
In the first installment of Agentic in Action — a series about real AI deployments, not demos — Snorkel AI’s Kevin Olivieri sat down with three people who have spent their careers where trust isn’t optional: Chris Sniffen, Federal Applied AI Lead at Snorkel AI; John Hickey, President of August Schell; and Mike Baca, CIO of August Schell. The conversation focused on government and regulated industries, where reliability and accountability are mission-critical. They get into why pilots stall on the way to production, why generic benchmarks don’t cut it for high-stakes work, what “good” actually means for an agent, how human experts make decisions that are hard to quantify, and the three questions every leader should be asking their technical team right now.
Transcript
Lightly edited for clarity and brevity.
Kevin Olivieri: Welcome, everyone. This is the first Agentic in Action event we’ve done. The series is about real AI deployments — not demos — and what it actually takes to get these systems into production. Today we’re focused on government and regulated industries, where trust, reliability, and accountability are mission-critical. We’ll talk about what breaks when teams move from experimentation to deployment, and what leaders need to see before they can trust these systems operationally. Let’s start with quick introductions — John, then Mike, then Chris.
John Hickey: I’m John Hickey, President of August Schell. We’re a cybersecurity company focused on the federal market. Before August Schell, I was the cyber executive at DISA, and the risk executive before that. And I spent 27 years in the Army operating, deploying, and developing networks and cyber capabilities.
Mike Baca: Mike Baca, CIO of August Schell — I work for John. I came out of the Marine Corps after 16 years. Early on I did human and counterintelligence, then moved into technical counterintelligence, where I ended up leading an interagency network and wireless threat-hunting training program. Today I also help federal customers identify solutions and solve hard problems.
Chris Sniffen: Thanks, Kevin. I’m the Federal Applied AI Lead at Snorkel AI. My background is also military — eight years in the Army before I moved to the National Security Agency, where I did a number of things but ended up in AI research before leaving to join Snorkel. Now I spend my time building custom agents and benchmarks for enterprises, which is a lot of fun.
Why pilots stall: trust, not accuracy
Kevin: Most organizations aren’t asking if they should use AI anymore. They’re asking why something worked in a demo and then, six months later, it’s stalled out. Chris, what are you seeing?

Chris: It’s all too common. The big difference between a demo capability and a production capability is trust. I need a demo to be useful, but I need a production tool to be reliable. Projects stall when teams can’t demonstrate sustained reliability in critical workflows — and demonstrating reliable behavior comes down to system evaluation, not generalized accuracy metrics, because those usually don’t cut it.
Adopting an AI system is a lot more like hiring an intern than buying traditional business software. If you’re hiring an intern, you wouldn’t make that decision based on their GPA. The GPA tells you something, but it doesn’t tell you whether the person can do the job, follow the right process, use good judgment, and know when to ask for help. That kind of complexity is closer to what we’re asking agents to do now. We’re asking them to work inside messy business processes — read ambiguous documents, interpret policy, retrieve evidence, use tools, and decide when something needs to be escalated. Those tasks don’t have “two plus two equals four” determinism. There may be multiple reasonable outputs, the right answer might depend on context, and the cost of being wrong can vary a lot from one case to another.
That’s where pilots stall. The demo shows the system can produce something useful, but production requires a different kind of evidence. Leaders need to know: where does the system work, where does it fail, how do we know, and what happens when it’s wrong? The bottleneck isn’t getting an agent to work once — it’s knowing when it’s reliable enough for a real workflow.
Not every use case carries the same trust burden. Off-the-shelf LLMs are already very useful in lower-risk, general-purpose workflows — drafting, summarization, research assistance. But the trust problem changes when AI moves into specialized, consequential workflows: underwriting, fraud review, clinical assessment, access authorization, cyber operations, procurement. In those settings, being generally capable isn’t enough. The system has to understand the organization’s policies, data, terminology, and risk tolerance. It has to know what evidence matters and what doesn’t, and when to make a recommendation versus when to escalate. The more consequential the workflow, the stronger the evidence has to be before leaders can trust it.
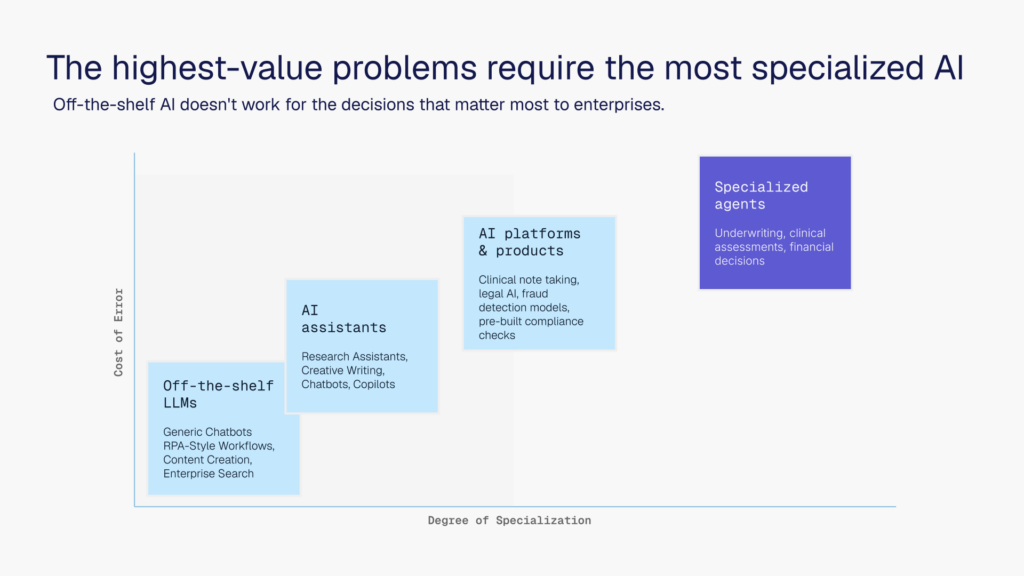
Kevin: For leaders listening, what does that evidence actually look like?
Chris: When I say evidence and not vibes, I mean trustworthy AI can’t be a subjective impression that the answer looks good. For a system to be trusted in production, leaders need evidence at several levels. The system needs to be tested on examples that actually represent the workflow they care about. They need evidence that the subject matter experts who work in that workflow agree with the evaluation criteria being used. They need evidence that the process the system followed — what it retrieved, what tools it used — is being tested at every point. And they need evidence that failures aren’t just logged somewhere but are being turned into improvements.
That applies across industries. In financial services it might be a payment hold or a fraud escalation. In insurance, a claim routed for special investigation. In healthcare, a chart prioritized for review — or something as consequential as a prescription refill. The common pattern is that AI output starts to affect the business or mission state. At that point, “the answer looks reasonable” is not enough.
The human is the most vulnerable part of the system
Mike: I want to hit on something. In my old line of work, I targeted humans to get into systems and environments that were extremely difficult to access — because the technical, operational, and procedural controls prevented access. So we’d target the humans. And it’s still effective today, because the human is always going to be the most vulnerable entity in any system, any equation, any security stack.
One of the go-tos I’ve seen is a customer thinking they can just connect their data to an LLM and it’ll give them all this wonderful output they can leverage. The problem is, most LLMs are built for engagement — the goal is to keep you on the model. So there’s a play on your own confirmation bias. When you get an output, it can be hard to stay objective and ask, “Is this actually valid?” Without any way to measure that, it becomes very difficult. How do you put the genie back in the bottle?
Kevin: John, in your environments a bad decision around AI isn’t just embarrassing — it can have real operational consequences. What has to be true before leaders can trust AI-generated decisions at scale?
John: I like good vibes — those are always good, and we’ve got a lot of people who can vibe-code now. But you still have to understand what those pieces look like. Take zero trust. The big push is for zero trust, but the biggest challenge is: do we have the data labeled well enough to make those decisions? Is it complete? Is it consistent? That’s a hard one, because it usually isn’t.
I’m a perfect example. Years ago, on the EUCOM staff supporting operations, I worked classified data — I was on SIPRNet most of the time, but the allied partners weren’t. When I had to make something happen, I’d make a guy like Mike nervous, because I had to figure out how to share information. Most of the time that information was overclassified. It’s the same problem today.
So it’s a matter of how you get after that. An AI capability can help overcome an impossible task of yesterday — how am I going to label all this data and get it right so I can make a solid decision? I think AI is going to enable that in real time, and that’s truly required to have trust in the data-sharing capability needed to support military operations and other areas of the federal government.
Kevin: What gives you trust in that system — that it’s classifying correctly and not under- or over-classifying?
John: That’s the question. There are technical challenges, but trust is still the core of it. In an AI world it comes down to whether you can trust the system itself and the agents making the correct decisions.
Kevin: In your experience, is the harder problem the technical one, or getting operators to trust the automation once it exists?
John: I think it’s the trust. There are technical challenges, but trust is the one that matters most.
Why benchmarks don’t cut it

Kevin: Chris, let’s tie this back to evaluation. A lot of teams say, “We tested the model, it scored well on benchmarks, we ran some examples internally.” Why isn’t that enough for these workflows?
Chris: Public benchmarks can be useful, but they often answer a narrower question than leaders think. A generic benchmark tells you how a model performs on a broad, standardized set of tasks in a domain. It doesn’t tell you whether the system is ready for your workflow, your data, your policies, your users, your tools — and it certainly isn’t calibrated to your error tolerance.
There are three common gaps. First, a general reasoning benchmark won’t tell you whether an agent follows your claims policy — that’s the specificity problem of your particular environment. Second, it misses the process. Most people compare aggregate statistics — “it got 87% on Terminal-Bench” — and that tells you nothing about how the agent got to that score. An agent can get the right answer and base it entirely on the wrong evidence. Third, benchmarks get stale. Your workflow changes, the operating environment is dynamic, threats and data change, and the benchmark has to keep up. Otherwise it’s point-in-time evidence that doesn’t keep up with reality.
So a benchmark score is useful, but it’s not evidence you can use to go from demo to production — unless it accurately reflects the workflow in your environment and considers the process inline.
Deciding under uncertainty
Kevin: Everything so far assumes you have the luxury of getting it right before it ships. Mike, your world doesn’t work that way — whether it’s a threat actor moving faster than your detection or a decision that can’t wait for the model to be perfect. How do you separate a recommendation you can trust from one that gets you into trouble?
Mike: Leaning into what John said — the mission still has to be accomplished. The mission could be combat, protecting a network environment, building a product, or controlling a water treatment plant. You have to make a decision when it comes down to it — maybe it’s a threat actor knocking on the door. As cheesy as it sounds, the Marine Corps beats into us that making a decision and executing it effectively is better than making no decision at all. “Analysis paralysis” is a common phrase for a reason. If we don’t decide and act, there can be real-world consequences.
Rewinding to my days as a human collector: I was a young Marine, and I once asked a base commander to shut down the base because I had an indication of a potential attack. Anyone in the military will understand — asking that as a young service member is very difficult. And I couldn’t fully articulate what I was thinking or why I made that assessment. Many factors were involved, but I still made the call.
Looking at warfare today — and I keep using combat examples, but the reality is most network threats we face are nation-state level. Most off-the-shelf solutions are pretty effective against the lower-level attackers, maybe 90% of them. But those lower-level attackers are now leveraging LLM and AI tools, ramping up quickly to be nearly as effective as nation-state actors. So if you’re a small piece of critical infrastructure — a water treatment plant — protecting your network, you’re often overwhelmed and under-resourced. This is no knock on critical-infrastructure teams; I’ve worked with many and most are extremely talented. But they have to make decisions based on automated systems going forward.
And sometimes those decisions are wrong. Back to my base example — my assessment was incorrect. But the reality is, I didn’t know it was incorrect: did the attack not happen because the base shut down, or because it was never going to happen? So as an operator, how do I trust the system I’m using to protect my network? I might be in a situation where I either shut the network down or keep running it with the risk that a threat actor has gained access. I have to weigh the implications of shutting down against how much I trust the tool that flagged the threat. Without that trust, you won’t make a decision based on the system — and the agent only disrupts your own methodology. You have to have some way to know whether the system is accurate for what you’re asking it to do.
Kevin: I’d love to dig into the cyber equivalent of a bad source report — where the system sounds confident but the evidence underneath is weak.
Mike: Agentic systems are really good at taking a defined process and producing a repeatable output. What they’re not great at yet is taking in the factors we as humans haven’t been able to define. Back to my example: why did I ask that commander to shut down the base? Many factors — the region, the mannerisms of the individual I was speaking to, what tribe they were part of, the code of ethics for that family or group. I couldn’t quantify those things on paper, but I could quantify them in my head. It was more qualitative than quantitative. That’s where we have to build a way to quantify what can be quantified, while understanding where qualitative assessments still need to occur.
Defining “good”: task, trace, outcome, rubric
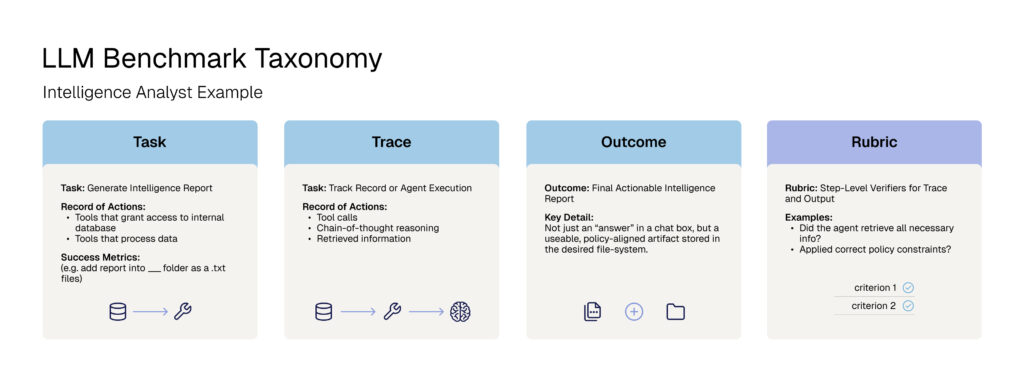
Kevin: Chris, when you’re evaluating an agent, how do you define what “good” actually means? What’s changed that makes this such a challenge?
Chris: The complexity of the tasks has changed. But the best way to dive in is to talk about what “good” looks like. We have to stop treating “good” as a generic property of a model — “the model is good enough.” We need to ask: good for what? Good for which workflow, which user, under what policy? Good enough to advise a human, or good enough to make a decision or trigger an action?
At Snorkel we define “good” at four levels: task, trace, outcome, and rubric.
The task is what the AI is supposed to do. A vague task creates a vague evaluation, so good starts with the right level of specificity. The trace is how the system got there — what it retrieved, which tools it used, what evidence it relied on, what it ignored. Good means looking beyond the final answer and inspecting the whole decision path. The outcome is what changed in the workflow — did the claim get routed, the ticket close, the document get labeled, the analyst receive a recommendation, an access decision change? Good means measuring the outcome that actually matters. And the rubric, which is arguably the most important part, ties it together: it’s how we judge whether the behavior as a whole was acceptable. Was it complete? Grounded? Policy-aligned? Calibrated correctly? Auditable? Was the failure mode acceptable for this workflow? Good means consistent grading based on subject matter expert input.
That ties directly to what Mike said. All those considerations that influence how a human approaches a task need to be encoded in the rubric, so that when we grade a model’s output, we do it consistently and in a way that aligns with how the human expert would pursue the task.
A simple example: imagine an agent designed to support intelligence analysis. It produces a polished-looking report. But when you inspect the trace, you discover it only drew from 10% of the available relevant data. If you only score the final answer, you’d think the system performed well. But if you evaluate the task, the trace, the outcome, and use a consistent rubric, you’ll realize the process isn’t trustworthy — and then you can make corrections. That’s where subject matter experts are essential. Engineers can build the harness and collect the traces, but the standard has to come from people who understand the workflow and the domain.
The human factor you can’t quantify
Chris: I like that we landed on intelligence analysts, because we’ve both worked with them. For those unfamiliar: intelligence is just information until analysis is put on top of it. That’s where most intelligence is created — information that an analyst examines and makes an assessment about.
Mike: And the way an analyst approaches a problem is really hard to quantify. I’ve worked with phenomenal analysts and terrible ones, and the phenomenal ones all approached information differently. That approach comes from the human factor: their upbringing, whether they’re a child of immigrants, whether they have a cultural background in the region, whether they fell in love with the subject on a childhood vacation, what aspect of the culture intrigues them, what they do in their free time. There’s a general framework for taking information and performing analysis, but it’s deeply subjective and very hard to quantify.
Chris: I couldn’t agree more. The difficulty in building these agents is understanding the subject matter expertise well enough to know what you’re trying to get into the system. It’s really hard.
A practical evaluation lifecycle
Kevin: Chris, it sounds like this is also a data development problem.
Chris: For sure. That’s what Snorkel has been doing for more than a decade — data-centric AI: how experts encode knowledge into systems, how data and evaluation assets are built, and how those assets drive model performance. We’ve learned through research and through working with the frontier labs and enterprise customers that evaluation isn’t just the test you run at the end. It’s the baselining at the beginning and pretty much every step along the way. For high-consequence systems, evaluation is a key part of the development process itself.
Kevin: What does that look like in practice?
Chris: First, don’t think of it as a single test — it’s a development lifecycle, not a bookend. A one-time test gives you a score. A lifecycle gives you a way to improve. We break it into four phases: understand, build, execute, and diagnose-and-report.
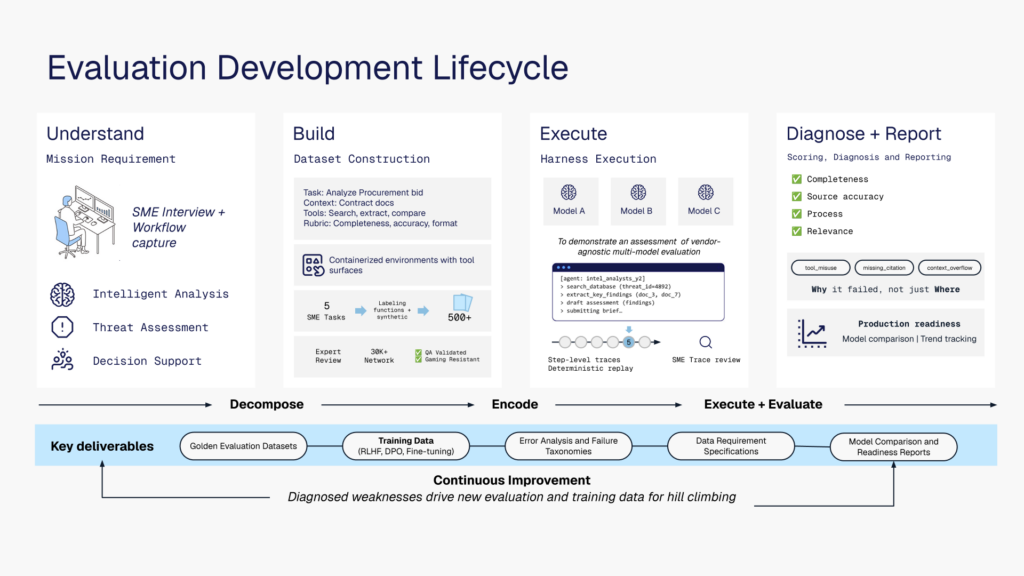
Understand the problem deeply. Sit down with the people who own the workflow and have done it for years. Ask what the AI is actually supposed to do, what decision it’s supporting, what they bring to bear when they make these decisions, what tools it needs, what policies it must follow, and which failures are completely unacceptable versus which don’t matter much. This sounds basic, but it’s where a lot of projects go wrong. A team says “we want an AI analyst” or “an AI claims assistant” — that’s not a task definition. The definition has to be specific: analyze this document, bid against these contract documents, use search and extraction tools, identify missing requirements, provide citations here. That specificity is what makes evaluation possible.
Build the evaluation assets from what you learned with the SMEs: representative tasks, golden datasets, the edge cases that need to be included, the grading rubrics, synthetic scenarios. For many systems now, it’s not just the question input — it’s all the context the model needs, so you can reproduce results over time as your live repositories change. And the SMEs stay involved: they define what good looks like, confirm the golden answers are correct, and identify edge cases.
Execute by running your model or agent through the evaluation harness, comparing different models or system parameters, and capturing full traces — every step the agent takes, which tools it used, what evidence it retrieved, where it deviated from policy, what outcome it produced. As much as possible, stay model-agnostic. You don’t want to be locked into one vendor; that’s where you get good comparative analysis and can swap things out.
Diagnose and report — this is where the real value is. You don’t just get a score that tells you where the system failed; you get a diagnosis that tells you why. Was it missing context? A tool-use error? Did it fail to retrieve necessary evidence? Was the rubric too vague, the task underspecified? Once you know why, you can decide how to fix it — better instructions, better retrieval, new training data, a different model — or decide the system shouldn’t automate that step yet.
This is why leaders should ask for failure taxonomies, not just metrics. If your team says the system is 86% accurate, that’s not enough. You need to know what’s in the 14%, decide whether those failures are tolerable, and confirm the team has a path to reduce them. And it has to be continuous. Workflows change, policies change, threats change. If the evaluation doesn’t evolve, the system may still look healthy on yesterday’s test set while failing on today’s reality. A practical evaluation system isn’t a launch gate — it’s a feedback loop: define the workflow, build the benchmark, run the system, diagnose failures, improve, re-evaluate. That’s how you move from demo to something you can operationalize.
When the model beats the human
Chris: When I first met with Snorkel, one of our people — Drew — had taken the CIA’s declassified documents and tried to verify that a system he built could classify them the way they were originally classified. He got about 60% accuracy. But as you think through the problem, those documents were classified by humans interpreting Security Classification Guides. My take was that his system was probably more accurate than the humans. I found it funny, because — Mike, you and I have worked in this system a lot — we have an inherent understanding that humans are very averse to particular kinds of risk. The last thing I want to do is under-classify a document and cause a spillage incident, so we tend to over-classify. The model doesn’t have that fear built in. It’s a fascinating problem.
John: I’d add why this is new from a speed standpoint. You’ve always had verification and validation in software development — the SME gives you a requirement, you have intermediate checkpoints, then they come back at the end and check whether it did what they asked. Anyone who’s worked on software knows that’s a long cycle with a lot of players and subsystems. Now that’s all on steroids — the speed at which you can do it.
Tie that to a military operation, where a classification today isn’t the same classification tomorrow. Take the Iranian operation going on — call it what you will. When it started, the information was shared with a very small group, because we wanted surprise. Now it’s become about how we keep oil moving through the Strait of Hormuz, and we’re sharing information that was classified very differently before. The beauty of agentic AI is it can keep up with that. But the SMEs have to keep up too, to change the process. That used to be a very human-intensive effort.
There’s always a need to not make mistakes, but humans make mistakes all the time. Anyone who’s run a military network knows spillage is real — we charge agencies for cleanup and hold people responsible. So this isn’t totally new. What’s different is the speed and the level of technical capability you need to be in the game. Military operations are moving faster than ever — we have UAVs and swarms, and a low-level player can do a lot. You have to develop that speed. To me, it’s still the experts who drive it — and now they’re empowered.
Kevin: There’s an audience question about whether you’re only using NLP-based LLM and generative models, or also more deterministic models within these agents.
Chris: It depends on the task. If you have the opportunity to use a more explainable model — a more traditional machine learning algorithm — we’ll absolutely still use it. This is where knowing what good looks like out of the gate matters for the engineers building your system. If I can define the task so it comes down to a binary question or a classification task, I’ll absolutely evaluate non-LLM models against it. It depends on the risk calculus the line-of-business owner or leader has. But the short answer is yes — we still look to employ other, non-generative model types.
Mike: On gaining trust and adoption for an organization: people sometimes want to just throw AI at a problem and expect it to solve everything. But if you can’t define the process and the task, you won’t be successful. So start small — with the tasks you can easily define and document — and from there you build buy-in across the organization.
Chris: Couldn’t agree more. Starting small, and starting with explainable when it’s possible, is always best.
Three questions every leader should ask
Kevin: Before the session, I asked each of you for the one question a leader should be asking their technical team right now. John, you get the hardest one: when the system eventually gets something wrong, who owns that failure?
John: I think we all own the failure — it’s a team effort. Ultimately the operations folks own it, and anyone who’s been a CISO knows you get pointed at; your job is to identify risk. But you learn more from failing than from succeeding. If I’m a risk executive in government today, I’ve got to take some risk to get this done, because the enemy is going to use AI offensively. We’ve got to treat it like a military operation. Most CISOs look at it that way — we have weaknesses and blind spots, and if we don’t evolve and accept that we’ll make mistakes and learn from them, we’ll fall behind.
The military has a chain of command — the commander is in charge and ultimately responsible. In companies it’s a little different, but the CEO or president is responsible. You can’t just turn to the CISO and blame them. It’s a team game, and the speed of interaction leads to what I call “team ball” — everybody on board, no hiding the problem. AI has brought problems to light, and we haven’t even seen the wave of offensive capability coming. We have to get quicker at putting out defensive capability. We can’t be risk-averse.
Kevin: Mike, when a team says “this is good enough,” what should leaders ask to understand what “good” actually means in that workflow?
Mike: I keep going back to the intelligence cycle — look it up. There’s a particular step that must occur for that cycle to be effective: feedback. We start by defining what we’re trying to accomplish — the same way Snorkel approaches it. If I can’t define it as a SME, then I’m not the right person to define that process, and we shouldn’t be building that agentic system. Once the process is defined and documented, we can build the system. But once we get the feedback loop, we have to be flexible enough to say, “Maybe I was wrong that this is a capability I could bring to my organization. Maybe I need to tweak my expectations, or I need additional information.” Does the agentic system have access to the data it needs to make the decision? We talked about this with data labeling and zero trust. As long as I can document that, give an output, and align it to my expected outcome based on my defined process — that’s good enough for me, in that workflow. The goal is to replicate what a human does.
Kevin: Chris, these systems aren’t perfect. In highly consequential workflows, what happens when the system is wrong?
Chris: I think about this a lot. I don’t usually like comparing AI systems to humans, but as a metaphor it works here. When you hire an intern, we have a whole legal system and set of policies that let us decide where to use an intern versus a 20-year veteran attorney. When someone has certain training and credentials, I trust them with certain tasks — which doesn’t mean they’re perfect; they’ll still fail sometimes. But we understand what that risk means legally and reputationally. Those scaffolds and shared assumptions don’t exist for AI systems yet. We don’t have a good shared legal grasp of where the reputational and legal risk lies when a system makes a bad judgment, up and down the chain. If Gemini is in the system, is it Google’s fault? Is it mine?
So what I spend time doing is talking with customers about how they perceive that risk and what they’ll do when the system fails. Are they willing and able to assume that risk? Because that helps us calibrate the evaluation to their expectations, so when the system does produce a wrong answer — and it will — we all share an understanding of what that means for the company, the commander, the analyst, or whoever is using the workflow.
Kevin: What I’m hearing across all three of you is that the question isn’t “is AI ready?” anymore. It’s whether your organization has built the scaffolding to trust that AI can perform as well as — or better than — your best experts, and to catch it when it doesn’t. That’s where the hard work comes in. That wraps today’s session. Thank you to our panelists, and to everyone who joined us.
Agentic in Action is a Snorkel AI series on real-world AI deployments. Snorkel AI is proud to partner with August Schell. Want to learn more? Reach out.
Recommended articles
View all articles

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

Agents’ Last Exam: AI Benchmarking for Real Work
At our latest Snorkel AI Reading Group, Yiyou Sun and David (Xinyang) Han (UC Berkeley, Center for Responsible and Decentralized Intelligence) presented Agents’ Last Exam (ALE) — a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. ALE is a collaboration between Berkeley RDI, Snorkel AI, and 300+ expert contributors across 55 professional subfields. ALE asks a deceptively simple question: can
June 30, 2026
•
Snorkel Team

