Customer story

Impact
10K
Hours saved for investment managers
1-3s
To assess each document vs. up to 90 min
50+
Custom attributes detected and extracted
A global custodial bank partnered with Snorkel’s experts and used our proprietary technology to build an application that saved thousands of hours of manual, expert information extraction. The application, built in just a few weeks, streamlined KYC verification as part of customer onboarding. Snorkel’s experts extracted 50+ attributes from various document formats, such as PDF and Word documents, and adapted the AI applications to changing business requirements or compliance regulations.
Extracting information from 10-Ks documents for KYC
Financial institutions are obligated by government policies to carry out customer due diligence as part of customer onboarding. For example, the U.S. Department of the Treasury Financial Crimes Enforcement Network (FinCEN) requires covered financial institutions to identify and verify the identity of beneficial owners of legal entity customers as one of the measures to comply with Anti-Money Laundering (AML) and Anti-Terrorist Financing (ATF) laws and regulations.
Challenge
Analysts and investment managers at a global custodial bank spend over 10,000 hours manually reviewing and transcribing 10-Ks as part of their thorough Know Your Customer (KYC) process. Buried within these PDFs is critical customer information that enables the bank to verify a company’s identity, establish a risk profile, and inform multiple business processes.
Because 10-Ks come in various formats, this bank has hundreds of analysts spending 30–90 minutes per doc and processing over 10,000 documents each year. If a critical bit of information is missing or incorrect, analysts have to hunt it down, which lengthens the customer onboarding process and allows competitors to swoop in.
The bank initially attempted to solve the problem using a rule-based system. This was rigid and could only identify a narrow scope of information for certain document formats/layouts. Constant changes in regulations across several regions made the system overly complex, and it required frequent updates that took months to implement.
The bank saw an opportunity to leverage machine learning to extract the data, but the time required to manually label a high-quality training dataset would be arduous. The data labeling required internal subject matter expertise and couldn’t be outsourced. This meant data science teams needed to collaborate closely with subject matter experts and analysts to accurately extract the information.
Additionally, the team needed to work in close collaboration with subject matter experts and analysts to extract information from a wide variety of document formats. But given that the ML development lifecycle was siloed into data labeling and model training phases, it wasn’t easy to improve the data and model quality systematically to scale.
- Lack of adaptability to inevitable changes in objectives or production data.
- Manual training data labeling was a bottleneck to building AI to automate this effort.
- Poor collaboration between domain experts and data scientists made it difficult to resolve ambiguous labels
Goal
Create an adaptable AI application to extract information from industry documents faster by reducing the time and manual effort needed to label a high-quality dataset.
Solution
Solution
Snorkel’s experts used our proprietary technology and worked alongside the bank’s data scientists, data engineers, ML engineers, and SMEs. Together, this team built a high-quality AI-based solution that saved the bank 10,000+ hours and hundreds of thousands of dollars in costs associated with hand-labeling.
The joint team attained an +86 F1 macro score for risk profile with just 25 hours of SME time. In a few short weeks, Snorkel’s experts created an AI application that takes PDFs of 10-Ks and extracts 50+ different attributes—such as nature of business, location, and key senior managers—from tables, raw text, and multi-page PDF documents.
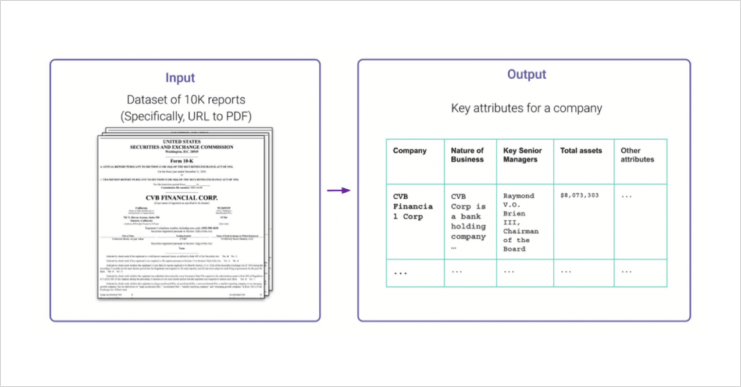
Next, the application classified extracted entities and carried out document-level aggregation before outputting all data to a structured tabular format for advanced analytics downstream.
- Ensuring adaptability with rapid code edits to labeling functions, avoiding wholesale manual relabeling.
- Scaling labeling of complex, domain-specific text through programmatic labeling.
- Improving collaboration between domain experts and data scientists across labeling, troubleshooting, and iteration.
This collaboration accelerated the delivery of the bank’s KYC solution by streamlining the creation of high-quality training datasets. It also enabled their experts to devote more time to onboarding clients sooner. Snorkel’s proprietary technology gave the bank the flexibility it needed to stay compliant with the latest regulations and avoid expensive fines stemming from data errors.
Ready to get started?
Take the next step and see how you can accelerate AI development by 100x.
