
The central innovation team at a top 3 US bank wanted to speed delivery of a custom natural language processing (NLP) model to extract important financial information from 10-Ks. Without a machine learning solution, expert analysts were spending hundreds of hours each year manually reviewing these complex documents.
With Snorkel Flow, the team used weak supervision to label programmatically and rapidly iterate to train a custom NLP model. This model automatically and accurately extracts interest rate swaps, allowing analysts to shift their time from onerous document reviews to more strategic client support and new business development.
Using NLP to extract complex financial information from 10-Ks—and free analyst time
A team of highly skilled foreign-currency exchange analysts at this top 3 US bank spends hundreds of hours each year reviewing 10-K and 10-Q documents, looking for specific information about interest rate swaps to help clients manage their risk exposure. This high-effort review meant the team was constrained in their ability to provide clients with additional strategic value. The bank knew this task could be solved by training a custom NLP model to automatically extract interest rate information across a variety of different document formats, freeing up valuable time for their analysts to proactively help their customers.
Challenge
While the team recognized the potential for AI and NLP to streamline 10-K processing, they lacked the required training data to train a model that could automatically identify and extract interest rate swaps from 10-Ks accurately across multiple formats. Like the manual review process, labeling training data is labor-intensive, requiring analysts to carefully comb through hundreds of pages of financial data, looking for any mention of interest rate swaps. Adding to the challenge, 10-Ks come in a variety of unstructured formats, making it difficult to find and extract the relevant data. Not only did this take precious time away from working with customers, but it also introduced risk of human errors and inconsistencies.
The bank attempted to create high-quality training data by hand-labeling in-house, but this was error-prone and slow; it took the team months to label. An additional pain point the team experienced was the need to re-label their datasets regularly due to business objective changes, adding time and cost to the project (and frustration for the analysts who had to start over and manually label data again).
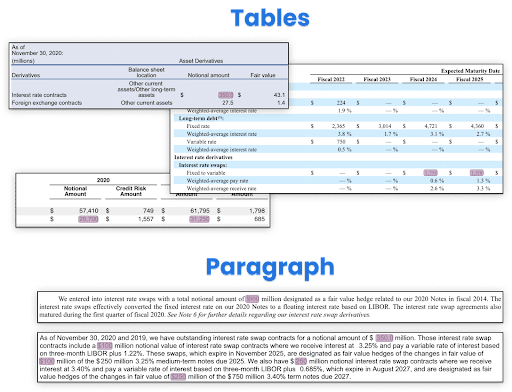
- Extensive domain expertise was required to identify the relevant information to be extracted from thousands of documents.
- Rich information was buried within tabular and raw text in PDFs, with varied formatting across reports from different companies.
- Time to label training data for the NLP solution was prohibitively slow given the reliance on manual labeling and an inability to outsource.
Goal
The bank wanted to reduce the amount of time subject matter experts spent manually reviewing 10-Ks and use the freed capacity to better serve their customers.
Solution
Using Snorkel Flow’s data-centric AI development workflow, the bank built an AI solution that significantly improved its slow and labor-intensive process of manually extracting interest rate swaps from complex documents. Using programmatic labeling and weak supervision to encode analyst expertise as labeling functions (LFs), the team trained a custom NLP model that could automatically identify and extract interest rate swaps with an F1 score of 83 in just a few weeks.
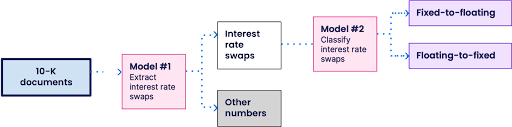
The team was able to automatically label 70,000 training data points per minute, greatly accelerating the training of a high-performing model capable of handling the various 10-K document formats. Because the labeling rationale was encoded as LFs, the team was also able to adapt to changes in data or business goals with ease. In response to one shift, rather than having to start from scratch, they simply modified approximately 30 LFs and regenerated their entire high-cardinality dataset in minutes, saving time and resources.
- Auto-labeled training data by capturing labeling expertise as labeling functions and applying intelligently en-masse.
- ML model generalized to variety of document structures, including unseen PDF and tabular formats.
- Ensured adaptability with rapid code edits to labeling functions, rather than wholesale manual relabeling.
Leveraging AI and NLP capabilities also meant that 10-Ks could be processed in near real-time giving the analysts access to more timely and relevant information with much less manual effort. Now, instead of relying on outdated assumptions, analysts can access the latest financial information at their fingertips to proactively help customers to manage interest rate exposure.
Results
2000+
hours/year saved for financial analysts
70k
labels/min generated programmatically
6 weeks
to build production-quality AI application

Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

