Introducing Open Benchmarks Grants, a $3M commitment to open benchmarks. Apply now
Scaling human preferences in AI: Snorkel’s programmatic approach
My colleagues and I at Snorkel AI recently worked with several large enterprises to help improve their generative AI applications. There are many axes where we can improve a language model, including RAG, data curation, or fine-tuning. At our recent Enterprise LLM Summit, I gave a talk entitled “Programmatically Scale Human Preferences and Alignment in GenAI” that focussed on how to align the output of large language models to enterprise users’ expectations. We do this through scalable techniques to magnify the impact of feedback from your internal experts.
Alignment follows supervised fine-tuning and further refines your large language model (LLM) responses to be more likable, adhering to certain workflows, or internal policies. This approach is shown in the last 2 phases of training ChatGPT—with reinforcement learning from human feedback (RLHF).
You can watch my entire talk below on Snorkel’s YouTube page, but I have also summarized my main points here.
User alignment techniques: two approaches
Our work explored two techniques for model alignment: RLHF and direct preference optimization (DPO).
Reward modeling centers on building a model to mimic how an expert would rate a response according to one or more factors. Data scientists supply users with a prompt-response pair. Then, they ask the user to rate that response. Then data scientists use these ratings to train the reward model, which predicts ratings for future responses. This can be interpreted as trying to approximate how the users would rate a given prompt-response pair.
RLHF would use these predicted ratings as feedback to nudge the LLM’s output toward simulated higher user expectations.
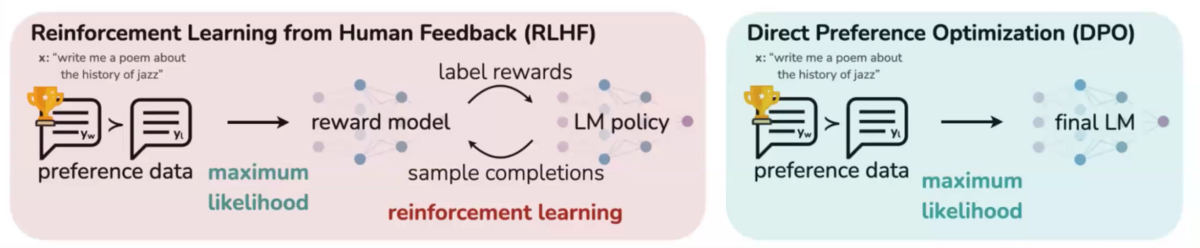
DPO operates differently. It optimizes directly on the preferences data—as now you have a pair of accepted and rejected responses. The training pipeline then encourages the LLM to decrease the likelihood of the rejected responses while making the accepted response more likely.
Reward modeling and DPO both require data that reflect human preferences. Gathering such data can be resource-intensive and time-consuming. This is where the challenge lies: how can we efficiently collect and utilize preference data to improve the alignment of our AI models? Our research sought to address this issue and find scalable solutions for enterprise settings.
Scaling human preferences programmatically
The team at Snorkel uses our Snorkel Flow AI data development platform to scale preferences programmatically. The platform leverages technologies like weak supervision to enable subject matter experts (SMEs) and data scientists to collaborate on labeling functions that express SME preferences at scale.
Using Snorkel Flow we built high-quality scoring models that successfully classified and quality-scored responses at high accuracy—and we did so quickly. Snorkel Flow allowed us to complete these models in as little as a day, bypassing the need for weeks or months of manual annotation.

Snorkel originally developed these tools to help enterprises build classification models. Our experiments have shown that they’re just as impactful—and perhaps more so—in fine-tuning generative AI (GenAI) models.
We can use this reward model to curate the data for DPO alignment. This is shown in our Alpaca Eval 2.0 result as we hold the 2nd place (only after gpt-4-turbo). You can read more about the approach on our model card or the diagrams below.
We also demonstrated the effectiveness of this approach when we built labeling functions to curate instruction-tuning data for Together AI’s RedPajama model. In the space of a couple of days, we curated 20,000 prompt/response pairs down to the best 10,000. In testing, users preferred the version of RedPajama we trained from that refined corpus over the original model in every category. We continue to apply the lessons we learned through that project with our recent cohort of enterprise GenAI projects.
Implementing a reward model to scale human preferences
Once we built a reward model, we integrated it into a DPO self-training pipeline. DPO proved to be the better option because it is more computationally friendly, but we believe we would have achieved similar results from other reinforcement learning approaches.
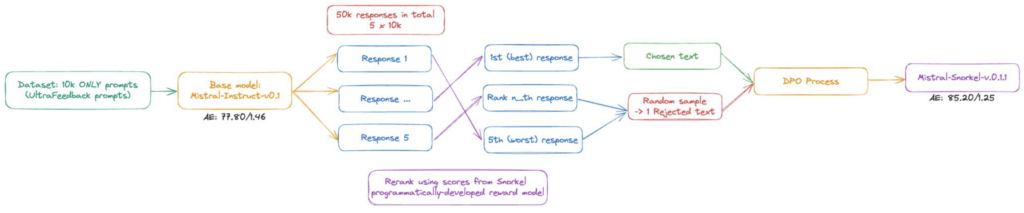
We started with a base model and 10,000 prompts For each prompt, we asked the base model to generate five responses. We then ranked these responses according to our reward model.
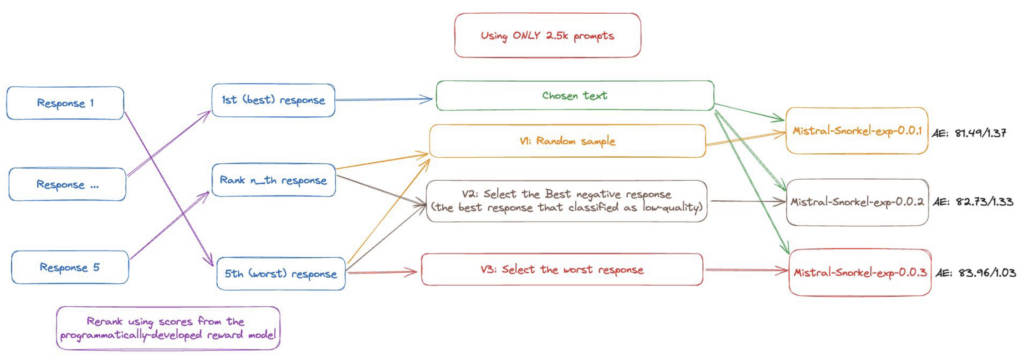
In the first version of our pipeline, we identified the top-ranked response as “chosen” and randomly rejected one of the remaining texts. A later version of our pipeline further improved model performance by instead rejecting the response ranked worst by our reward model.
Results
Using only 10,000 prompts, our team was able to achieve a 7.4-point (9.5%) increase on the Alpaca-Eval benchmark in under a day. It’s worth noting that we achieved these results without using responses from other language models.
The reward model we developed in Snorkel Flow also outperformed a leading open-source alternative. For the sake of comparison, we trained a second LLM using the Open Assistant reward model. That resulting model achieved a score of 83.31 on the Alpaca-Eval benchmark. Our model scored 85.2.
These results demonstrate the potential of this approach in enterprise settings, where customization and efficiency are paramount.
High-performance LLM applications demand scalable alignment
Enterprise data science teams need alignment beyond fine-tuning to optimize GenAI responses. This requires human preferences and SME involvement. Historically, the labeling process made it prohibitively expensive to involve SMEs in aligning model performance. However, Snorkel’s technology and a data-centric workflow make this process more scalable, trackable, and transferable.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Hoang Tran
Hoang Tran is a Senior Machine Learning Engineer at Snorkel AI, where he leverages his expertise to drive advancements in AI technologies. He also serves as a Lecturer at VietAI, sharing his knowledge and mentoring aspiring AI professionals. Previously, Hoang worked as an Artificial Intelligence Researcher at Fujitsu and co-founded Vizly, focusing on innovative AI solutions. He also contributed as a Machine Learning Engineer at Pictory.
Hoang holds a Bachelor's degree in Computer Science from Minerva University, providing a solid foundation for his contributions to the field of artificial intelligence and machine learning.
Connect with Hoang to discuss AI research, machine learning projects, or opportunities in education and technology.