Join our inaugural Reading Group in San Francisco on April 29. Register now
Snorkel Flow 2022 year-end release roundup
2022 was a big year for Snorkel AI. On the product front, we shipped major innovations for data-centric AI workflows and enhancements to Snorkel Flow, including
- Data-centric adaptation and deployment of foundation models and LLMs
- Continuous model feedback to drive data quality improvement
- Foundation model- and embedding-based analysis & auto-labeling
- Multiple new data & ML task types
- Annotation workflow features for subject matter experts
- Advanced access controls with Team Workspaces
- Integrations w/ Snowflake, Azure, GCP, MLflow, and more
These product ships continue to accelerate enterprise AI development and deliver outsized ROI with automated labeling, efficient collaboration, and rapid, model-guided iteration.
The Snorkel R&D team spent the last few months focused on advancing data-centric AI workflows with a new data summary pane, an expanded set of auto-suggest LF algorithms, quickstarts for annotators, annotation data viewer, support for high-cardinality text classification and extraction in Cluster View, improved metrics for multi-polar LFs, increase in training data set creation and model training speed and accuracy for complex tasks (multi-label, sequence tagging, or advanced PDF processing), Google BigQuery integration, and more.
Dive deep into this article to learn about the most recent ships that set us up for a bigger 2023!
If you want to see Snorkel Flow in action, sign up for a demo. 👈
New Studio experience gets more data-centric
To bring even more insight about your data front-and-center as you work, we’ve added a new data summary pane to visualize data with an embedding map. As you search and filter your data within New Studio, clusters automatically display to show label distribution and top n-grams within that search. This helps you understand the behavior of potential labeling functions (LFs) and surfaces new patterns to consider.
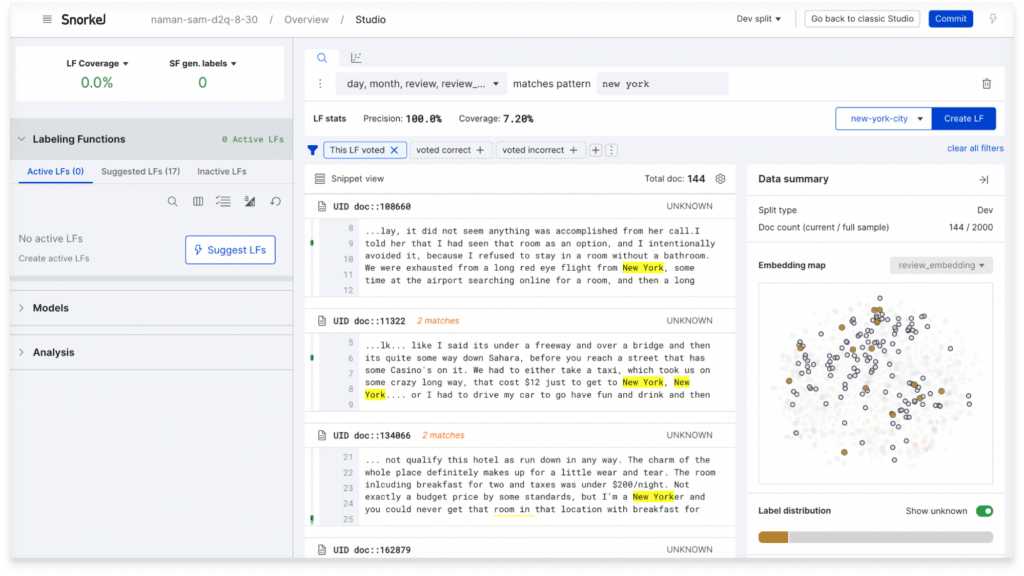
More automation value packed into programmatic labeling
With this release, auto-suggested LFs are even easier to review and accept, building on the 10-100x development acceleration programmatic labeling already delivers. Under the hood, we’ve also expanded our auto-suggest algorithms to support more complex ML tasks, including text multi-label and high-cardinality classification and text information extraction applications.
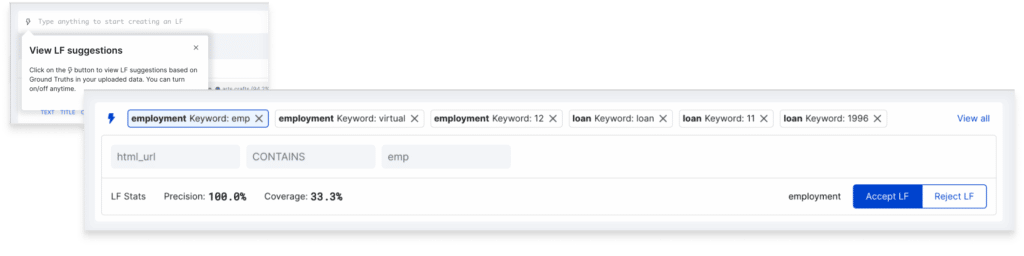
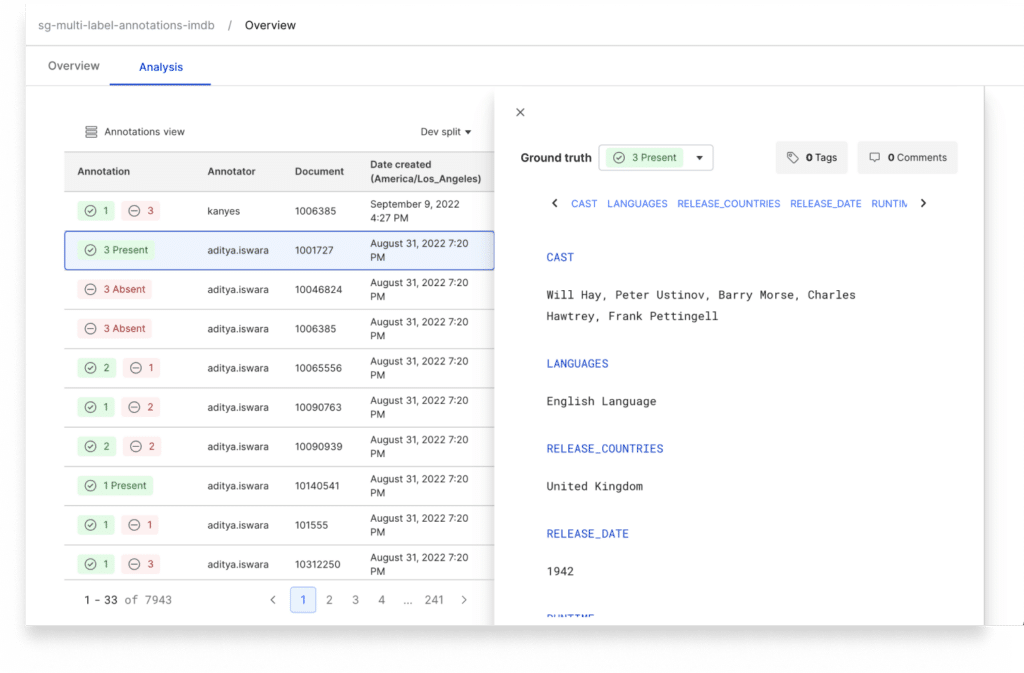
Faster workflows for subject matter expert collaboration
From quick-starts and new shortcuts for annotators to fresh tools for annotation reviews and quality assurance, Snorkel Flow’s Annotator Suite has been elevated further with this release, increasing knowledge share between domain experts and data scientists.
“With Snorkel Flow, subject matter experts are regularly in the data which gives me insights and ideas for experiments that wouldn’t otherwise surface.”
James Dunham, NLP engineer
Georgetown University Center for Security and Emerging Technology (CSET)
A crowd-favorite to highlight is the new annotation data viewer integrated into the annotation review space. Reviewers have many options to customize the split pane experience and take action if the annotation doesn’t match expectations by commenting or tagging to flag for correction.
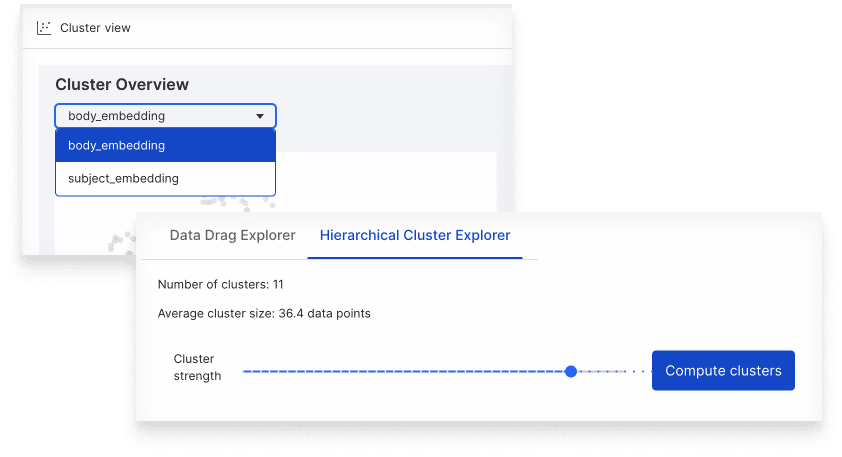
Expanded Cluster View capabilities
Cluster View, which speeds data exploration and uncovers patterns to be applied as LFs, now supports high cardinality text classification and text information extraction problems. We’ve also added new hierarchical clustering capabilities to explore data even without ground truth, with controls to adjust the cluster strength.
Another new source of insight and control with Cluster View is the ability to toggle between embeddings when you’ve added additional embeddings to your application (beyond the default Snorkel Flow option).
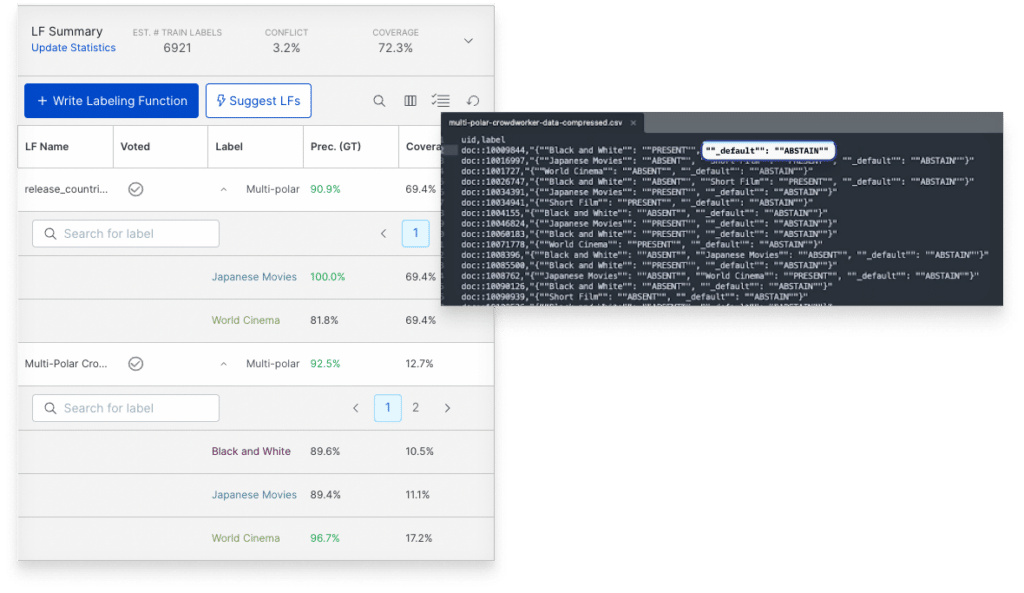
Accelerated labeling function development
In our last release, we introduced multi-polar labeling functions (LFs) to support high-cardinality use cases by outputting more than one class (consolidating labeling logic and speeding LF development). With this release, we’ve improved the metrics available to you and, for multi-class multi-polar LFs, you can now use the default key for compressed formatting.
Deepened support for complex use cases
Enterprise teams building more challenging multi-label applications can use more granular insights across classes, seamlessly update label schema in response to changes, and increase model accuracy with the latest label model we’ve added to our model zoo specifically for multi-label applications.
In our Summer release, we delivered multi-highlighting capabilities to provide a single view of ground truth labels and votes from any labeling functions, training sets, and models. We’ve brought highlighting to snippet view to streamline document review as you build sequence tagging apps for information extraction. We’ve also increased the speed for training set creation by 200% and model training by 50%.
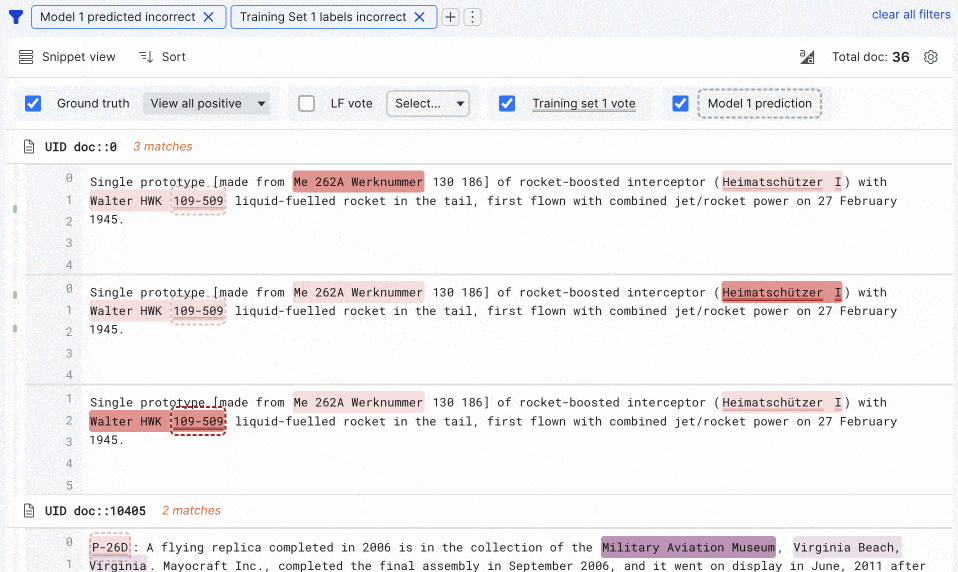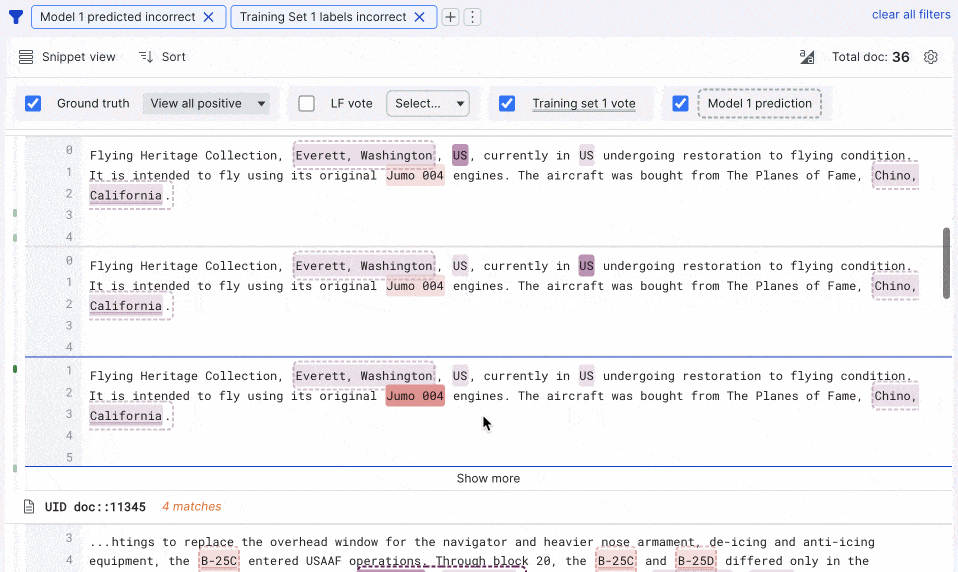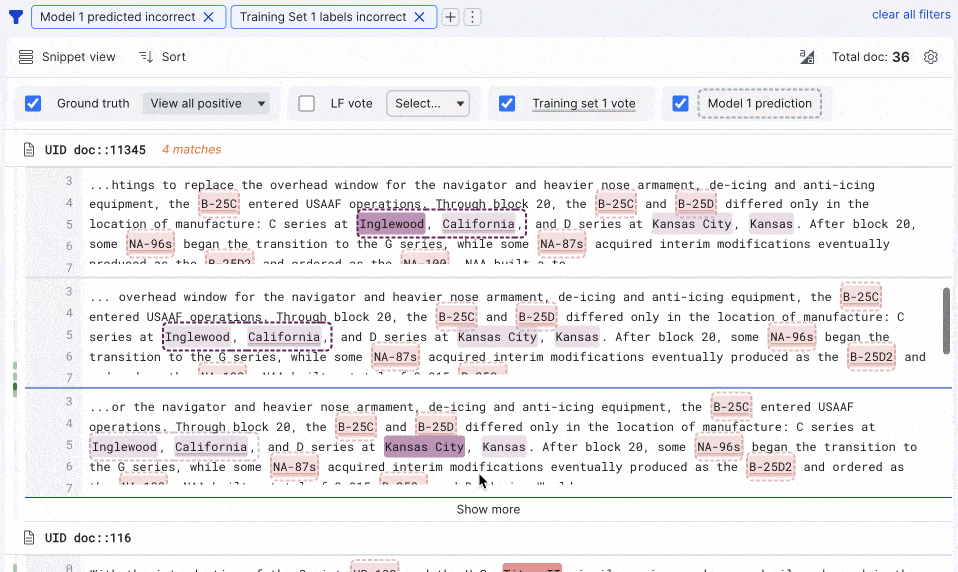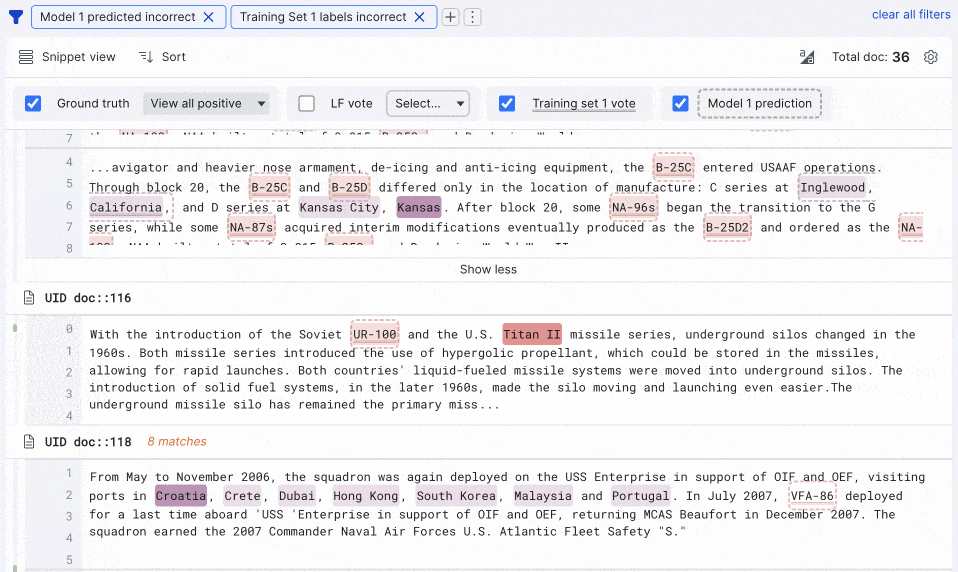
Lastly, for those working with advanced PDFs, it’s now easier to preprocess, split pages, and iterate on span extractors from the SDK notebook, and new, best-in-class document models (LayoutLM v2 and v3) are now integrated into Snorkel Flow. We’ve seen impressive empirical gains with these models, so we took the next step to build them into our model library for you.

Enhanced multi-user collaboration
To help enterprise teams work more efficiently, Snorkel Flow now offers granular controls to merge and reuse assets (such as ground truth labels, data annotations, labeling functions, tags, or comments) across models and applications within a workspace.
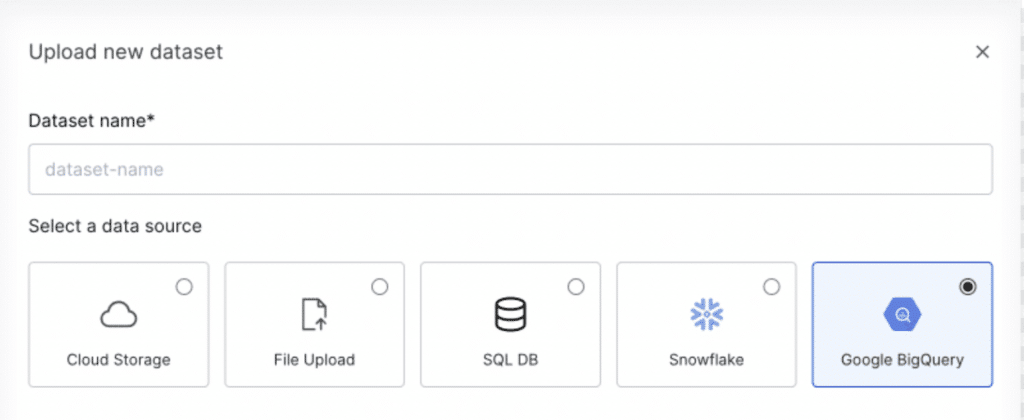
Increased project velocity with BigQuery integration
We’ve added data ingest support for Google BigQuery, a fully managed enterprise data warehouse that supports structured, semi-structured, and unstructured data. With just a few clicks, data scientists can use the built-in connector to seamlessly pull data directly from BigQuery, making foundational workflows more efficient.
Let’s dive deeper
Celebrate the start of 2023 with us during our upcoming Release Roundup webinar in February to see highlights from this release in action, along with a few previews of what’s coming next.
If you want to see Snorkel Flow in action, sign up for a demo. 👈

Aparna Lakshmiratan