Impact
93%
Accuracy with just a few labeling functions
1000s
Of patient records auto-labeled
Weeks
Instead of months to build a document classification
MSKCC, the world’s oldest and largest cancer center, sought to identify patients as candidates for clinical trial studies by classifying the presence of a relevant protein, HER-2. Reviewing patient records for HER-2 is onerous; clinicians and researchers must parse through complex, variable patient data. By unblocking training data labeling and data-centric iteration, MSKCC was able to build a model with overall accuracy of 93%. This powers an AI-driven screening system to classify patient records at scale, speeding recruitment for clinical trials, and as a result, treatment research and development.
The challenge
The challenge
To unlock improvements to clinical trial screening, the data science team at MSKCC wanted to use AI/ML to classify patient records based on the presence of HER-2, a protein common to many cancers. However, lack of labeled training data bottlenecked their progress. Labeling data (in this case complex patient records) requires clinician and researcher expertise and is prohibitively slow and expensive.
Further, even when experts were able to manually annotate training data, their labels were at times inconsistent, limiting model performance potential.
-
- Time to label training data was prohibitively slow given the high degree of domain expertise required and inability to outsource.
-
- Limited model quality as information was inconsistently referenced within the complex unstructured text of patient records.
-
- Disagreement in expert labels wasn’t discoverable because there were no practical ways to govern labels.

The goal
The goal
Reduce data labeling and development time by making more efficient use of domain experts’ effort—without reducing data or AI application quality.
The solution
The solution
MSKCC’s data science team worked with Snorkel’s experts, who used our proprietary technology to help build an AI application to classify patient records across five classes, categorizing the presence of HER-2. This application now supports a downstream clinical trial screening system to identify potential participants.
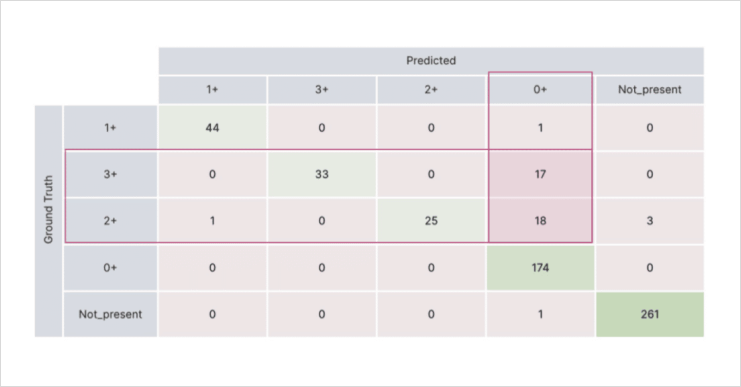
To objectively measure the solution, the team used 3,200 data points they had labeled prior to working with Snorkel.
The lead bioinformatics engineer on the project collaborated with Snorkel’s experts to create eight imperfect labeling functions. Our proprietary technology combined these functions to project likely labels onto raw data. The team then used these likely labels to train an XGBoost model.
Using the limited ground truth data as verification, the team iteratively refined labeling functions using our proprietary model-guided error analysis tools.
For example, the model misclassified some HER-2 positive records (2+ and 3+) as negative when the text contained the word “negative.” To fix this, the engineer wrote a labeling function that only considered “negative” when it appeared near the keyword “HER-2.” Retraining the model resolved this error.
Notably, analysis revealed that many ground-truth labels—hand-labeled by domain experts—were incorrect. Correcting these labels removed a hidden constraint on model performance.
With just a few rapid iterations, the team achieved an overall accuracy of 93% and an average F1 of 87% across all classes. The test set results were nearly as strong, with 92% accuracy and 87% F1.
-
- Programmatic labeling significantly reduced the time required to create high-quality training data for complex, domain-specific text.
-
- Model-guided error analysis identified data quality issues, including incorrect ground-truth labels, enabling rapid iteration.
-
- Labeling functions encoded the rationale behind each label, improving explainability and maintainability.
The resulting document classification AI application now powers a clinical trial screening system that allows MSKCC to identify HER-2 in patient records without requiring human experts to manually review each one.

“The biggest challenge we have—which is true of any AI/ML project, but is especially so in clinical contexts—is how do we label [training] data? Our labelers are physicians and researchers, their time is very expensive.”
Subratta Chatterjee
Principal Data Scientist, MSKCC
Scaling clinical trial screening with document classification
MSKCC, the world’s oldest and largest cancer center, sought to identify patients as candidates for clinical trial studies by classifying the presence of a relevant protein, HER-2. Reviewing patient records for HER-2 is onerous; clinicians and researchers must parse through complex, variable patient data. Snorkel’s experts, using our proprietary technology, collaborated with MSKCC’s team to accelerate the labeling of training data and enabled data-centric iteration. Working together, the team quickly developed a model with an overall accuracy of 93%.
This now powers an AI-driven screening system to classify patient records at scale, speeding recruitment for clinical trials and advancing treatment research and development.

“It took me a long time to build the Regex model [outside of Snorkel Flow]; I read hundreds, thousands of pathology reports to make it work. Whereas [with Snorkel] it was a few hours to get to the results we achieved—a pretty dramatic difference.”
John Cadley
Bioinformatics Engineer, MSKCC
More customer stories
View all stories

Deploying production AI in <60 days to accelerate claims review 67%
A leading global firm transforming insurance subrogation operations with AI found that manual review processes capped their throughput to ~30% of available claims. This bottleneck left significant revenue on the table and froze their ability to scale. The path to automation was further blocked by severe data imbalances where the critical signals for coverage appeared in only a small fraction of claims, making traditional AI models unreliable.

DIU enhances decision-making resilience with Snorkel AI
Strategic dominance in the Indo-Pacific relies on the ability to track and coordinate friendly forces — ”blue objects” — with absolute precision. To maintain operational awareness in dynamic and contested environments, the Department of War identified a requirement for adaptable, dual-use technologies that enhance logistics and decision-making resilience.


