New Snorkel benchmark leaderboards. See the results.
The Snorkel Enterprise AI Platform for Natural Language Processing
Reach production faster and unlock production NLP applications with the the Snorkel Enterprise AI Platform.
Trusted by
Google used Snorkel to replace 100K+ hand-annotated labels in critical ML pipelines for text classification.
Problem
Content, product, and event classification problems change too fast to hand-label, even with significant annotation budget.
Solution
Google deployed early versions of Snorkel's core technology with three high-impact teams, repurposing many resources as labeling functions.
Results
Hours of labeling function development replaced 10-100K+ hand labels, significantly impacting the bottom line and accelerating ML adoption.
6
months of hand-labeling data replaced in 30 min.
52%
performance improvement
100K+
hand labels replaced with a programmatic approach
Why Snorkel Enterprise AI Platform for NLP
Faster, lower-cost development
Use programmatic labeling to develop high-quality AI applications in hours instead of spending weeks or months on expensive hand-labeling.
Higher-accuracy models
Iterate on your application, using a closed-loop approach with intermediate results and analysis at every step to quickly identify errors and improve model accuracy.
Streamlined SME collaboration
Easily collaborate with experts and encode their knowledge into your model with labeling functions and intuitive manual annotation tools.
Keep data private and secure
Keep your data “eyes off” and maintain full ownership and control of your data throughout the model development process.
Flexible integrations
Easily integrate labeling, training, and analysis pipelines defined over diverse input types—text, PDF, HTML, and more—with downstream applications using APIs or a Python SDK.
Common NLP use cases
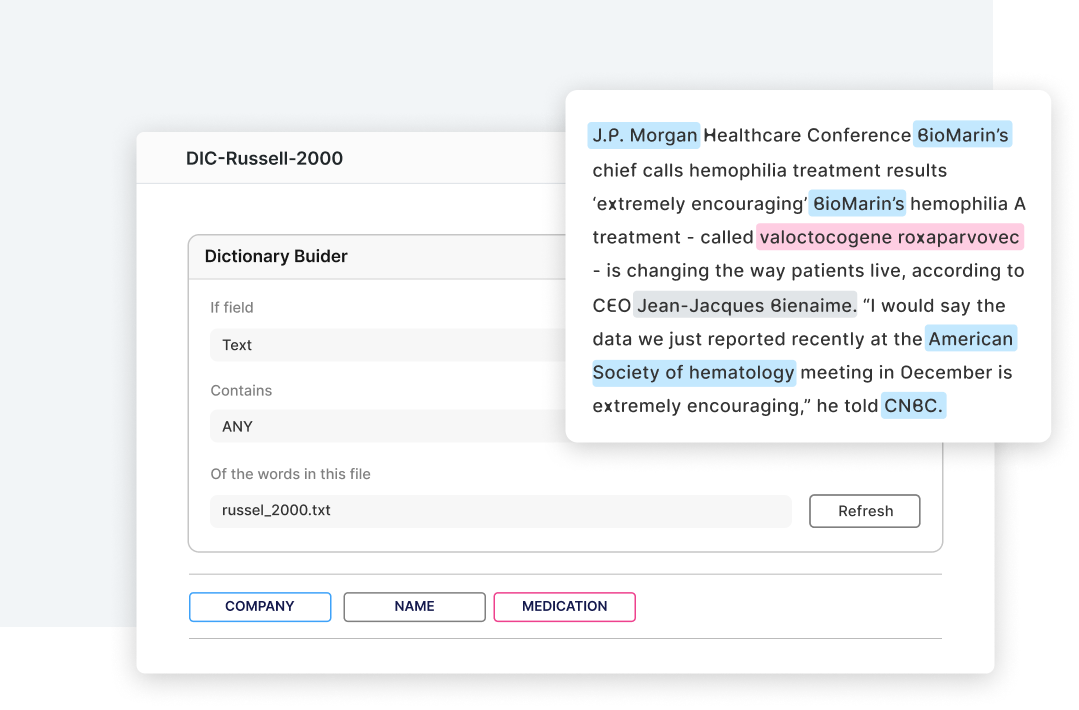
Document classification
Programmatically label training data across complex data types and build multi-model document classification applications with ease.
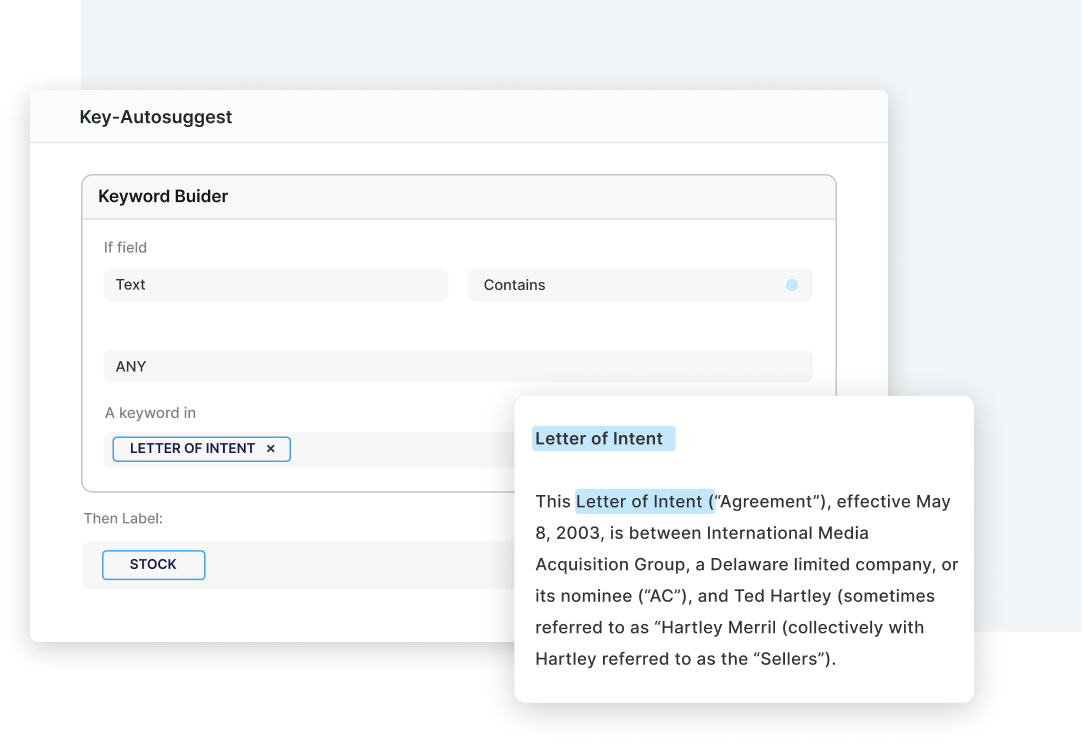
Named entity recognition
Build named entity recognition (NER) applications to recognize common or custom entities in a fraction of the time with programmatic labeling using the Snorkel Enterprise AI Platform.
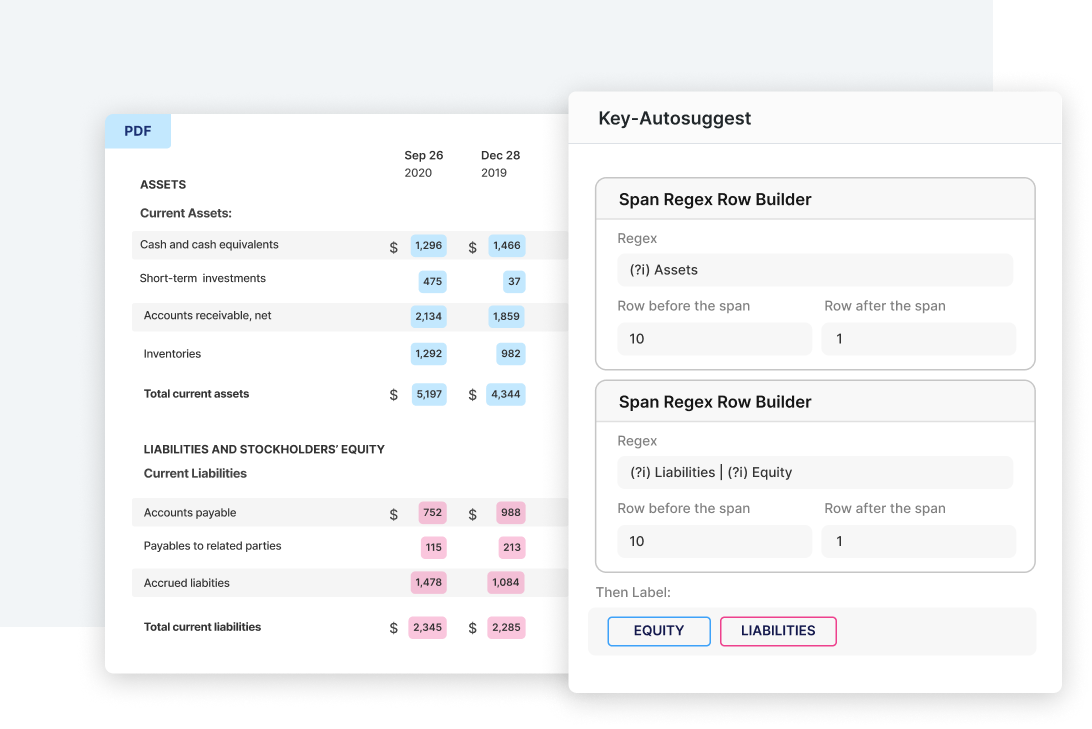
Information extraction
Rapidly build AI-powered applications that extract information from unstructured text, PDF, tables, or forms from millions of documents with programmatic labeling using the Snorkel Enterprise AI Platform.
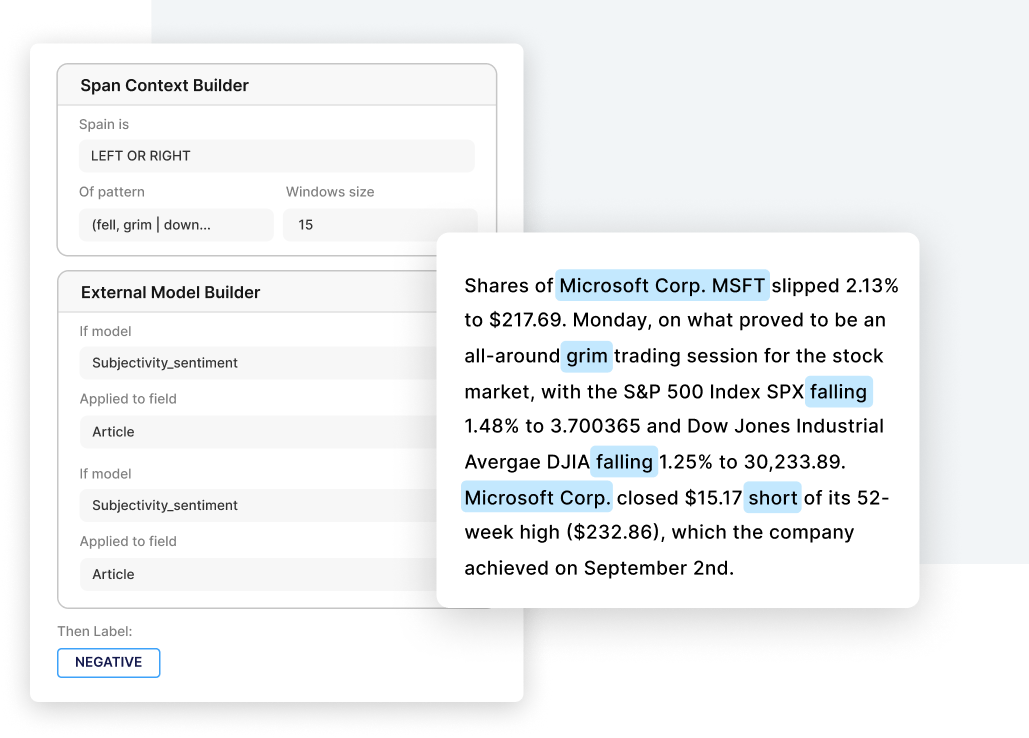
Sentiment analysis
Build AI-powered sentiment analysis applications to detect sentiments at the level of words, sentences, paragraphs, or documents in a fraction of the time using programmatic labeling with the Snorkel Enterprise AI Platform.
Ready to get started or have questions?
Talk to a Snorkel AI expert today to learn how you can accelerate the development of your NLP application and unlock new AI use cases powered by your data and expertise.
Snorkel Enterprise AI Platform
A complete platform for AI data development
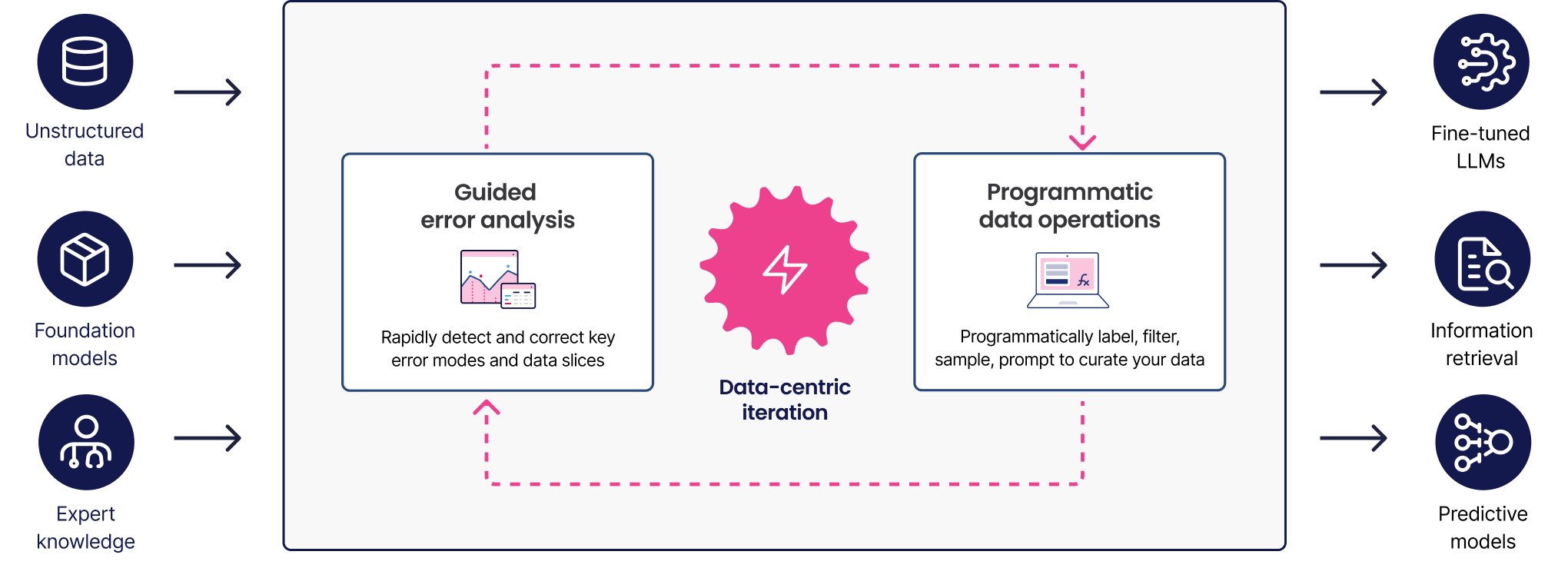
The Snorkel Enterprise AI Platform provides data scientists and subject matter experts with a collaborative platform for capturing domain knowledge, using it to label entire datasets or generate synthetic ones, and to quickly iterate on training data and model development via built-in, guided error analysis and model evaluation.

Join our next live demo
See the Snorkel Enterprise AI Platform up close and get your questions answered by a Snorkel AI ML engineer during our weekly live demos.