
Jimmy Lin is an NLP product lead at SambaNova Systems. He presented “A Practical Approach to Delivering Enterprise Value with Foundation Models” at Snorkel AI’s 2023 Foundation Model Virtual Summit. A transcript of his talk follows. It has been lightly edited for reading clarity.

I lead the NLP product line at SambaNova, and prior to that, I held engineering and product roles across the full AI stack—from chip design to software to deep learning model development and deployment. Me and my team are mainly responsible for the models as well as developing the recipes to train and use them. Those then get integrated into our platform. What our customer gets is a much more simplified, abstracted, and repeatable experience. We thrive on delivering state-of-the-art results out of the box with additional flexibility for our customers to customize it in a way that they need it. So in this talk, I’d like to share with you what we find as a practical approach to deliver enterprise value with foundation models.
A little bit of background on who we are and what we do: SambaNova was founded in November 2017 by Rodrigo Liang, our CEO and former senior VP of Oracle managing all processors and AC development, Kunle Olukotun, a professor at Stanford University in electrical engineering and computer science (also known as the father of multiprocessors), and Chris Ré, also a professor at Stanford in computer science. Chris is a MacArthur “genius grant” recipient and also a co-founder of Snorkel AI.
Since our inception it has been an exciting ride, to say the least, for everyone who has been involved in a short five-year span. We have expanded from our Palo Alto headquarters to a global presence with offices in AMEA and AsiaPac. We now have more than 500 employees and counting and have raised $1.1B in capital to this date. All that has enabled us to keep our foot on the gas pedal.
At SambaNova Systems, we focus on AI innovation using foundation models to increase and drive customer value. We deliver fully integrated AI platforms (that includes the silicon, the compiler, the software stack), to pre-trained models and APIs that can be deployed at any data center of your choice.
With foundation models, we’re at the cusp of yet another paradigm shift in AI and machine learning. It’s important to contextualize the significance because more profoundly than before, the shift is yet again going to change how AI systems are going to be built going forward.
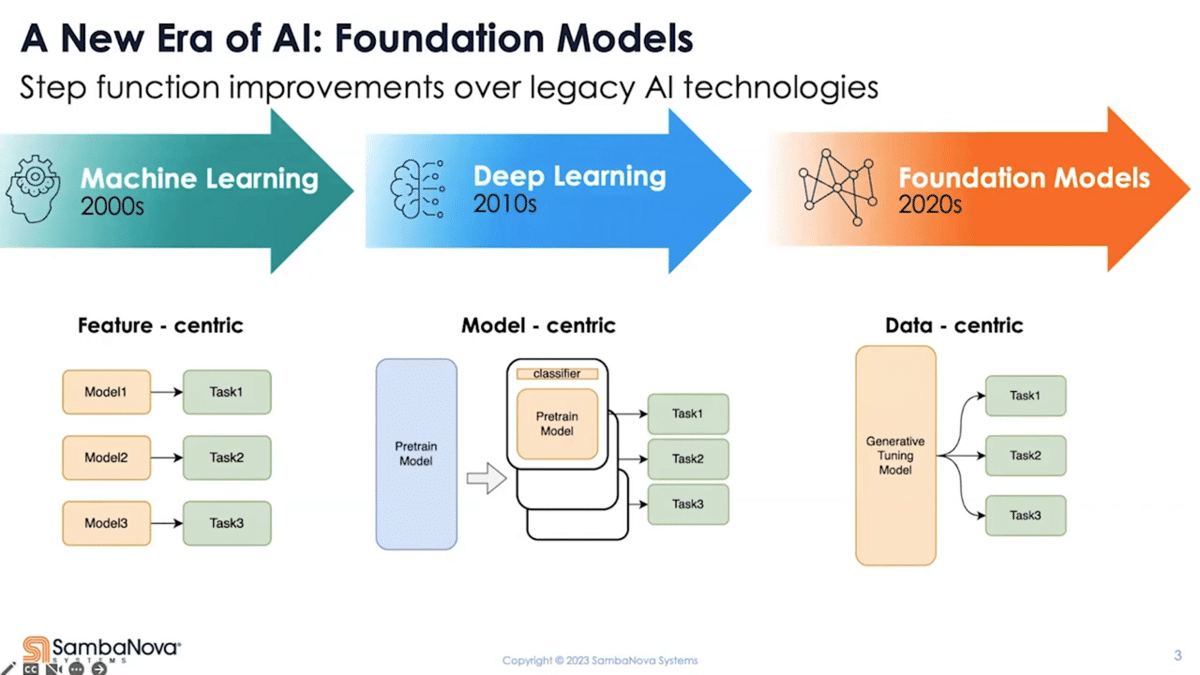
If we look back at the traditional machine learning era, starting in 2000, the focus then was to solve largely analytical problems using machine learning. The data used was entirely structured, and there’s significant upfront effort required to design and engineer the features in order for you to make it do what you want it to do. What gets deployed are small models that excel in analytical tasks, very feature-engineering heavy, and one model for every task.
Now, roughly a decade later, the first shift had happened. Deep learning became the new focus, first led by the advance in computer vision, then followed by natural language processing. As part of that, the core problem people were trying to solve shifted from dealing with structured data to largely unstructured data. It was no longer about understanding how to interpret or make use of the different columns in the tabular data, but more about making sense out of a given set of pixels or a paragraph of text.

With these different problems came a different approach. People started to build different model architectures to address different problems, which marks the start of the model-centric era. Now, later on, transfer learning further revolutionized deep learning. When it comes to deployment, though, it still largely resulted in one model for every task—similar to the first era.
For example, if I have two classification tasks that I want to apply on the same data, if the classes are different, I need to train two different models—not to mention label the data in two different ways. You can see the deficiencies there. It also takes a lot of time and effort to train these models. Each problem is very specific, hence the need for a lot of models. The barrier to adoption is also higher compared to the previous era. You’ll need deep technical expertise to decide what model is best suited for which problem.
So why are we so excited about the shift to foundation models for this new data-centric era? One, they’re flexible enough to take on both structured and unstructured data. In other words, you present the potential to replace the functions from the previous two eras. Due to the innate ability to understand language (that’s the second point), people can now interact with these models using natural language directly. So, the barrier of entry essentially is dissolved. You no longer need to build features or change the model to make it perform a certain task. Anything that you can frame as a question or as an instruction becomes something you can ask the model to do. That means that non-technical users are also enabled and literally anyone can start exploiting this technology. The focus has also shifted to the data.
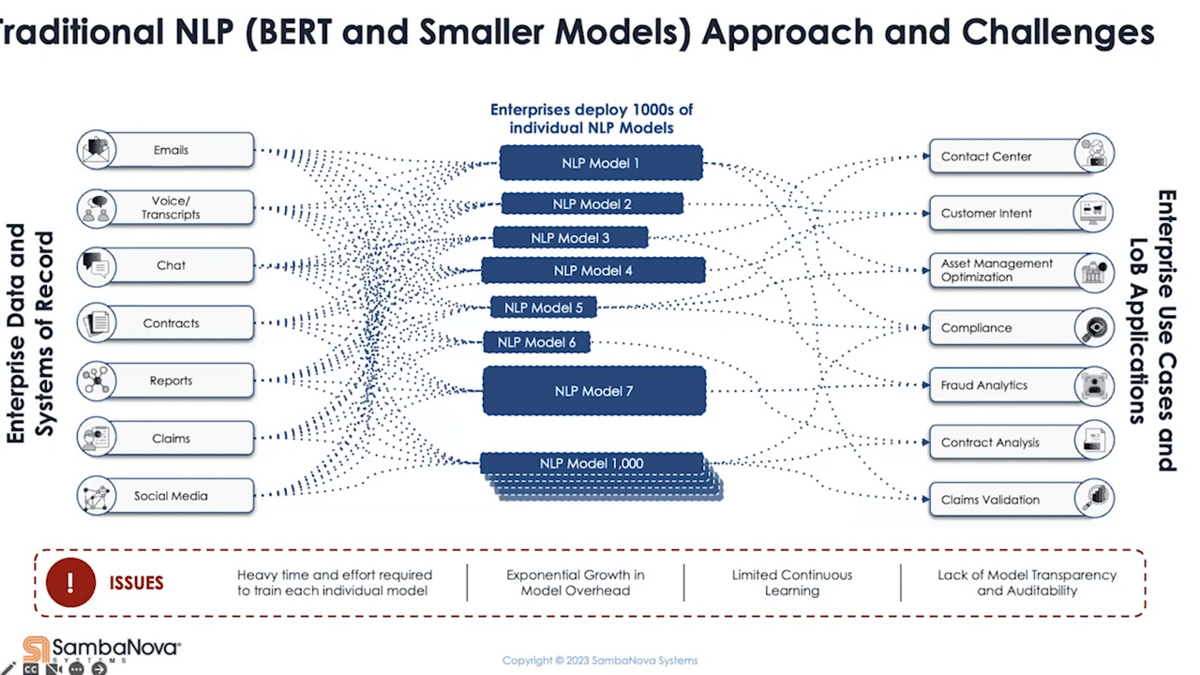
This presents, not just from the technology perspective, a fundamental shift on how enterprises are deploying and using AI. If we take a look at how enterprises are deploying AI today, they have literally thousands of models. Why? Number one, every use case has its own unique requirement and nuances. Reason number two is due to all the limitations that we talked about from the previous era—each model is built to accomplish a specific task. We can imagine all the implications and issues this presents, from not only engineering complexity perspective but also the overhead associated with maintaining and upkeeping everything.
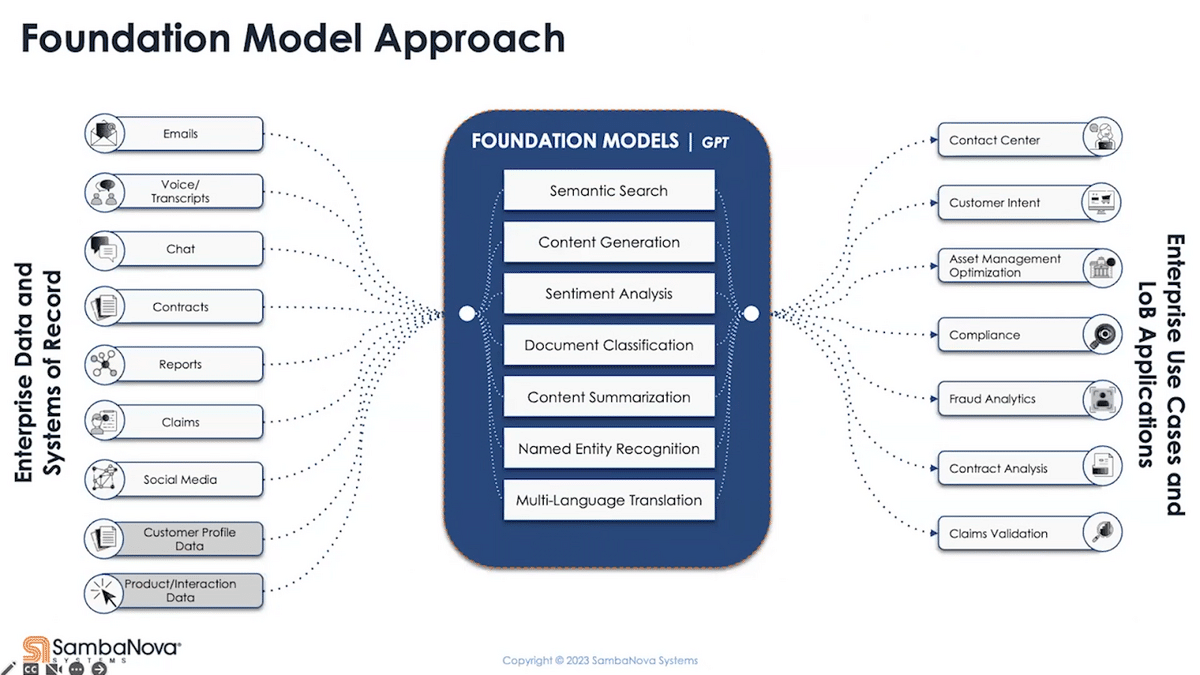
What a foundation model enables us to do is to take all that and solve much, if not all of it, with a single model. If the previous picture is what your organization is facing today, this means a chance to consolidate and modernize your approach—doing more with less, allowing you to break the limitation you face today and scale with even more advanced capability. If you’re new to AI, foundation models provide you with a more modern approach to get to value quicker.

In reality, the model is just the starting point. There’s more work you have to do to turn that into enterprise value. I want to focus on the three things that we focus on and some of the key implications to get to enterprise value.
Number one, training is important—or further training to be exact. This hopefully shouldn’t come as a surprise to most people. We don’t just live on a foundation, for example. We build structure on it, and the name “foundation model” implies the same semantics. They don’t necessarily equate to an end solution right away. Further training them is a step for you to get there, and I’ll give some examples of what we mean by that in the very next section.
The second thing is integration with technical workflow matters. You’ve got to meet the workflow where it’s at today. You need flexibility in deployment because the reality is, enterprises are hybrid. You need flexibility to meet the very different needs between training and inference. You also need the flexibility to adjust the behavior of the model, to avoid introducing any integration overhead with the downstream system.
Ultimately, to really get value, you’ve got to think beyond just the model of the technology. You’ve got to start with the business process and the business pain points. You need to break it down into each individual pain point that’s being experienced—really understand that from a business perspective—and work backwards.
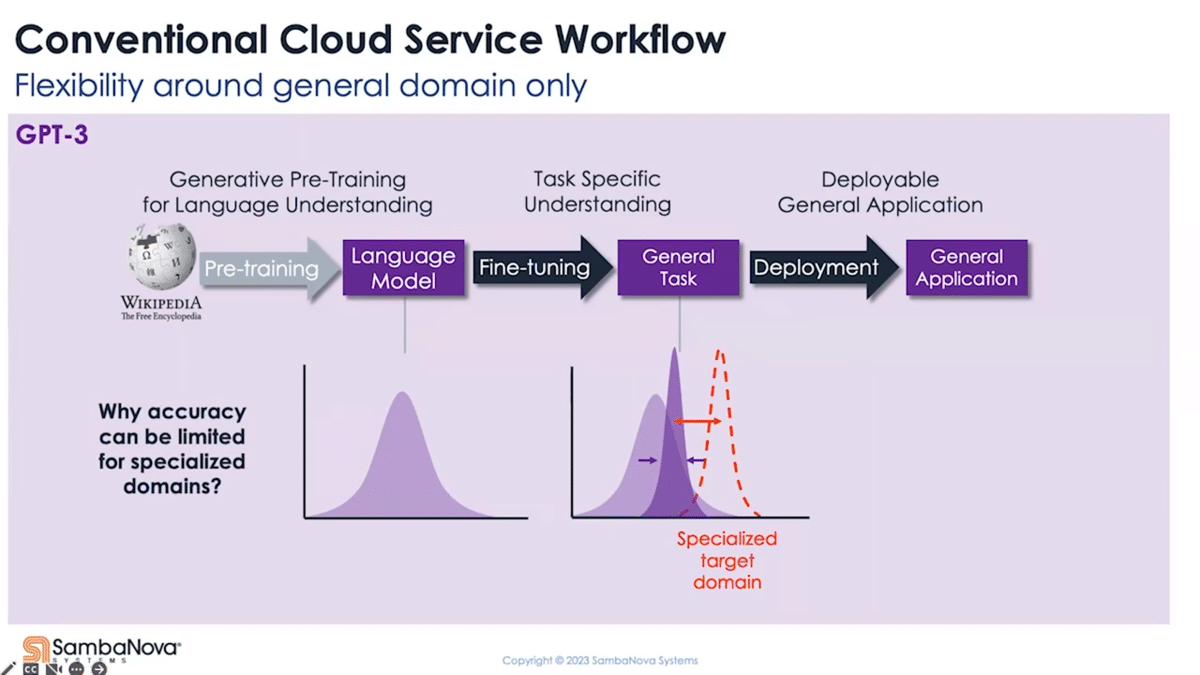
Starting with the pain point of training, perhaps the most accessible way today for you to try playing with the foundation model is to go to one of the cloud service providers’ playgrounds. What you find there is that they mostly provide a two-stage pipeline offering fine-tuning and deployment. As the starting point, you can pick a variant of the pre-trained model they offer and start exploring what it can do right off the bat. Additionally, you have the option to fine-tune it using your own data and then deploy the fine-tuned model.
Why do we say more training is critical? Pre-training is a step that develops the model’s natural language modeling capability. This is a step typically pre-built by the service provider and not available to the user. While a pre-trained foundation model at this stage has a general understanding of the language, the chances are it’s not as good as you want when it comes to following what you ask it to do. Instead of performing the task the way you expect, it could do something else like paraphrasing your questions or ask you a question back. This is a general observation, by the way, that applies to almost all pre-train models. In context learning or few-shots, you can (to a certain degree) reshape how these models behave, but these are inference-only approaches and we found it more suitable for exploration or exploitation phases of your product development.
Fine-tuning is a way to bake that into the model and make it more repeatable and consistent—whether it is to make it follow instructions, like a virtual assistant, to be more factually oriented, or to simply perform a certain task in a very specific way. The fine-tuning part is open to most users and this allows the model to adapt to downstream tasks in the generic language domain. If the problem we’re trying to solve is more domain-specific (and this really depends on how much your target domain overlaps with the general domain that the model’s being trained on), there’s still a significant gap in terms of the quality of results.
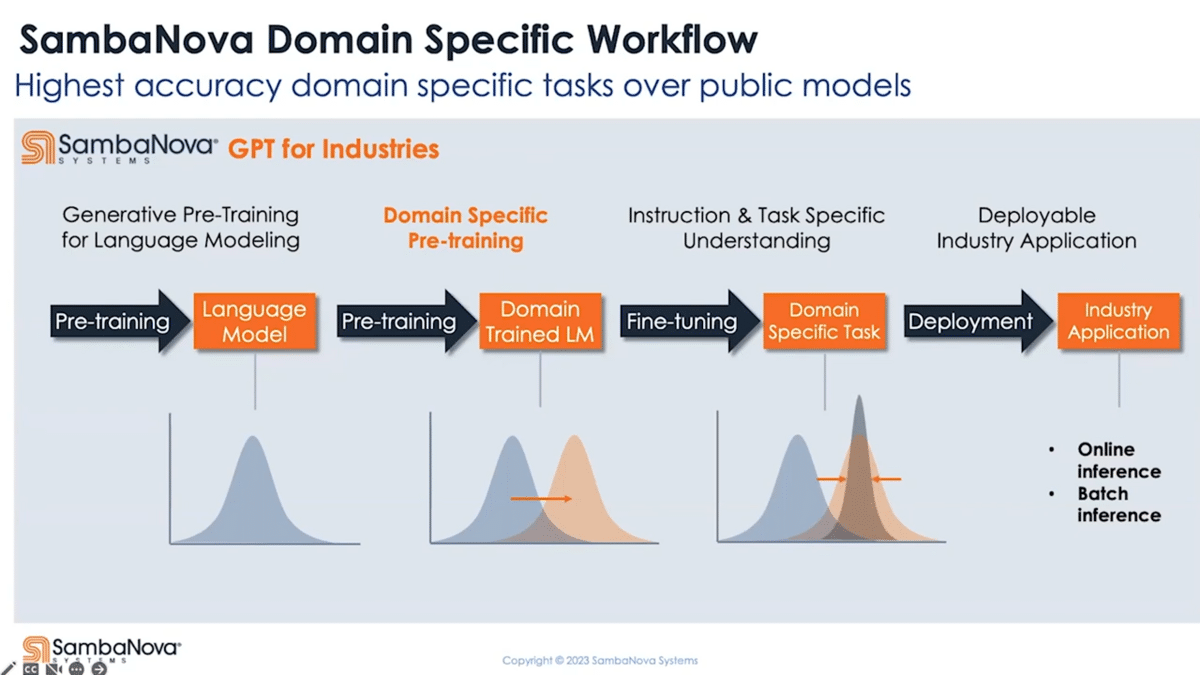
The SambaNova platform offers not just a three, but a four-stage pipeline. We expose the full pre-training capability for those who want to create their own foundation model from scratch. More generally, you can take our pre-trained model and further pre-train it using your domain-specific data as a second pre-training stage. This allows the model to adapt to be domain-specialized.
For example, it could adapt to different definitions of the shared vocabulary between the general domain and the specific domain. This could literally bring different meanings to the sentence. There are also ways for you to effectively increase the vocabulary of the model to allow it to learn more special terminologies or acronyms that carry unique meanings, and where the words themselves can also be unique to your organization or your product.
What you end up with is a pre-trained model that not only understands language at the end of the second stage but also specializes in your target domain. When you fine-tune on that, whether it’s for instruction following or task adaptation or task targeting, it gives you much better coverage for your target, resulting in the best possible accuracy or quality of results. You can do all this on the same platform, which can be deployed to any data center of your choice.
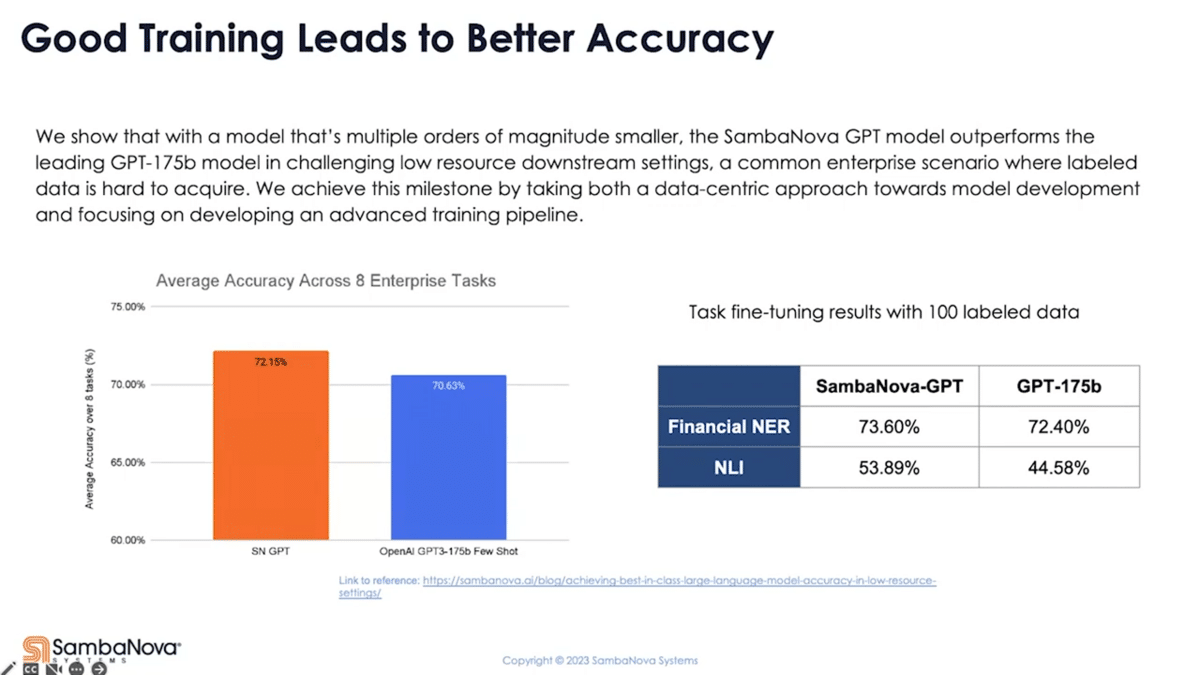
A lot of times, we hear “generative AI”, we see foundation models, we wonder how different they are. They’re all different in a certain way. In fact, we see a significant impact on downstream task accuracy from how the model is being trained. Here, we have some data points showing that we are able to achieve higher accuracy just by training them out differently using a data-centric approach.
With a model that’s more than 100x smaller, our own pre-trained GPT, when given a very low amount of resource label data (which is the typical starting point for enterprise), can deliver an accuracy advantage over a few-shot results from OpenAI’s 175-billion model. When we fine-tune both models on a couple customer tasks (in this case, 100 labeled data for each task) we also deliver an accuracy advantage. Even though there’s more work needed to further improve the accuracy (and there are many ways you can do that), with a different model you can get a better return of your investment for the fixed amount of data you have to start with. From that point on, you can get to value sooner.
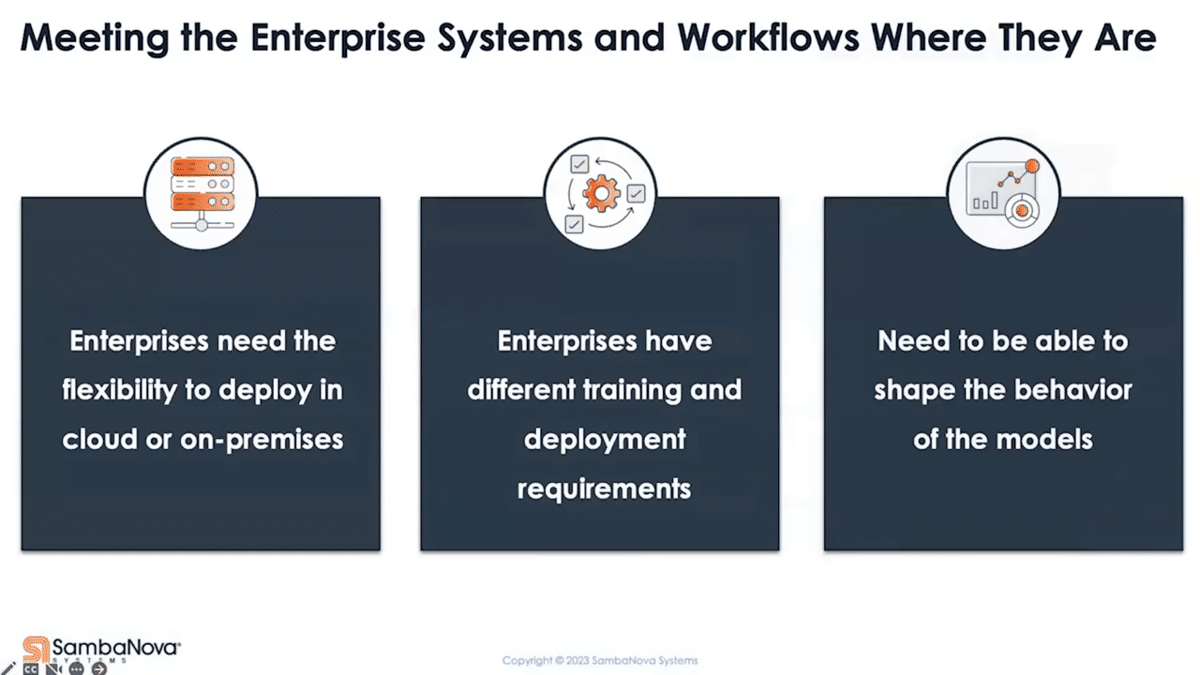
Training is critical, but it doesn’t end there. The reality is that at some point, you need to connect to the systems. There are a couple of things here. You’ve got to be able to deploy them where your customer wants. In reality, enterprises are hybrids in many cases, especially regulated industries. Your data needs to remain behind a closed network and cannot be sent to the internet.
Training and deploying a model also have very different needs. It’s not just the computer requirement, although that’s a huge part of it. There’s also infrastructure and tooling you need around it. Training a tens- or hundreds-billion parameter model, using close to a terabyte worth of data, pretty much requires a dedicated supercomputer scale cluster for weeks or months. On inference time, you want to deploy these at high scale and hopefully not on a supercomputer due to obvious cost reasons. You also need the flexibility for efficiency’s purpose, to deploy more or less depending on the traffic.
Thirdly, you’ve got to be able to shape the behavior of the model. Not all downstream systems can handle natural language as input. Many expect numeric values instead. This comes back to fine-tuning, where you can quickly adjust the behavior of the model to connect to what the downstream systems are expecting.
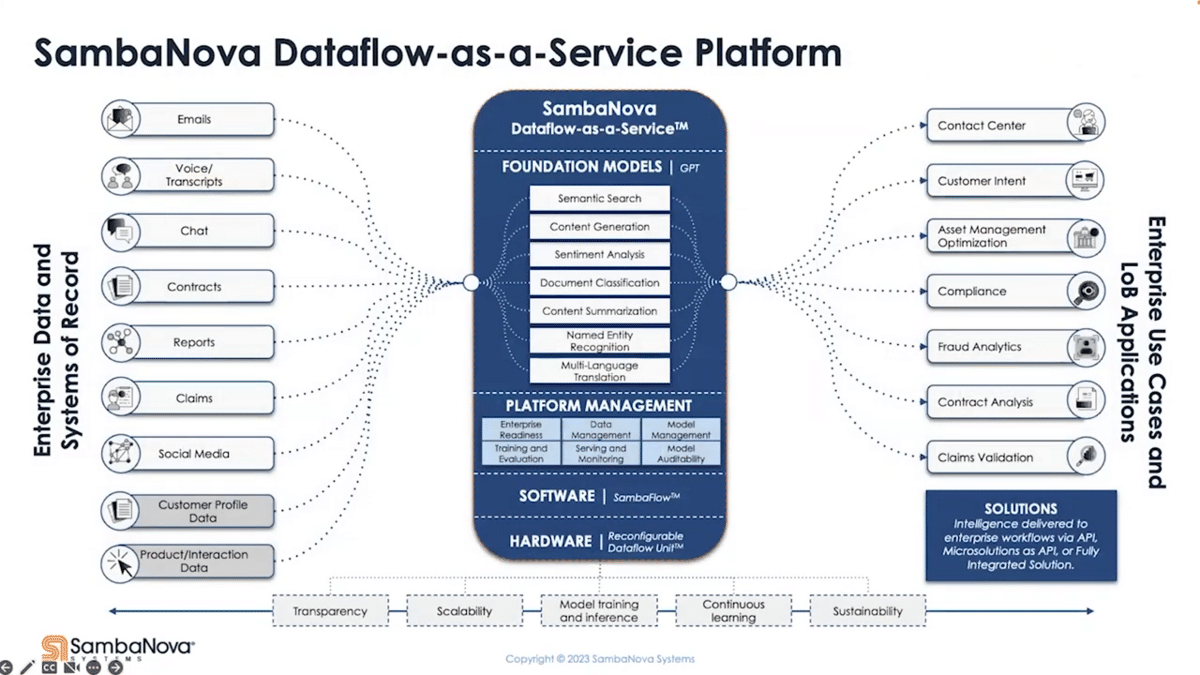
In order to meet these requirements, we don’t offer just a black box API. We provide you with the hardware, software, platform management, all with foundation models. The stack can go in your on-premise data center, your colo, sitting behind your firewalls, meeting your security protocols. If you’re a startup who only runs on cloud, we can meet you there as well.
Our architecture is reconfigurable, so this platform can be used for training and inference, both efficiently. This enables you to streamline the process to do continuous learning to keep the model up to date. Using the more flexible four-stage model pipeline development that I touched on earlier, you can easily shape the behavior of the model so that it can be easily integrated with the downstream system and workflow.
Whether it is your contact center application or asset management optimization platform, whatever the need is to take in the data a certain way or expect the output of the model in a certain way, you can manage all that on a single platform, really reducing the overhead. All that chaos, we brought it all together onto a single platform where you can manage everything.
I want to talk about use cases. Even though we deploy everything in a simplified fashion, it doesn’t really start with the technology. It starts with the business application and the business values. In order to define that, it starts with understanding the pain points, then going and finding where those technologies can help, not the other way around.
As an illustrated example, a typical contact center workflow begins with a customer calling in. After a couple pauses and attempts to get to the right agent, that’s when they get to have a conversation with the agent to get help. The agents have to actively manage the conversation to make sure that the issue the customer is calling about and the sentiment is taken care of. We all expect notes to be taken, but experience told us otherwise—we all found ourselves having to call back and repeat the whole journey as if the first conversation never took place. And lastly, post-call surveys are filled out by a very small percentage of customers. Only people who have a terrible experience typically leave surveys. So despite a customer calling and telling you their problems, what seems to be the best opportunity to learn about the customer, we actually are not getting any valuable insights with this existing business workflow.
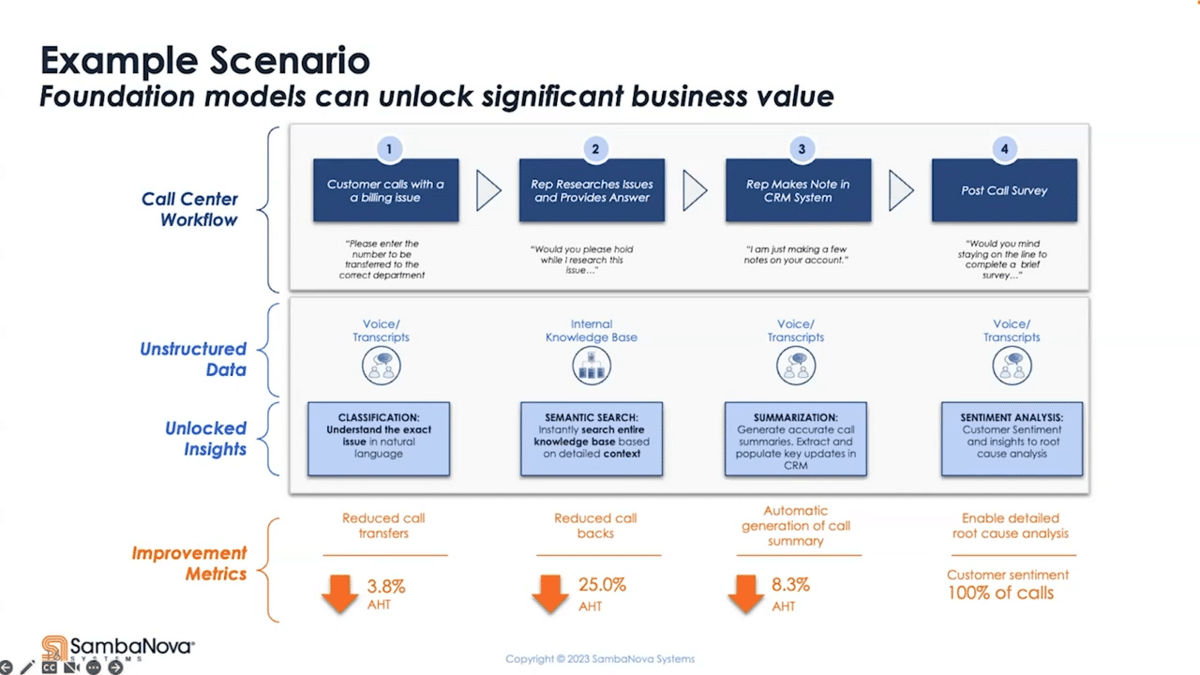
What if we can look through the voice transcript? We can understand the exact problem they’re calling with and get them connected to the right rep every single time. What’s the implication of this? It reduced average call handling time by 3.8%.
Now, we have a more complex challenge. Instead of the rep having to say, “Hey, can I put you on hold while I research for the solution,” what if we could use semantic search to go look through the entire knowledge base using natural language questions and get the answer instantaneously? How can the metric improve then? We can reduce the call time even more by 25%, just by simply implementing a basic function.
If we go on with this call, what if instead of making the rep put in the notes they don’t want to do (because they want to get to the next call as soon as possible,) what if we can automatically summarize this call with all the relevant information not only for this call but also for cross-sell and upsell and retention later on? That will not only get us more information but also reduce the call time even further.
Finally, what if we can get accurate and relevant information on how we did, not just getting the 5% of the unhappy customer, but 100% percent happy and unhappy—and, by the way, records on how we actually solved the problem they’re calling about? What would that be worth?
If we’re trying to start with the model or with the technology and then look to apply that somewhere, it’s harder to be successful. Instead, start with the business process map, identifying the pain points and then going back to where and how these technologies should be applied.

In summary, there are three practical implications to using the foundation models to get to enterprise value. Training matters, whether it’s fine-tuning or doing more pre-training. Integration with technical workflow matters—you’ve got to meet the system where they’re at. And number three, you’ve got to start with the business value—don’t start with the technology and try to find the problem, you’ve got to do the other way around.
This is a practical approach that we are taking to help our customer to get to value sooner. With the new generative capability of the model, the sky is really the limit. Looking ahead, we expect to see increased interest, especially from startups, to build on top of perhaps a small number of leading foundation models. Through further training and fine-tuning, we expect to see highly differentiated domains or use case-specific models to show up.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

