. Tags serve as top-level clusters for data points, and details and discussions can be tracked in the comments. Traditional approaches tend to silo the data providers and the data scientists, but Snorkel Flow aims to provide a single interface for both teams to communicate as they refine the data.

3. Define and document a tagging schema
Based on your problem formulation, you can identify the main categories to incorporate into your tagging schema. These could consist of (but are not limited to):
- Incorrect-gt: Data scientists may feel that some ground truth was incorrectly categorized. Items with this tag can be passed back to SMEs to re-evaluate ground truth.
- More than one class: This tag category indicates data points that could be considered two or more classes. If enough data is tagged by your annotators in this manner, it may suggest that the problem should be restructured into a hierarchical or multi-label approach.
- Not-enough-info: This tag category signals that the data is not rich enough to programmatically label or for the model to generalize. This can be done ad-hoc or programmatically via the SDK based on some criteria like character length. For example, if you’re trying to predict a loss type based on claims notes, you may want to tag any claims notes that are less than 50 characters, as that may not be enough information for the model to arrive at a confident prediction.


4. Use tags for error analysis and project readouts
After tagging data across your splits, you can leverage analysis tools in Snorkel Flow to examine model metrics across tagged data. This technique allows you to explain what concrete action could improve model performance as well as the estimated magnitude of a performance boost your model would gain from such an action.
For example, in the screenshot below, we can see that if 23 data points in the valid set contained more contextual information from the claim, the model would likely be able to correctly predict the outcome, leading to a 23% bump in F1 score. Contextualizing model performance can help business stakeholders understand how up or downstream impacts to the datasource can improve the bottom line outcome and business impact of the project.


Final thoughts
Leveraging tags and comments in a data-centric workflow unlocks collaboration between data scientists and SMEs that is lost when labeling manually. Embedding these async communication methods alongside your data during the labeling process eases that collaboration. This, in turn, helps your team build production-grade AI applications for your company faster.
Visit www.snorkel.ai to see a live demo of Snorkel Flow.

Marty Moesta
Lead Product Manager, Generative AI
Marty Moesta is the lead product manager for Snorkel’s Generative AI products and services, before that, Marty was part of the founding go to market team here at Snorkel, focusing on success management and field engineering with fortune 100 strategic customers across financial services, insurance and health care. Prior to Snorkel, Marty was a Director of Technical Product Management at Tanium.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

