Fine-tuning pre-trained large language models like Meta’s Llama 2 adapts them to specific tasks, ensuring higher quality results and achieving reliable output formatting. The Snorkel Flow data development platform makes it easy for users to do so, making LLMs like Llama 2 work better for their domain and enterprise requirements.
In this guide, we will explore how to fine-tune Llama 2 using Snorkel Flow in two ways:
- A user-friendly interface for accessing and fine-tuning all available models.
- A built-in Jupyter notebook for advanced training customization.
Let’s get started.
Why Fine-Tuning
Fine-tuning is crucial for several reasons.
- Better performance: Use your data to train the model to perform better on your most important tasks.
- Customized Output Formatting: Adapt the model to match the specific tone required for different use cases.
- Improved response times: Customized models require fewer tokens in their prompts, allowing the model to arrive at an answer more quickly.
- Cost optimization: Fine-tuned models achieve better results than generalized models. This reduces prompt engineering and delivers users an acceptable response in fewer attempts, thereby reducing costs.
The cost benefits of fine-tuning Llama 2 come with a small caveat: fine-tuning the model means paying for GPU hours. For less-frequently used tasks, fine-tuning costs may exceed the aggregate savings from reducing prompt length, but data science teams should find little difficulty identifying high-frequency tasks.
For more detailed information about fine-tuning Llama 2, please refer to Meta’s official documentation. This blog is tailored for Llama 2 7B, the smallest of Meta’s three Llama variants.
Steps to fine-tune using Snorkel Flow
To fine-tune Llama 2 in Snorkel Flow, follow these steps:
- Evaluate the base model on zero-shot learning to establish our baseline performance.
- Import the data set and fine-tune the model to adapt it to our targeted tasks and domain.
- Analyze predictions from the fine-tuned model to evaluate the impact that fine-tuning had on the model’s performance.
The following sections will investigate each step in detail.
Dataset: Amazon Reviews
This demonstration uses the Amazon Reviews dataset, accessible here. It features high-cardinality text classification with 64 classes, making it a valuable resource for experimenting with text classification.
Step 1: Evaluate the base model on zero-shot learning (ZSL)
Start by evaluating how Llama 2 performs on Amazon Reviews using zero-shot learning. This step establishes the model’s baseline performance and identifies areas that need improvement.
Let’s start with a simple prompt for this approach —a base prompt that describes the text fields and the classification task.
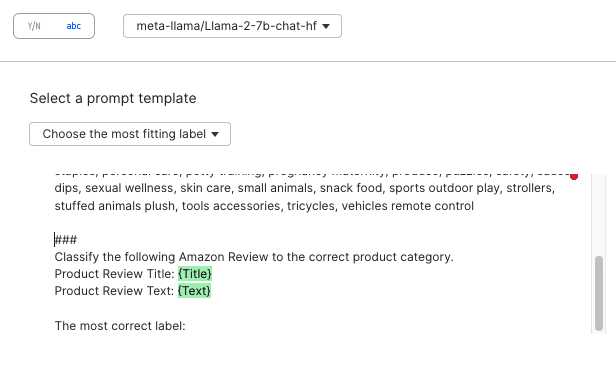
You can easily register your first prompt for evaluation in Snorkel Flow. The current ZSL prompt achieves 15% accuracy and 12 F1 macro score—far from deployable.
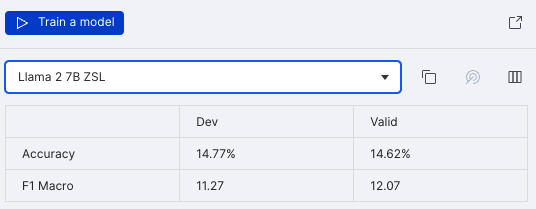
We could coax better results with prompting techniques, but that’s outside the scope of this post. While Snorkel Flow users must provide a good base prompt, they will not need to perform any complicated prompt engineering. The performance improvement achieved by fine-tuning will also outstrip those achievable by customizing prompt templates.
Step 2: Labeling and fine-tuning
After uploading data to Snorkel Flow, you can easily fine-tune a personalized version of Llama 2 through the UI and customize training parameters as needed.
You can perform this fine-tuning pipeline in two ways:
- Using your current labeled data directly.
- With a data set sharpened and refined through manual labeling or with Snorkel’s proprietary programmatic labeling tools.
For simplicity, we fine-tune Llama 2 on a subset of 300 data points and observe the model. Here, we fine-tune using the LoRA technique utilizing Hugging Face’s transformers and peft packages.
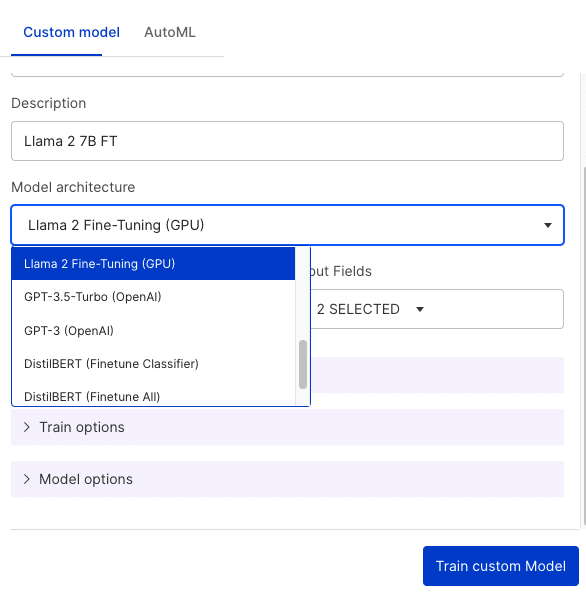
The Snorkel UI provides a simple, no-code interface for training purposes.
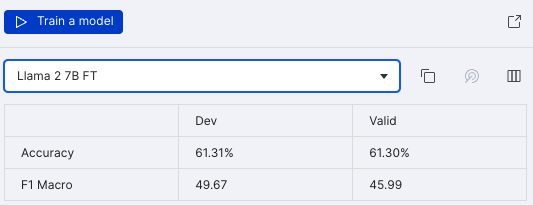
After fine-tuning with this small subset of data, we already see a jump in performance—with no prompt engineering and very little development effort.
The platform also accommodates advanced users with high customization requirements through the built-in Jupyter Hub interface. Snorkel Flow users can export the labeled data and fine-tune Llama 2 in a standard notebook.
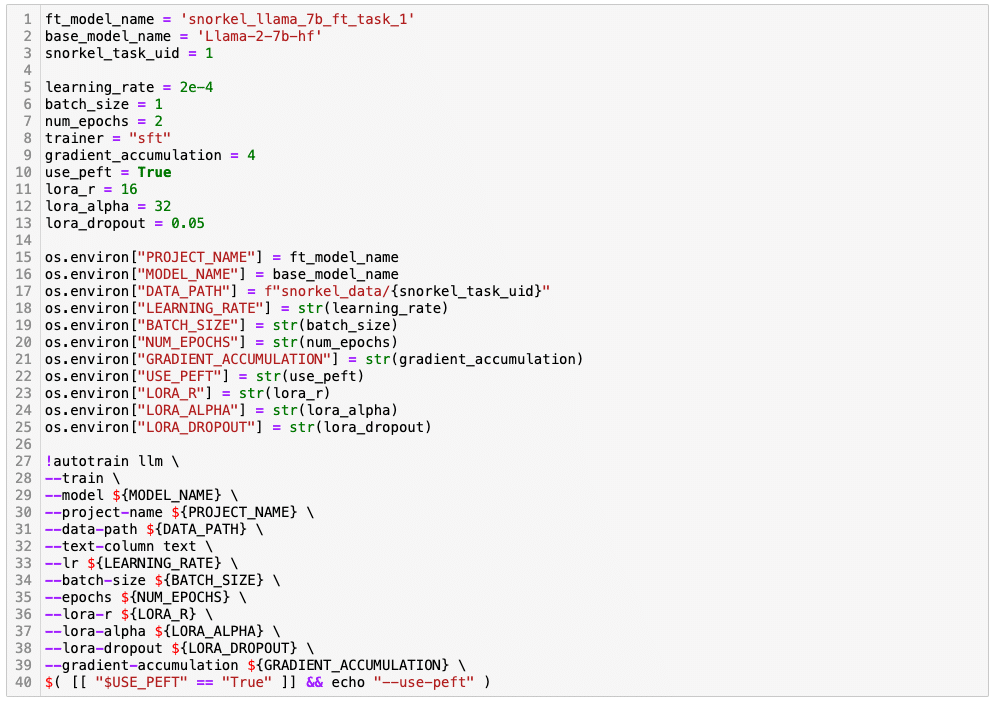
Snorkel also supplies customers with more comprehensive code notebooks with best practices and further customization where needed.
Step 3: Analyze Predictions and Iterate
If the model’s performance needs further enhancement after fine-tuning, you can use Snorkel’s analysis workflow to analyze the predictions and further improve the model through:
- Hyperparameter tuning: Such as changing the batch size, learning rate, epochs, etc.
- Adding more data: Increase the volume of training data through manual addition or by creating Labeling Functions (LFs) in Snorkel Flow. Then, users can fine-tune a new version of the model. Our error analysis tools help identify slices of data that require more attention, and Snorkel’s technology can help address those slices’ shortcomings.
- Adding guardrails and post-process predictions: Ensure the model’s safety and reliability, and post-process the predictions for optimal results.
The Snorkel Flow platform offers all of these options natively.
If you would like a more detailed look at how you can iterate on prompts and data, fine-tune, and distill for a production use case, read this blog.
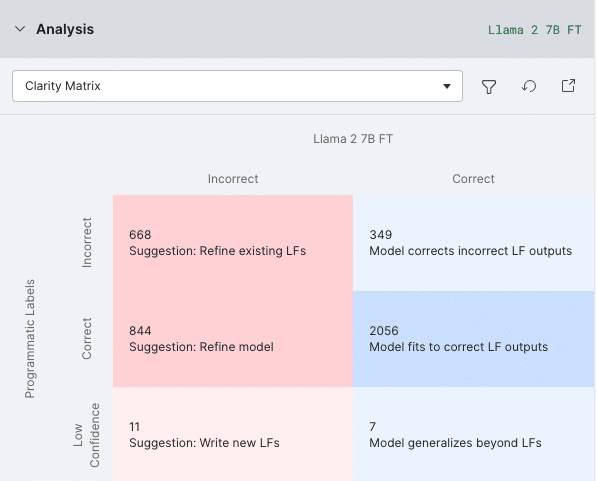
Fine-tuning Llama 2 is easy on Snorkel Flow
In Snorkel Flow, users can evaluate the Llama 2 base model’s performance, label data, fine-tune, and analyze predictions—all within the user interface. More advanced users can move their workflow into the on-platform notebooks to achieve any additional customization they need. Advanced users can also fine-tune other models by replacing the “base_model_name” variable with any model compatible with Hugging Face autotrain, such as Mistral or Llama 1.
All of this makes Snorkel Flow a comprehensive platform for handling all aspects of LLM fine-tuning, enabling users to build specialized and high-quality models effectively. By leveraging Snorkel Flow, teams can ensure that their models are well-adapted to specific tasks and provide reliable and consistent results in real-world applications.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.
