
Snorkel AI is thrilled to announce our partnership with Databricks and seamless end-to-end integration across the Databricks Data Intelligence Platform.
This integration grants Snorkel Flow users access to data within Databricks with just a few clicks (as detailed here) while also facilitating the streamlined registration of custom, use-case-specific models to the Databricks Workspace Model Registry.
The synergy between Snorkel and Databricks enables data scientists to navigate their entire machine learning pipeline—from data access to model deployment—all within Snorkel Flow.
Closing the loop with end-to-end integration across the Databricks platform
Snorkel Flow integrates seamlessly into existing enterprise workflows. Snorkel offers a full suite of third-party data connectors, making data stored in popular cloud repositories like Databricks quickly and easily accessible for data-centric AI development with Snorkel Flow.
The new Databricks Model Registry integration equips Snorkel Flow users to automatically register custom, use case-specific models trained in Snorkel Flow to the Databricks platform, which provides a unified service for deploying, governing, querying, and monitoring models.

Data-centric AI development with Snorkel Flow
One of the most painstaking and time-consuming issues with developing AI applications is the process of curating and labeling unstructured data. Snorkel AI eases this bottleneck with the Snorkel Flow AI data development platform.
Data science and machine learning teams use Snorkel Flow to intelligently capture knowledge from various sources—such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models and large language models—and then scale this knowledge to label large quantities of data.
As users integrate more sources of knowledge, the platform enables them to rapidly improve training data quality and model performance using integrated error analysis tools. Once they have completed the data labeling process, Snorkel Flow users can apply their labeled data to train predictive models or filter data for generative AI applications.
Snorkel Flow + Databricks Model Registry
Snorkel further streamlines the machine learning development process for organizations that rely on Databricks through a native integration with Databricks Model Registry built directly into the platform. After training, adapting, or distilling a model using the Snorkel Flow data development platform, users can easily register their custom, use case-specific models to the Databricks Workspace Model Registry with just a few clicks.
Here’s how it works:
- Register a new model registry for your Databricks workspace and access token.
- Fill out the experiment name in the format /Users/<your-username>/<experiment_name>, where <your-username> should be your Databricks username.
- Upon clicking the “Deploy” button, Snorkel Flow registers a model to your Databricks Workspace Model Registry.
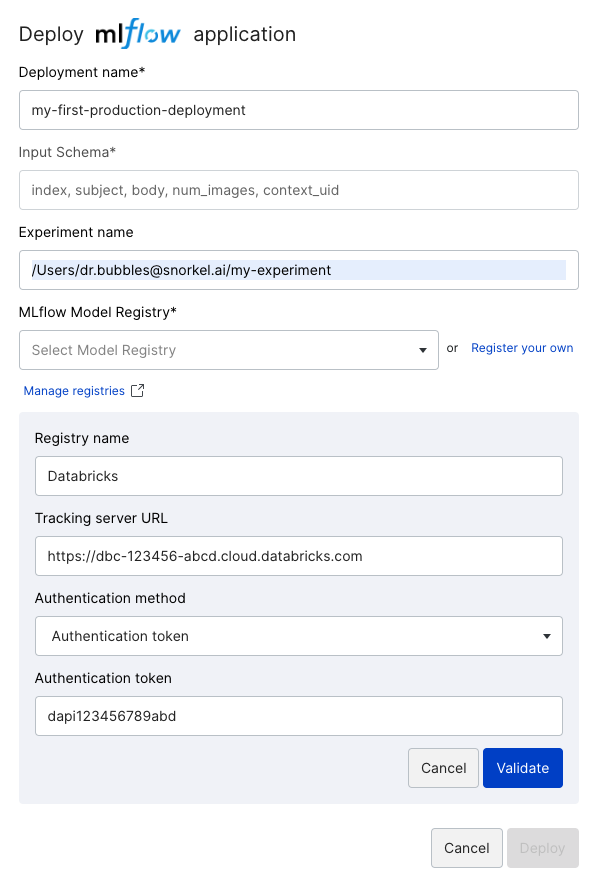
Once users register a model to the Databricks Workspace Model Registry, they can deploy the model to the Databricks Model Serving or use it on a Spark cluster.
In an upcoming release, Snorkel will expand this integration to allow registering a model to the Databricks Unity Catalog.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Hiromu Hota
Machine Learning Engineer
Hiromu Hota is a Staff Engineer at Snorkel AI, where he brings extensive expertise in applied machine learning as the Tech Lead Manager and Lead Machine Learning Engineer. Prior to Snorkel AI, he held roles as a Senior Researcher and Researcher at Hitachi, focusing on advanced research and development. Hiromu also serves as a Visiting Scholar at Stanford University’s School of Engineering, where he contributes to academic advancements in computational science and engineering.
With a background that includes software engineering at Hitachi Data Systems and internships, Hiromu holds a Ph.D. in Computational Science and Engineering and a Master of Engineering from Nagoya University, underscoring his deep technical knowledge and academic achievements.
Connect with Hiromu to discuss machine learning, computational science, or collaborative opportunities in applied research and engineering.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

