Amy Hodler, senior director of graph evangelism and product marketing at RelationalAI gave a presentation entitled “Reclaim Predictive Data with Knowledge Graphs” at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. The following is a transcript of her presentation, edited lightly for readability.
Thank you for the wonderful introduction and for joining us to talk a little bit about reclaiming predictive data with knowledge graphs. My name is Amy Hodler Anything science apps work at RelationalAI, cloud-native, Relational Knowledge Graph. We are just recently out of stealth mode and also just recently won a Gartner Cool Vendor award, so a lot of exciting stuff going on there.

I want to start with something that I suspect most of you have said–and it’s certainly something most everyone has heard, and it is: you actually have more data than you realize. You have more predictive data than you realize. It is just the ability to get at that and use it that’s missing.
So if we think about how we build better models, we all pretty much know how to build a better model. You either improve your data or you encode some kind of expertise or knowledge into the system that you’re creating. And if you’re looking at data, that is squarely in data-centric AI you’re looking at improving the quality, having higher quality data, more accurate, or just more—if it’s good data—as well.
But to encode knowledge, that’s something we actually already do a lot of. When you think about data cleansing and data sampling—if you’re telling a system what is going to be predictive or what it should be learning on, you are encoding some kind of knowledge that you have. And then there are more advanced types as well.
So if we’re looking at feature engineering or weak supervision those are methods that in a more advanced way, we’re also encoding knowledge in some fashion. So lots of different ways that we can improve data and encode knowledge. And unfortunately, the first thing we do when we start building a predictive model is to steamroll our poor raw data.

So basically, the first step we do when we’re looking at creating features is we flatten our structures. And if you think about all of your organizational information, how things are related? What are the dependencies? What’s the importance of this item? What’s the structure of how things are dependent upon each other?

That’s valuable information that a business expert would know, and we cram that down into a feature matrix and lose a lot of that information. And we do that because we have to; machine learning systems don’t handle highly dimensional and very complex data very well. So we have to do it, but we’re losing good data right out of the gate.
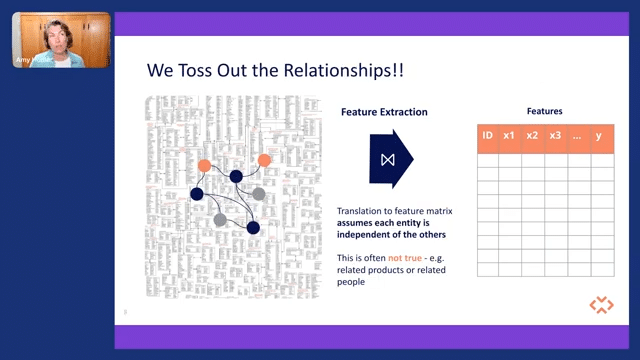
And we also happen to toss out relationships. And when we create a feature matrix, we assume entities are independent of each other, and in the real world, there isn’t much that is independent of each other. Things are very related. If you think about predicting, let’s say, what kind of bicycle components or bicycle services somebody may want, that’s highly related to what kind of bike frame they bought. It’s highly related to whether they’re a high-end consumer, and the different services they may want are very related items. And so throwing out that type of information kind of degrades what we can do.
And you might say, “Hey, Amy, that’s just a little bit of information, it’s not the important part, it’s not the frame.” But it is important. So in machine learning, we’re trying to build a model, and have that model learn from the real world. And if we create stripped-down models of the real world, very shallow models, we are stripping away this knowledge and we can’t take it as far as we might have otherwise.

So the first thing to do is don’t waste data that can improve the quality. So corporate data, there is a lot of it out there, but the structure of it we’re not really leveraging. We’re not capturing business logic and we need to do that in our models. We need to look at other technologies or other areas like image and text and be able to connect them relationally and leverage the data and relationships themselves.
So the other thing we want to do is, if we are encoding knowledge in any fashion, let’s not waste it. So you’re hearing a lot of talk recently about semantic models and semantic layers, kind of an old term that has a new twist now. People are looking at “how do I map data to the business meaning and the importance of it?”
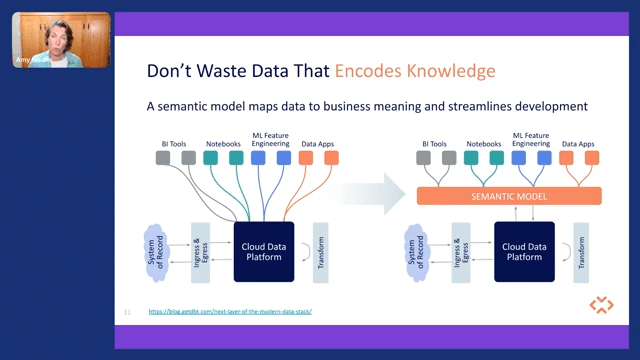
And they’re looking at that as a way to help us streamline the development of things like data apps. So how do we gather that intelligence and gather that logic in a way that we can make our data apps more intelligent and do it in a way that we can streamline some of the pipelining that would normally go on?
And if you happen to be capturing this kind of information—and I hope you are—how do you then use it in a machine-learning context? You can use a knowledge graph to feed that kind of predictive data and that knowledge into a platform like Snorkel. So a relational knowledge graph very simply models business concepts with the relationships and their associated logic in kind of an executable way.
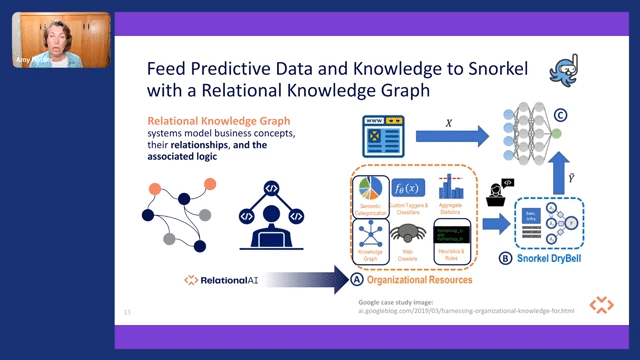
A quick example here of how that can be used: here’s a graphic from a Google case study using a Snorkel DryBell solution. And they were using a knowledge graph as organizational information and organizational resources. But if you add in a relational knowledge graph, you can not only grab those relationships and the dependencies, but because of the logic, you can also add in heuristics, business rules, business logic, as well as semantic information.
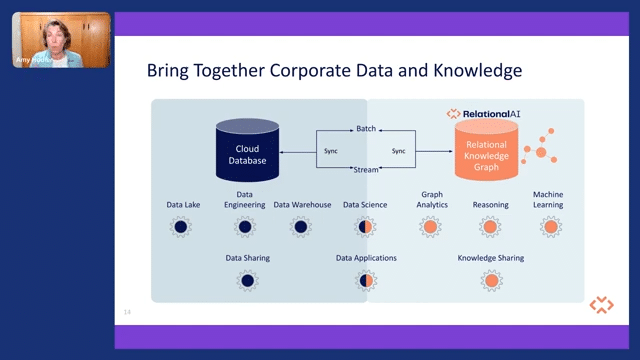
So what we’re trying to do with relational AI is to be a pairing to the modern data stack so that you can bring together all of that rich corporate data that you have with the knowledge you have as well. Bring that together, drive more intelligence into data apps, streamline that development, but also support more complex workloads that don’t traditionally do well in a relational database, like graph analytics, reasoning, and optimization workloads.
So if that sounds interesting to you, please reach out, say hello. I’d love to talk about this topic. And if you’re interested in a relational knowledge graph, go to relational.ai. And you can sign up for early notifications and early access to the product. So thank you all for your attention. And please feel free to say hello.
Catch the sessions you missed!
The Future of Data-Centric AI 2023, our two-day free virtual conference, brought together thousands of data scientists, AI/ML practitioners, researchers, and the AI community at large to hear about and discuss the latest trends and research in data-centric AI. If you registered for the event but didn't see all the sessions you wanted, you can now catch up. The recorded sessions are available for registrants at the same Zoom portal as the live sessions.

Recommended articles
View all articles

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•

The Art and Science of Building AI Benchmarks That Shape the Field
Vincent Sunn Chen spoke at AI Engineer London about what it actually takes to build AI benchmarks that move the field forward, not just measure it. The throughline is an asymmetry that keeps showing up across deployments and the 150+ proposals reviewed for the Open Benchmarks Grants: agent capabilities are climbing fast, but the ability to measure those agents with
June 16, 2026
•
Snorkel Team

Cua-Bench: benchmarking computer-use agents on professional software
TL;DR We built a benchmark of 25 expert-authored KiCad schematic-editing tasks and ran a frontier computer-use agent against them. The headline numbers: 1. Why build a computer-use benchmark for electrical engineering? Most computer-use benchmarks today live in the same handful of apps: web browsers, file managers, generic productivity suites. Those evaluations are useful, but they share a structural weakness —
June 15, 2026
•
,

