
Coding agents have moved from tab-complete to teammate. They autonomously inspect repositories, edit files, run commands, diagnose failures, and work through multi-step engineering tasks.
That creates a harder reliability problem. A model that only suggests code is easy for a human to evaluate. A coding agent refactoring your repository and testing its own changes is much harder to supervise – evaluation has to cover the full state of the work: the task, the environment, the tests, the trace, the review criteria, and the final behavior.
The question has moved past whether coding agents can produce code that looks right. The harder question is whether they can complete real software work safely, measurably, and repeatedly – and how we supervise it.
Coding agents are becoming software workers
Coding agents have moved through three eras: autocomplete, IDE chat, and agentic coding. Each era moves the model deeper into the software workflow.

- Autocomplete put the model inside the editor: The developer wrote code, and the model suggested the next line or block. The tool accelerated typing, while the developer still owned the task, the context, the tests, and the final judgment.
- Chat moved the model into the IDE: The developer could ask for a bug fix, a refactor, or an explanation while the model looked across more of the local workspace. Tools like Cursor, Windsurf, and Kiro made the model more useful, but the workflow still centered on a human reviewing and accepting changes.
- Agentic coding moves the model into the execution loop: An agent can take a task, inspect files, edit code, run commands, diagnose failures, and try again. Tools like Claude Code and Codex show this pattern clearly.
The third step is the important one. The agent is no longer only helping with code – it is touching the workflow around code.
This is already changing how teams work. Developers mix these setups by task: autocomplete for local speed, IDE chat for guided edits, terminal agents for repo-level work.

But the scaffolding around the model shapes the result. Two teams can both say they are using Claude, but one might be using Claude through Cursor and another through Claude Code. Those systems have different context windows, tool access, permissions, prompts, and execution loops.
That means performance depends on more than the base model. The harness matters. The environment matters. What the agent can see, what it can change, what it can run, and how it receives feedback all shape the results.
Faster coding creates a harder review problem
The risk is simple: vibe-coding becomes tech debt at scale. Coding agents increase output before they improve understanding.
The risk shows up in review. A patch can look coherent, pass a visible check, and still introduce a logic bug, weaken security, or add complexity that the next engineer has to unwind. The failure mode is plausible code at volume.
Recent usage patterns show why review has become the bottleneck. Anthropic’s 2026 Agentic Coding Trends Report found that engineers use AI in roughly 60% of their work but fully delegate only 0–20% of tasks. The gap matters. Coding agents are becoming constant collaborators, but most work still needs setup, supervision, validation, and human judgment.
That doesn’t mean coding agents reduce productivity. It means perceived speed and measured delivery have to be evaluated separately.
Code quality data points in the same direction. CodeRabbit reported that AI-co-authored pull requests had about 1.7x more issues overall than human-only pull requests, with higher rates of logic, correctness, and security problems. That does not make AI coding agents useless. It means teams need stronger review systems around them.
Case study: when a package install becomes a security event
The LiteLLM incident makes agentic coding security concerns concrete. LiteLLM is a widely used Python package for routing calls across LLM providers. On March 24, 2026, malicious versions 1.82.7 and 1.82.8 were published to PyPI with credential-stealing malware.
The payload targeted SSH keys, cloud credentials, API tokens, Kubernetes configs, database passwords, and other local secrets.
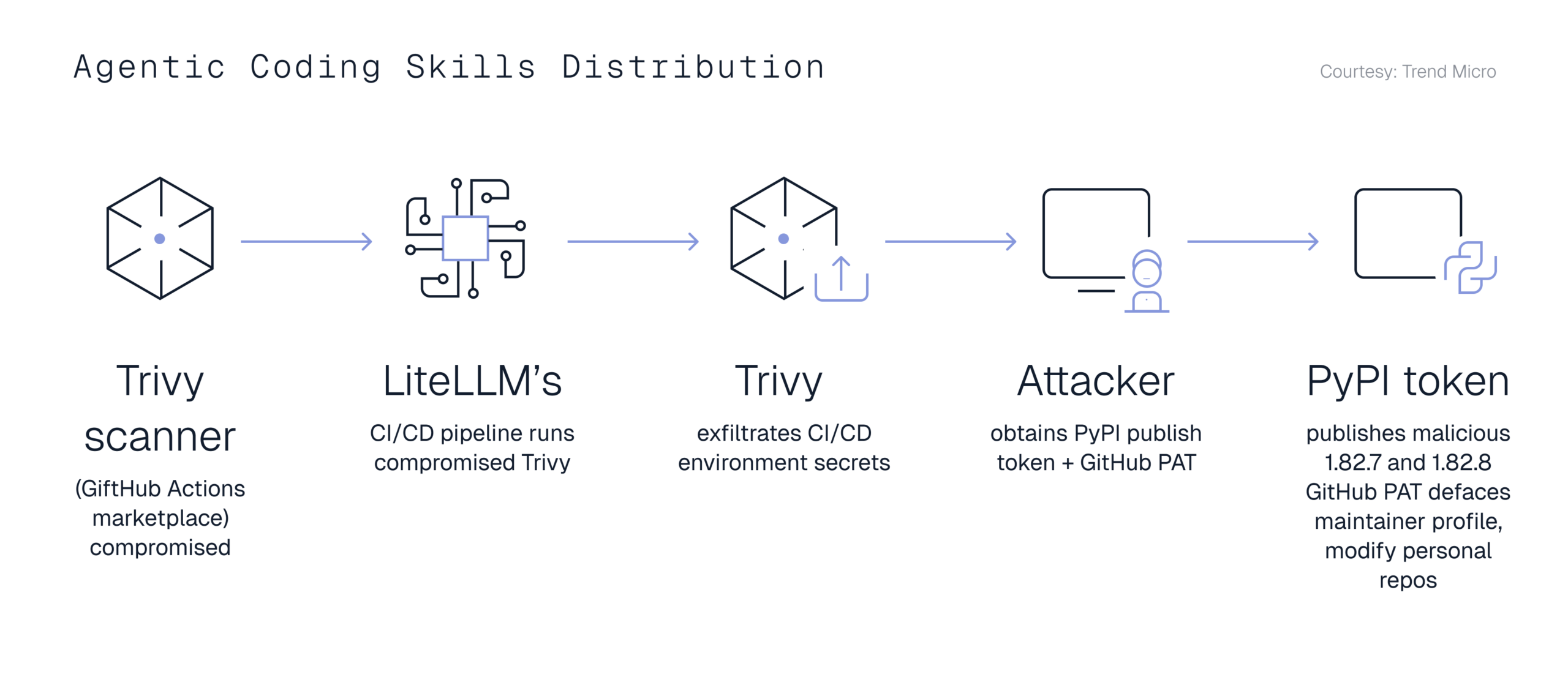
Trend Micro’s attack-chain diagram shows how a compromised Trivy scanner in LiteLLM’s CI/CD pipeline led to credential theft and the malicious PyPI releases. (Trend Micro, 2026)
The important detail is how ordinary the entry point was. Developers did not need to make a strange architectural decision. They only had to install or update a package. In version 1.82.8, a .pth file caused the payload to execute on Python startup – broader than a normal import-time bug, since the code ran whenever Python ran, with or without an explicit import.
LiteLLM is widely deployed across AI infrastructure, and a compromised dependency at that scale is an infrastructure risk, not a library risk.
That is the risk profile coding agents inherit. An agent with terminal access can install packages, update dependencies, call build tools, read environment variables, and touch internal systems. If the evaluation layer only checks whether the final code looks plausible, it misses the dangerous part of the workflow.
Faster code generation expands the review surface. Engineering teams need to know what the agent changed, what it installed, what it ran, what it skipped, and whether the result is safe to merge.
Benchmarks are moving closer to real software work
Benchmarks have always shaped how AI systems are built and compared. Coding agents give that discipline cleaner measurement surfaces, because software already produces evidence: repositories, issues, tests, CI logs, execution traces, dependency graphs, and review workflows.
A generated answer can be hard to judge. A software task can be run, inspected, reproduced, and tested against expected behavior. If an agent claims to fix a bug, teams can check the patch, rerun the tests, inspect the diff, and trace what changed.
SWE-Bench Verified helped move coding evaluation toward real repositories. It uses real GitHub issues, human-validated samples, and tests that check whether a generated patch resolves the issue – a stronger signal than isolated coding puzzles.
As basic benchmarks saturate, teams need to ask harder questions. Were the tasks public? Could they have entered training data? Was the harness standardized? Can another team reproduce the result? For enterprise use, the question is less can the model solve a known benchmark and more can the agent complete realistic work in an environment that matches how software teams actually operate.
Terminal-Bench 2.0 and Terminal-Bench 2.1, which Snorkel helped create, evaluates agents inside command-line environments on hard terminal tasks. That makes it useful for agentic coding because the agent has to inspect the environment, run commands, interpret failures, recover, and complete the task end-to-end.
The tasks include building Linux from source, training ML models, reverse-engineering binaries, and working through complex terminal operations. The benchmark measures behavior across the work.
Snorkel is building the data layer for coding agents
Better coding agent benchmarks do not appear by themselves. They require task design, executable environments, verifiers, rubrics, repair workflows, and expert review.
Once coding agents start acting inside repositories and terminals, evaluation becomes a data-development problem. The benchmark is only as useful as the tasks, environments, and signals behind it.
Snorkel Agentic Coding Benchmark: measuring multi-step coding work
The Snorkel Agentic Coding Benchmark gives that loop a public surface. It evaluates models on multi-step coding tasks with sandboxed execution environments, human-validated reference solutions, unit tests, and scoring rubrics.
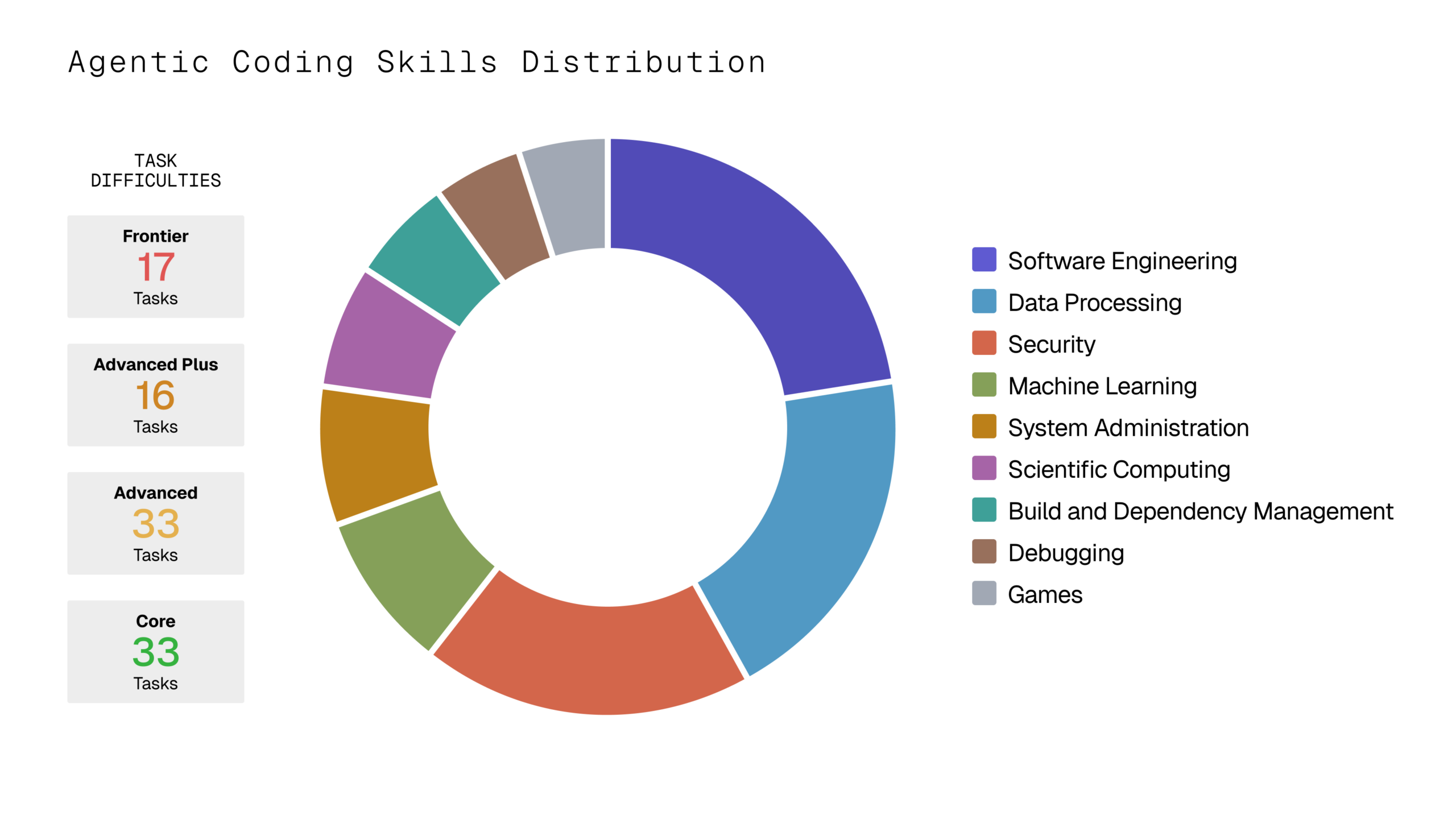
The benchmark is useful because it treats coding-agent work as a sequence, not a single answer. Agents need to understand the task, operate inside the environment, make changes, run checks, and recover when the first attempt fails.
Terminal-Bench 3.0: harder tasks, broader scope
Terminal-Bench 3.0 extends the benchmark for command-line agents. The target is 100 diverse tasks at an at-most 30% solve rate from the best models at release — difficult enough to separate frontier systems.
The scope goes beyond repository patching into realistic computer work that can be completed through the command line and verified programmatically: software engineering, system administration, security, scientific computing, data workflows, and ML tasks.
Calls for contribution are open for Terminal-Bench 3.0 →
This direction fits Snorkel’s larger work on agentic AI evaluation. Stronger benchmarks need harder tasks, richer environments, expert task design, and verifiers that survive frontier models. That is the data layer behind reliable coding agents: the task, the environment, the scoring logic, and the feedback signal.
Coding agents are becoming a broader pattern for work
Coding agents show the broader agentic loop in a concrete setting: read context, take action, verify the result, and iterate. That pattern is already moving beyond the IDE. Claude Cowork applies the same loop to research, writing, analysis, and operations work.
The next constraint is orchestration. Teams will need to coordinate multiple agents across planning, implementation, testing, review, deployment, and monitoring, while keeping human judgment in the right parts of the loop.
Software makes this transition visible because the work leaves evidence: tests, logs, traces, diffs, and review history. As agentic systems move into less structured domains, success will depend on building the same evidence layer: clear task definitions, executable environments, verifiers that match the work, and feedback signals that survive the next generation of models.
Talk to Snorkel’s research team about agentic coding and request dataset samples.
Researchers and practitioners interested in shaping the next generation of coding agent benchmarks can join Snorkel’s expert community.

Justin Bauer
Senior Research Scientist
Justin Bauer is a Senior Research Scientist at Snorkel AI, working on synthetic data, evaluation, and benchmarks. He previously interned at Google DeepMind and Tesla, focusing on reinforcement learning and sensor perception.
Recommended articles
View all articles

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

Continual learning and evaluating how AI agents learn across sequences of tasks
Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened. That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated
June 29, 2026
•

