We’re excited to announce new natural language processing (NLP) features in Snorkel Flow’s 2024.R3 release, tailored to help you tackle complex document intelligence challenges. NLP is vital for our customers—it’s key to extracting insights from unstructured and structured text, and the first step to unlocking enterprise AI at scale.
Our latest updates include:
- Named entity recognition (NER) for PDFs (beta)
- An enhanced annotation suite
- Advanced sequence tagging analysis tools
These features are designed to streamline your workflows, boost annotation efficiency, and provide deeper model insights—all to help you unlock the full potential of your textual data.
Read on to discover how these updates can accelerate your AI development and enhance your NLP initiatives.
Learn more about:
- The full breadth of our 2024.R3 features
- Data compliance and security upgrades
- Our new GenAI evaluation suite
Named entity recognition (NER) for PDFs (beta)
Introducing word-based NER for PDFs! This beta feature lets users extract entities directly from any text in complex, unstructured PDF documents—including scanned documents.
Our new word-based UI enables unprecedented flexibility to PDF annotation and data development. Users can extract any word for any entity, making it perfect for complex and high-cardinality use cases.
Feature highlights
- Intuitive word-based extraction: Annotate documents effortlessly by simply drawing a bounding box around one or more chosen words. Users can also double-click on individual words. This process captures visual structures and spatial relationships within documents.
- Create labeling functions (LFs) and PDF models directly in PDFs: Build pattern-based and large language model prompt-based LFs at the word level, quickly scaling up your programmatic data labeling. With the training set, you can then train advanced models capable of processing PDFs that you can directly deploy in production.
- PDF sampling with full document view: Sample random pages from your dataset to capture document variability and view full documents for context using the new Page View. This allows efficient handling of large documents while retaining complete context.
- Iterative error analysis: Detailed error analysis helps you create production-ready datasets and models in the same loop, accelerating improvements and enhancing accuracy in your NER tasks.
Enhanced annotation suite
We’re introducing significant enhancements to our annotation suite to reduce annotation time, improve label quality, and enable more flexible workflows. These improvements make it possible for both annotators and data scientists/reviewers to efficiently scale as you work on more complex use cases.
Feature highlights
- Multi-schema support for PDFs: Our annotation suite now supports multi-schema annotations for PDFs, enabled by the new NER workflow. This allows users to define multiple label schemas within a single annotation project and for annotators to handle complex annotation tasks in one shot.
- Improved batch creation and management: Streamline dataset management with smarter batch creation. Select new and unlabeled data rows, choose how you sample your data, and distribute workloads evenly among annotators.
- Annotation instructions and label descriptions: We’ve added support for annotation instructions and label schema descriptions/examples. These guides help annotators understand exactly what to label and how, reducing errors and improving label accuracy.
- Highlight-to-Label: Bulk apply sequence tagging annotations with our new Highlight-to-Label functionality. Just choose your labels from the right-hand panel, then highlight text to instantly apply annotations. Pro tip: pair this with Ctrl+F/Cmd+F or regex search to supercharge your annotation speed!
- Bulk delete batches: Easily manage and clean up annotation tasks by deleting multiple batches at once, saving time and keeping your workspace organized.
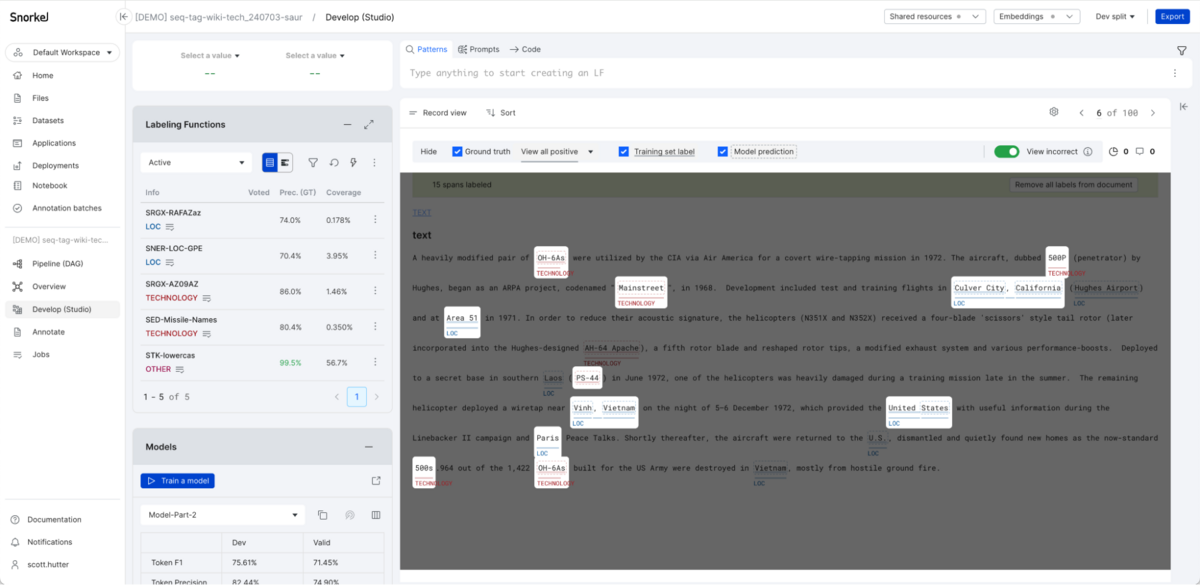
Advanced sequence tagging analysis tools
With our latest updates, analyzing and improving your sequence tagging models has never been easier. Our new analysis tools provide deeper insights, helping you zero in on problem areas quickly and refine your models faster.
Feature highlights
- Spotlight mode for focused debugging: We’ve introduced Spotlight mode, a powerful visualization tool to zoom in on specific errors in your model and training set predictions. This mode highlights and isolates incorrectly predicted entities, allowing you to identify and resolve LF and model errors faster.
- Class-level metrics in model iteration graphs and analysis: Gain a clearer picture of how your model performs on an entity-by-entity basis. Track performance across different classes, see trends over model iterations, and understand where your model excels or needs more attention.
Building the future of NLP with Snorkel Flow
With the 2024.R3 release, Snorkel Flow’s new NLP features are designed to transform how you interact with unstructured and structured data—empowering you to annotate, extract, and analyze text more efficiently than ever before. From NER for PDFs to smarter annotation workflows and powerful analysis tools, we’re bringing you the capabilities to unlock the full potential of your data and accelerate your AI development.
Try out these features today and see how Snorkel Flow can elevate your NLP workflows. We can’t wait to hear what you think.
Ready to accelerate AI development?
Deploy production AI and ML applications 10-100x faster with Snorkel’s experts, using our proprietary technology.

Jennifer Lei
Senior Product Manager
Jennifer Lei is a Senior Product Manager at Snorkel, where she leads various document intelligence use cases. She has a background in driving cloud and AI projects through her product role at Microsoft Azure, complemented by strategic experience with Microsoft’s Corporate Strategy team and at McKinsey & Company.
Recommended articles
View all articles

The Standard for Agents You Can Trust: Lessons from the Federal Front Lines
In the first installment of Agentic in Action — a series about real AI deployments, not demos — Snorkel AI’s Kevin Olivieri sat down with three people who have spent their careers where trust isn’t optional: Chris Sniffen, Federal Applied AI Lead at Snorkel AI; John Hickey, President of August Schell; and Mike Baca, CIO of August Schell. The conversation focused on
June 5, 2026
•
Snorkel Team

Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration
At our latest Snorkel AI Reading Group, Yijia Shao (Stanford NLP) stopped by our San Francisco office to present Collaborative Gym: A Framework for Enabling and Evaluating Human-Agent Collaboration. As LLM agents get better at automating tasks on their own, a large class of real-world problems still needs a human in the loop – for their preferences, their domain expertise, or simply for control.
June 4, 2026
•

Benchtalks #2: The future of coding benchmarks
For our second Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with John Yang, a Stanford PhD student and creator of the SWE-bench franchise, SWE-smith, CodeClash, and most recently ProgramBench. Highlights More on ProgramBench: See the benchmark and the upcoming leaderboard at programbench.com. More from John Yang: Publications and writing at john-b-yang.github.io. Snorkel
June 3, 2026
•

