
In today’s rapidly evolving AI landscape, achieving language model alignment is critical for addressing AI safety concerns and ensuring models adhere to common human values. Leading companies, including OpenAI and Anthropic, have made significant investments to enhance model alignment.
As machine learning researchers, we are tasked with developing efficient methods to achieve these goals—and the path to many of these methods runs through weak supervision. I and my colleagues at the University of Wisconsin-Madison have been working on expanding this approach to new applications, with notable results.
I recently presented two weak supervision-related research papers I worked on to an audience of Snorkel AI researchers. You can watch an edited recording of the presentation (embedded below). I have also summarized the presentation’s main points here.
What is weak supervision?
Snorkel AI has thoroughly explained weak supervision elsewhere, but I will explain the concept briefly here.
Weak supervision offers a cost-effective tool to mitigate the challenges of human annotation. At its core, weak supervision collects and reconciles noisy or imprecise labels from sources ranging from human labels to inputs from other models to simple heuristics. By leveraging these sources of signal as labeling functions, we can aggregate weak signals to estimate more accurate label distributions.
Snorkel has used this approach for years to amplify the impact of businesses’ subject matter experts. Classically, this approach has been limited to classification challenges, but my colleagues and I have devised approaches to apply weak supervision to new sets of tasks.
Extending weak supervision to non-categorical problems
Our research presented in our paper “Universalizing Weak Supervision” aimed to extend weak supervision beyond its traditional categorical boundaries to more complex, non-categorical problems where rigid categorization isn’t practical.
Ranking problems exemplify this challenge. Traditional labeling functions return a label, but labeling functions for ranking must provide a permutation of items. This can vary in complexity from fully-specified rankings to partial ones.
The core of our approach aims to reorient weak supervision to minimize a distance metric chosen for the challenge. For example, in ranking scenarios, we use Kendall Tau distance, which measures how many adjacent swaps are required to make two permutations identical. For example, correcting a prediction of 312 to 123 would require two swaps: first the one and three, then the three and two. This provides a quantifiable measure of similarity between rankings and allows us to harness weak supervision in a mathematically rigorous manner. Our “universal” label model minimizes our distance metric rather than maximizing label correlation.
In practical terms, we’ve implemented these ranking strategies to improve model performance significantly. Our experiments validated that by adding more labeling functions, we could achieve accuracy comparable to human annotations.
This approach could help better align large language models (LLMs) by accurately modeling human rankings for model responses.
While my presentation focussed on ranking, this same weak supervision framework applies to many challenges with distance metrics, such as regression models or graphs.

Using “weak” models to align strong ones
The increasing capabilities of AI models have raised concerns about their alignment with human values. Language model alignment is crucial for addressing long-term AI safety concerns and practical purposes, such as ensuring company policy compliance in generated responses.
Traditional alignment methods rely on datasets where human annotations label which model responses are preferred. However, creating these datasets is resource-intensive and prone to human error. This is where weak supervision steps in.
Inspired by OpenAI’s alignment studies, we investigated how strong models (like GPT-4) could be trained using pseudo labels generated by weaker models (like GPT-2). Our experiments found this quite effective. The smaller model quickly learned to apply labels based on “easy” features. Our larger model learned how to generalize these labels to “harder” features.
To illustrate this, imagine a picture of a car. A child may look at the picture and identify the car based on the presence of wheels. An adult would identify the car based on the body shape, headlights, rearview mirrors, and windshield. This allows the adult (the “strong” model) to identify a car that has had its wheels removed. Now imagine the child teaching the adult about a topic the adult doesn’t understand and you have your intuition.
Our research found that weak-to-strong generalization becomes more effective as the number of training examples that contain both “easy” and “hard” data patterns increases. This allows our “weak” model to accurately predict correct labels and the “strong” model to correctly generalize those predictions to a wider set of features.
That, however, left the challenge of tagging “easy,” “hard,” and “easy+hard” data. To identify the overlap densities within datasets, we developed an overlap detection algorithm leveraging the simplicity bias in neural network learning.
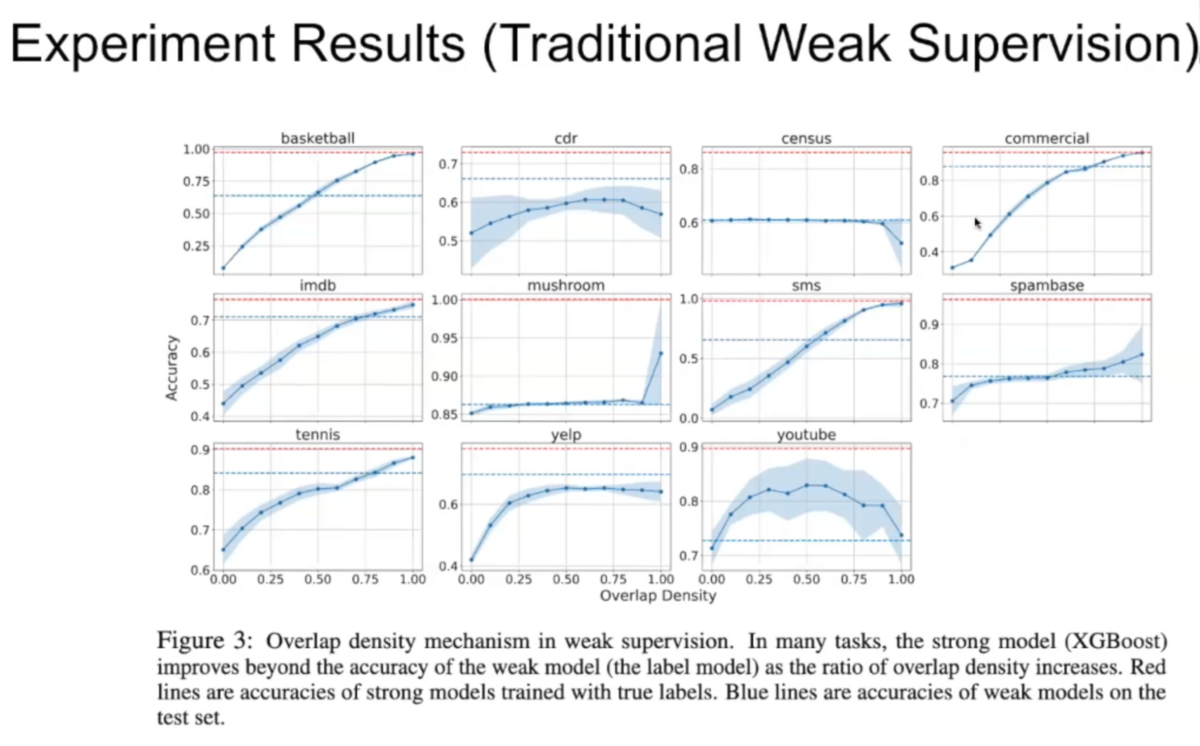
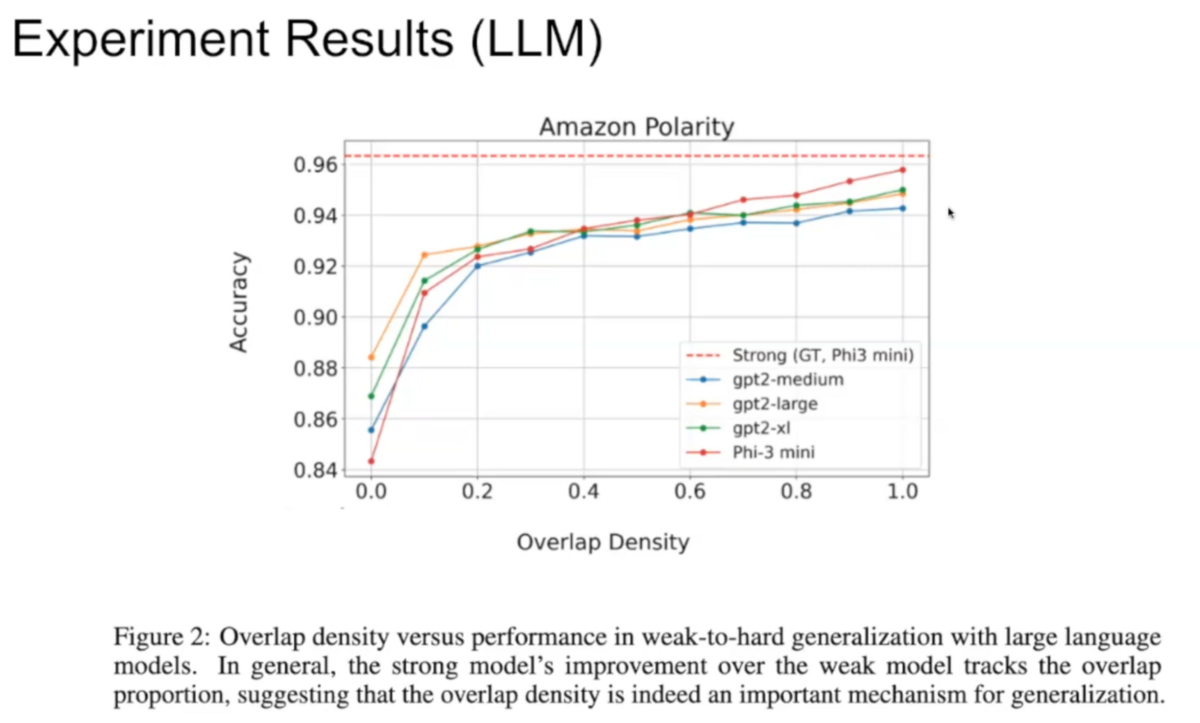
Expanding weak supervision to new frontiers
Addressing non-categorical problems through weak supervision, particularly in ranking scenarios, underscores the versatility and power of this approach. By transforming traditional label models and incorporating distance metrics, we can handle complex data structures and achieve superior model alignment. This universalization not only broadens the scope of weak supervision but also enhances its applicability in real-world AI alignment challenges.
Weak supervision also presents a powerful methodology for achieving effective language model alignment, especially in resource-constrained scenarios. By advancing label models and exploring the interplay between weak and strong model training, we have made significant strides toward safer and more aligned AI systems.
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!
Learn More

Changho Shin
Postdoctoral Scholar at Princeton University
Changho Shin is a postdoctoral scholar at Princeton University. He completed his PhD in Computer Science at University of Wisconsin-Madison, advised by Frederic Sala. His research centers on data-centric AI and foundation models. Changho’s focus is on developing efficient methods for creating and curating data for foundation models; he is the recipient of multiple awards for work in this area. Changho is a 2024 Qualcomm Innovation Fellowship Finalist.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

