Improve RAG retrieval accuracy
Ensure LLM responses are grounded by business and domain knowledge with document metadata, optimized chunking, and fine-tuned embedding models.
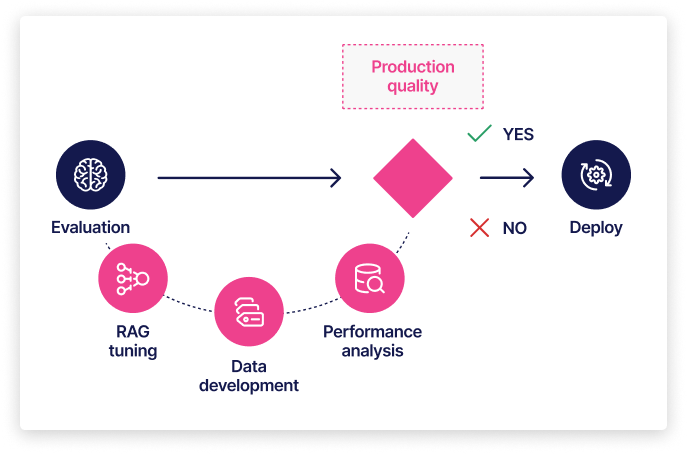
Optimize RAG to ensure LLM responses are grounded by SME knowledge
Meet production accuracy needs
RAG pipelines often fail to meet production accuracy needs out of the box, but optimization can yield significant improvements in retrieval accuracy—and thus LLM response accuracy.
Reduce inference token costs
With more precise chunking and accurate retrieval, only the most relevant information is added as context for the LLM, reducing the number of input tokens—and thus inference costs.
Improve LLM response quality and latency
Overcome training data shortages
Snorkel Flow can generate synthetic prompts from unstructured data by prompting foundation models such as OpenAI GPT and Meta Llama to augment existing training data.
Why do standard RAG pipelines fail to generate accurate responses?
While out-of-the-box RAG pipelines are an easy way for enterprises to get started with LLMs, they often fail to meet production accuracy requirements. The problem is they simply don’t know enough about the domain to ensure the right information is being fetched. However, once adapted to enterprise documents and use cases, they can consistently provide LLMs with the most relevant and helpful context—nothing more, nothing less.
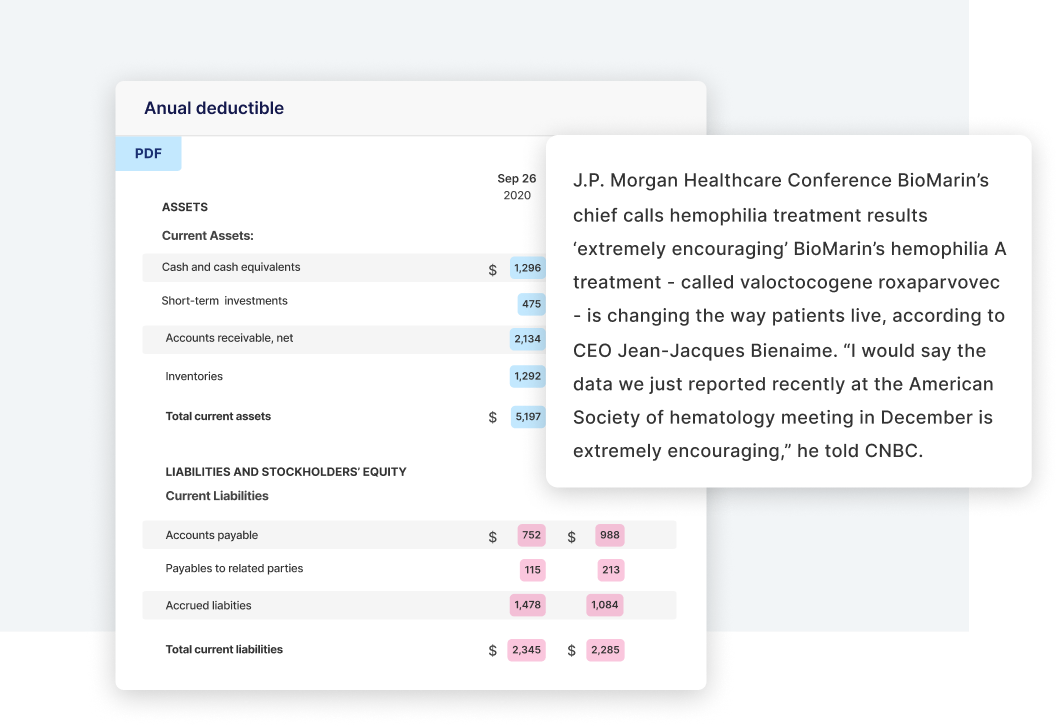
Add document metadata to improve search
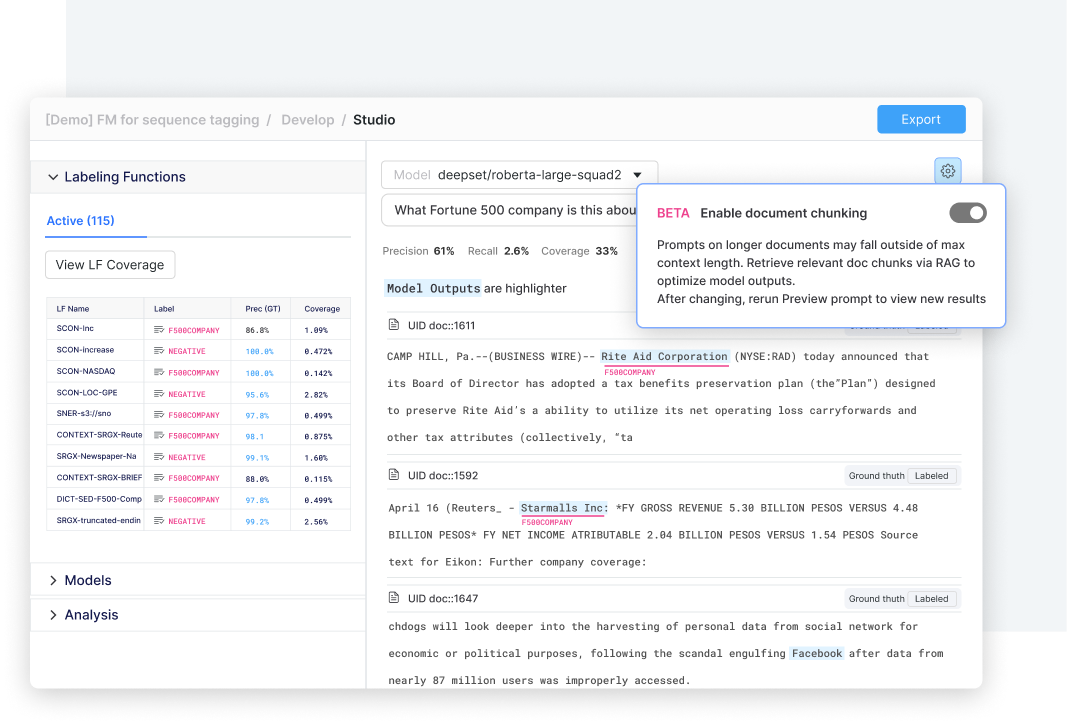
Optimize chunking to remove noise
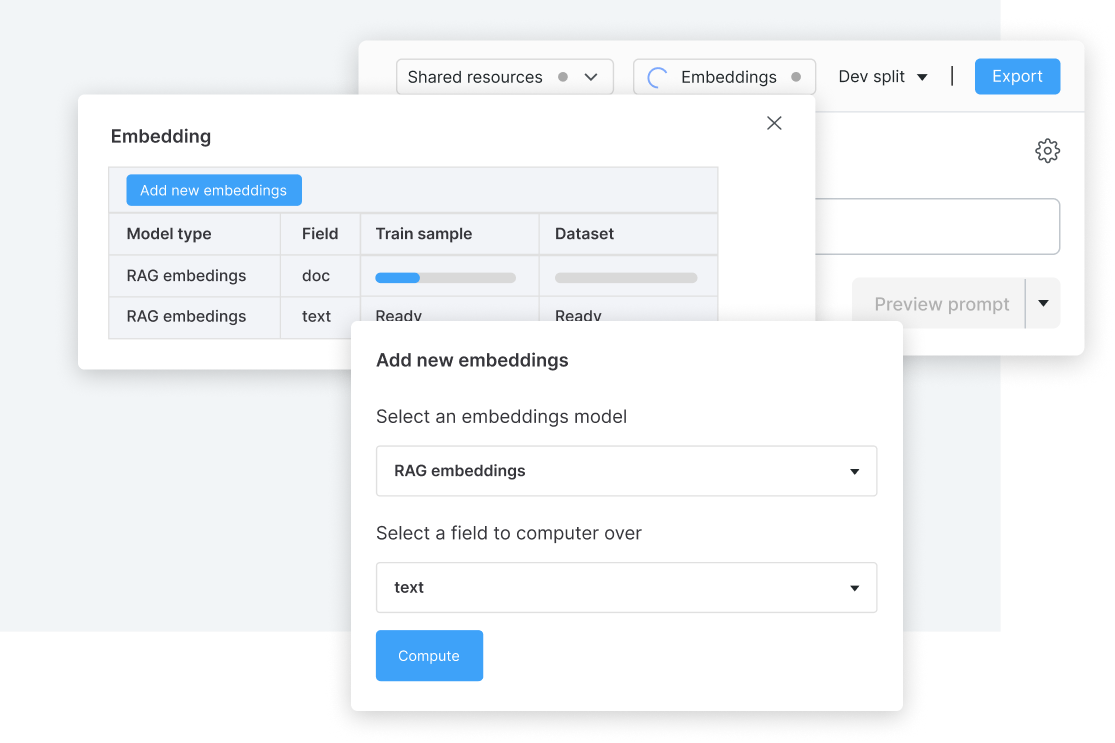
Fine-tune models to improve accuracy
Dive deeper into RAG optimization with these resources
Deploy specialized AI to production today with Snorkel
Deploy specialized AI to production today with Snorkel
Snorkel Flow
A complete platform for rapid and auditable data labeling, RAG optimization, model fine-tuning, and LLM evaluation. Trusted by enterprise data science teams to build specialized production AI.
Snorkel Custom
Our team of experts will fast-track specialized model development on your data to reduce model development costs, accelerate time to production, and achieve higher model quality.