Most agent benchmarks evaluate each task as an independent episode. The agent receives a task, produces an answer, gets scored, and moves on. The next task starts as if the previous one never happened.
That setup misses a core requirement for deployed agents. A coding agent, research assistant, data analyst, or workplace assistant should improve as it works across repeated tasks from the same user, codebase, organization, or environment.
Today’s LLM-based agents are stateless by default. Any learning across tasks has to come from the surrounding system: memory, summaries, files, retrieval, feedback, or model updates.

Figure: Continual Learning Bench evaluates the full agent system. The agent acts in a task environment, receives feedback, and can read from or write to a memory system across task instances.
Continual Learning Bench, a collaboration between UC Berkeley SkyRL, Snorkel AI and UW-Madison evaluates this capability directly. It measures whether an agent system can retain useful experience across a sequence of tasks and use it to improve future performance against a stateless baseline.
This article explains the current state of continual learning, how Continual Learning Bench evaluates that capability, what the benchmark design tests, and what agent builders can take from it when designing systems for repeated coding, research, data, or workplace tasks.
What is Continual Learning?
Continual learning measures whether experience from earlier tasks changes performance on later tasks. In Continual Learning Bench, that experience can live outside the model weights, in memory, notes, summaries, retrieved context, or files the agent carries across the sequence.
Classic continual learning studies how a model learns from a sequence of tasks without losing earlier capabilities.
There are two basic ways a model can fail to learn continuously. The first is catastrophic forgetting, where performance on earlier tasks drops after the model updates on later ones. EWC is one early anchor for this problem: it tries to protect parameters that were important to earlier tasks. The second is the complement — a failure of transfer, where prior experience does not help (or actively hinders) performance on later tasks. The forward transfer metric tracks this directly, measuring whether earlier instances make later ones easier. This is also related to loss of plasticity, in which prior experience actually impairs learning on future tasks.
Prior work largely studies classification settings with weight updates. GEM uses episodic memory and gives the field useful language for backward and forward transfer.
Later surveys and taxonomies, including Van de Ven and Tolias, De Lange et al., and Shi and Chen et al., organize continual learning around task sequences, data access, replay, regularization, and parameter updates.
Continual Learning Bench moves the question into agent systems. The base model may stay fixed. The changing part may be memory, notes, summaries, files, retrieved context, or a persistent workspace.
Why sequence order matters
Figure: Continual learning tasks expose partial views of a larger structured world. The agent has to combine those views across task instances.
A continual learning task sequence is built around shared structure. Each task instance gives the agent a partial view: one rule, one constraint, one dependency, one convention, or one recurring failure pattern.
- A stateless system treats each task as a fresh problem. It can still solve individual tasks, but it cannot use earlier instances to reduce uncertainty on later ones.
- A stateful system has a different job. It has to decide which parts of prior tasks are worth preserving, then apply that compressed experience when the same structure appears again.
Continual Learning Bench evaluates whether that carryover changes performance. The benchmark does not reward memory for existing. It rewards memory when earlier task experience improves later attempts.
How continual learning works in Continual Learning Bench
Continual Learning Bench evaluates a system on an ordered sequence of task instances. The sequence matters. Earlier instances can expose information that helps on later ones, so the system has a reason to retain experience.
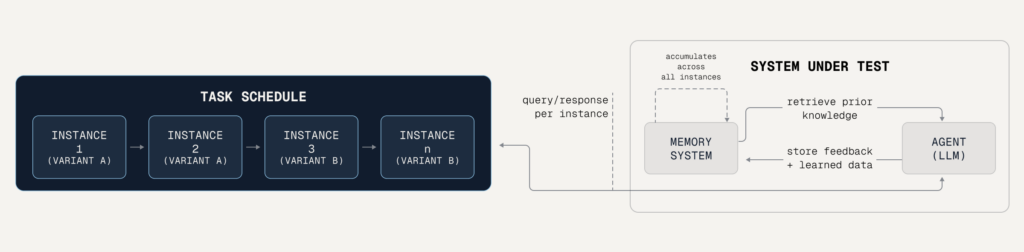
Figure: Continual Learning Bench runs the same system across an ordered task schedule. The memory system can accumulate information across instances, while each instance still gives the agent a fresh query-response interaction.
For each task sequence, Continual Learning Bench compares two runs of the same system.
- In the stateful run, the system can keep memory across instances.
- In the stateless baseline, memory is reset between instances.
The task sequence stays the same, but the system’s access to prior experience changes.
The two runs answer a simple question: did access to prior task experience change the result?
If the stateful system performs better than its stateless version, prior experience helps. If the two runs perform the same, the system may still be strong, but the benchmark has not shown that it learned across the sequence.
Continual Learning Bench tasks are related enough for prior experience to help, and varied enough that the system has to generalize.
How most agent benchmarks evaluate agents today
Most agent benchmarks score a fixed model or system on independent tasks. Each task starts fresh, gets scored on its own, and contributes to an aggregate score.
That design is useful for isolated task performance. It does not show whether experience from one task changes performance on the next.
Continual learning becomes relevant when tasks are ordered and related.
Earlier instances may reveal information the system should use later:
- a repository’s structure,
- a user’s preferences,
- a domain pattern,
- or a strategy that improves future attempts.
The evaluation has to measure whether earlier task experience changes later performance.
Recent benchmarks test adjacent pressures
Recent benchmarks are already moving agent evaluation past one-shot tasks:
- OdysseyArena evaluates long-horizon, active, inductive interaction, where agents have to discover transition rules through experience.
- AgentLongBench evaluates agents over long, dynamic context rollouts. Both test extended interaction, but memory is not the main variable being isolated.
Both make agent evaluation more sequential. They test whether an agent can keep acting over time, recover from feedback, and synthesize changing context. They still do not isolate whether the agent carried useful memory from one task instance into the next.
Memory and continual-learning benchmarks get closer:
- MemoryBench evaluates whether LLM systems can learn from accumulated user feedback during service time.
- MLLM-CTBench evaluates continual instruction tuning for multimodal LLMs, including answer accuracy and reasoning quality under forgetting.
- TRACE evaluates continual learning in LLMs across task datasets and measures how training on new tasks affects general ability and instruction following.
These benchmarks put memory, adaptation, or forgetting closer to the center. Continual Learning Bench shifts the test from model training or output quality to agent behavior across related task instances.
The same system runs with memory and without memory on the same sequence, so the benchmark can measure whether stored experience helped the agent discover reusable structure and apply it later.
What changes when the agent keeps state
Figure: In software engineering, each task can reveal a different part of the codebase. A stateful agent can carry those observations forward instead of rediscovering them on every issue.
A coding agent does not learn much from a task if it only stores the final answer. The useful signal is usually in the work around the answer: which files mattered, which tests failed, which command exposed the bug, which convention the repo follows, and which fix looked plausible but broke something else.
That is what the state has to preserve. A raw transcript may contain all of it, but still make the next task harder if the useful pattern is buried.
A better memory turns prior work into reusable notes: where to look, what to avoid, what the repo expects, and which checks are worth running first.
Continual Learning Bench makes that difference measurable. The same system runs the same task sequence with memory and without memory. If the stateful version improves later attempts, the memory system carries something useful forward.
Continual learning versus online learning and continual training
Continual learning, online learning, and continual training all involve experience over time. They differ in what changes.
Online learning updates a model from a stream of data. Continual training updates model weights through later training runs. Continual Learning Bench evaluates an agent system that may keep the base model fixed while changing the memory, notes, summaries, files, or retrieval context around it.
The benchmark asks whether limited, sequential experience improves later task performance without making the system start from scratch each time.
| Challenge | Continual learning | Online learning | Continual training |
| Core pressure | Accumulate and generalize across a task sequence without forgetting | Optimize performance from observed data | Reduce error on a static or slowly shifting distribution |
| Horizon | Indefinite, with pressure to compress experience into reusable abstractions | Stream or fixed sample budget | Periodic retraining windows |
| Autonomy | System state can change during use | Model updates are automatic | Usually managed through an offline training pipeline |
| Mechanism | Memory, notes, summaries, files, retrieval, or weight updates | Gradient-based updates | Offline training jobs |
Gain separates learning from raw model capability
| Metric | What it measures |
| Reward | Raw task performance. Higher is better. |
| Gain | Reward minus the same system’s stateless baseline. Higher gain means the system benefited more from experience. |
| Aggregate reward / gain | Task-level reward or gain normalized and averaged across tasks for cross-task ranking. |
| Cost | Estimated spend per rollout or across included tasks. Lower is better. |
Continual Learning Bench reports reward and gain separately because strong raw performance does not prove that experience helped.
Reward measures task performance. Gain measures improvement over the same system’s stateless baseline on the same task sequence.
Gain = stateful reward − stateless reward
A strong model can score well because it already has the needed capability. Gain asks whether access to prior task experience improved the result.
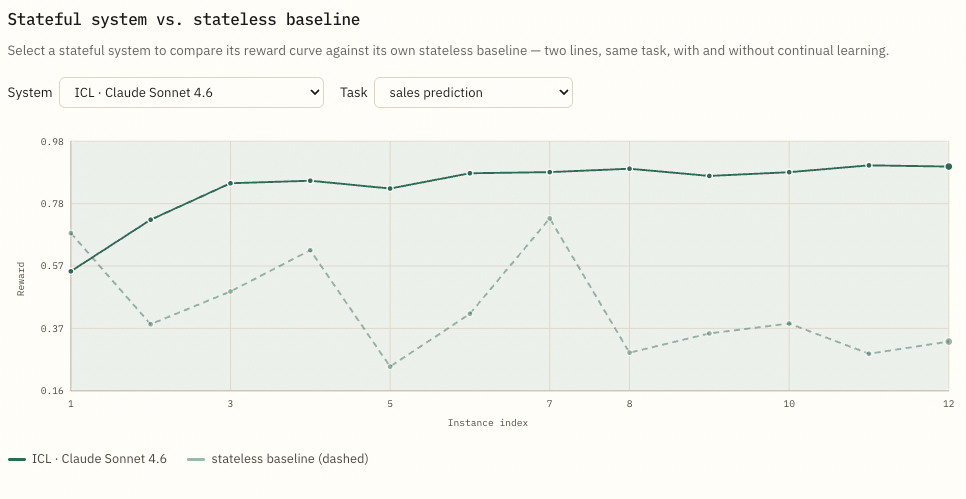
Figure: Continual Learning Bench compares a stateful system against its stateless baseline on the same task sequence. The stateful system can carry experience across instances. The stateless baseline resets between instances. The reward gap is reported as gain.
Reading the Continual Learning Bench leaderboard
The leaderboard reports reward, gain, and cost so readers can separate raw performance, improvement from experience, and runtime spend.
| Question | Metric |
| How well did the system perform? | Aggregate reward |
| How much did it benefit from prior experience? | Aggregate gain |
| How expensive was it to run? | Cost |
This makes the ranking more useful than a single score. A system can rank high on reward because the base model is strong. Another system may show higher gain because its memory setup helps it improve across the sequence.
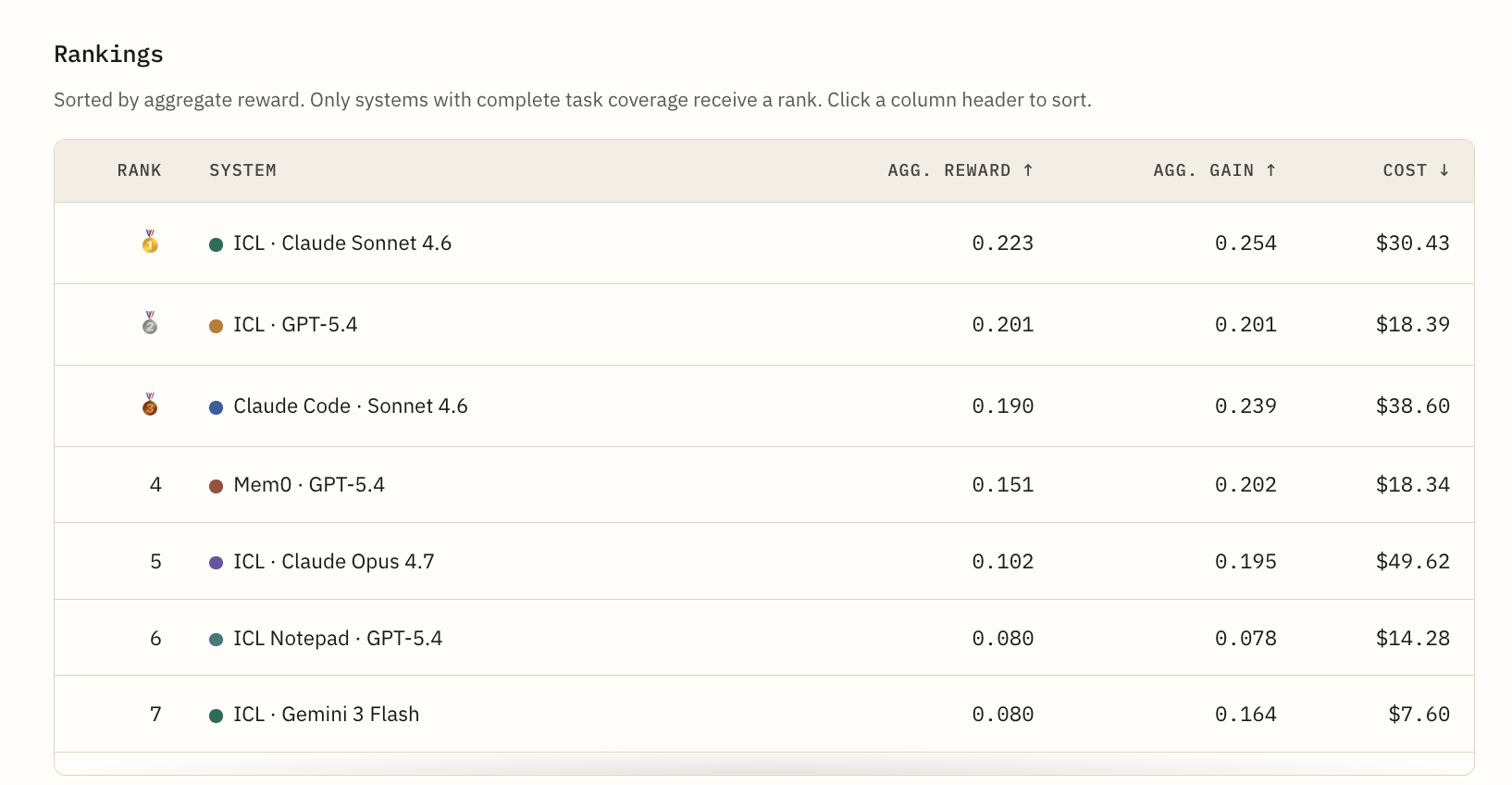
The benchmark is trying to separate raw capability, improvement from experience, and runtime cost rather than collapse them into one score.
Readers can explore the live rankings on the Continual Learning Bench leaderboard.
Memory systems are part of the system being evaluated
Continual Learning Bench evaluates the model together with the memory layer around it. In practice, that memory layer could look like chat history, a persistent notepad, retrieved summaries, a filesystem-backed memory file, or an evolving playbook.
The point is to test the full agent system. “Claude Sonnet 4.6 + ICL,” “GPT-5.4 + Notepad,” and “GPT-5.4 + Mem0” are different systems because they retain and reuse experience differently.
One memory setup may preserve useful task rules. Another may retrieve stale notes, miss the relevant prior instance, or fill the context with raw history instead of reusable knowledge.
Memory systems in Continual Learning Bench
| System | Memory strategy | Persistence |
| ICL | Full prior interaction history carried forward in the prompt, with FIFO truncation when context fills | Context window only |
| ICL Notepad | In-context learning plus a persistent string the agent can read from and write to between instances | Notepad survives across instances |
| Mem0 | Memory layer that extracts facts from agent interactions and retrieves them via semantic search | Embedded memory store persists |
| Codex | Codex CLI in a sandboxed Docker environment with session resume and a persistent markdown memory file | Filesystem-backed memory persists |
| Claude Code | Anthropic’s coding agent CLI with filesystem-backed memory through project files and conversation resume | Filesystem-backed memory persists |
| ACE | Evolving playbook built through generator, reflector, and curator steps that update the playbook across instances | Playbook persists and evolves |
The table is intentionally broad. It includes simple baselines such as full chat history, lightweight persistence through a notepad, retrieval-backed memory, filesystem-backed memory, and explicit reflection over prior instances.
Continual Learning Bench factors the result into agent, memory system, and task. The same base model can behave differently when paired with ICL, a notepad, Mem0, Codex memory, Claude Code, or an ACE playbook.
This range makes it possible to compare models and memory strategies separately, rather than treating “agent performance” as a single score.
Why the type of memory matters
A memory system has to work under real operating constraints. It has to preserve useful information, keep it readable enough to inspect, and avoid turning every future task into a long search through past transcripts.
Simple memory can be strong because it is easy to audit. A persistent notepad, markdown file, or explicit summary can be reviewed by a human, corrected when it is wrong, and traced after a failure.
More complex memory systems can support longer histories and richer retrieval, but they add overhead.
- A retrieval system can pull stale notes.
- A playbook can drift.
- A filesystem memory can preserve a bad assumption.
- A long context history can bury the useful signal under irrelevant detail.
So the question becomes which system gives the best tradeoff between learning signal, auditability, setup complexity, dependencies, and cost.
Early tasks show what agents need to learn
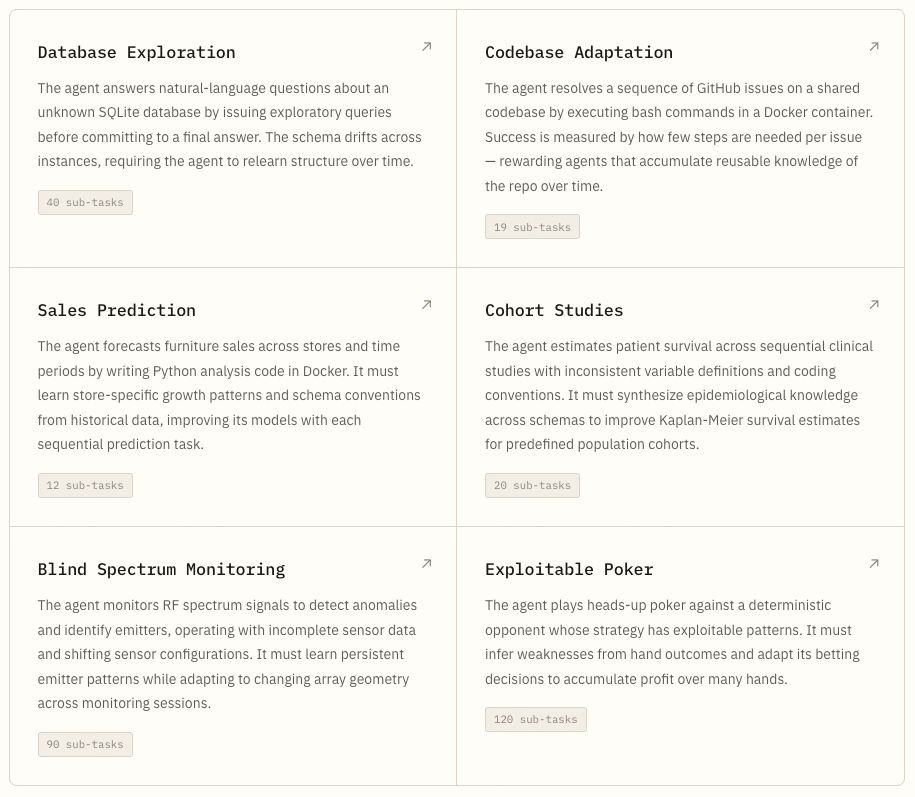
Figure: Continual Learning Bench includes task sequences across code, data analysis, epidemiology, radio engineering, and decision-making. Each task is built so prior experience can help later instances.
The early tasks are designed around different kinds of reusable structure. Some require evidence accumulation across noisy observations. Others require transfer across related codebases, schemas, stores, studies, or strategies.
This is why per-task reporting matters. Aggregate scores show broad system performance, but per-task results show where a memory system is actually helping.
Blind Spectrum Monitoring
Blind Spectrum Monitoring asks the agent to infer persistent radio-spectrum occupancy from noisy scans. A transmitter can be silent in some scans, so the current observation may not show the full environment.
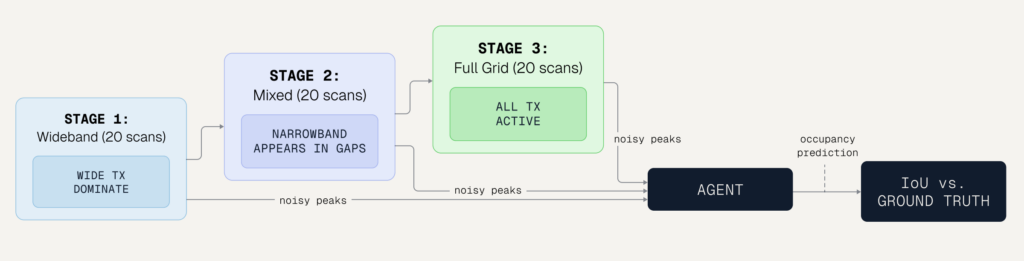
Figure: Blind Spectrum Monitoring gives the agent noisy spectrum observations across stages. The agent has to combine partial scans into an occupancy prediction instead of treating each scan as a complete view.
The memory pressure comes from partial evidence. Earlier scans may reveal transmitters or gaps that later scans do not show clearly.
The agent has to build a running map of spectrum occupancy from incomplete observations. It also has to revise that map when the band configuration changes. This makes the task a test of both accumulation and adaptation.
The per-task report on Continual Learning Bench shows how different agent and memory combinations perform on this specific task, rather than only reporting their aggregate benchmark rank.
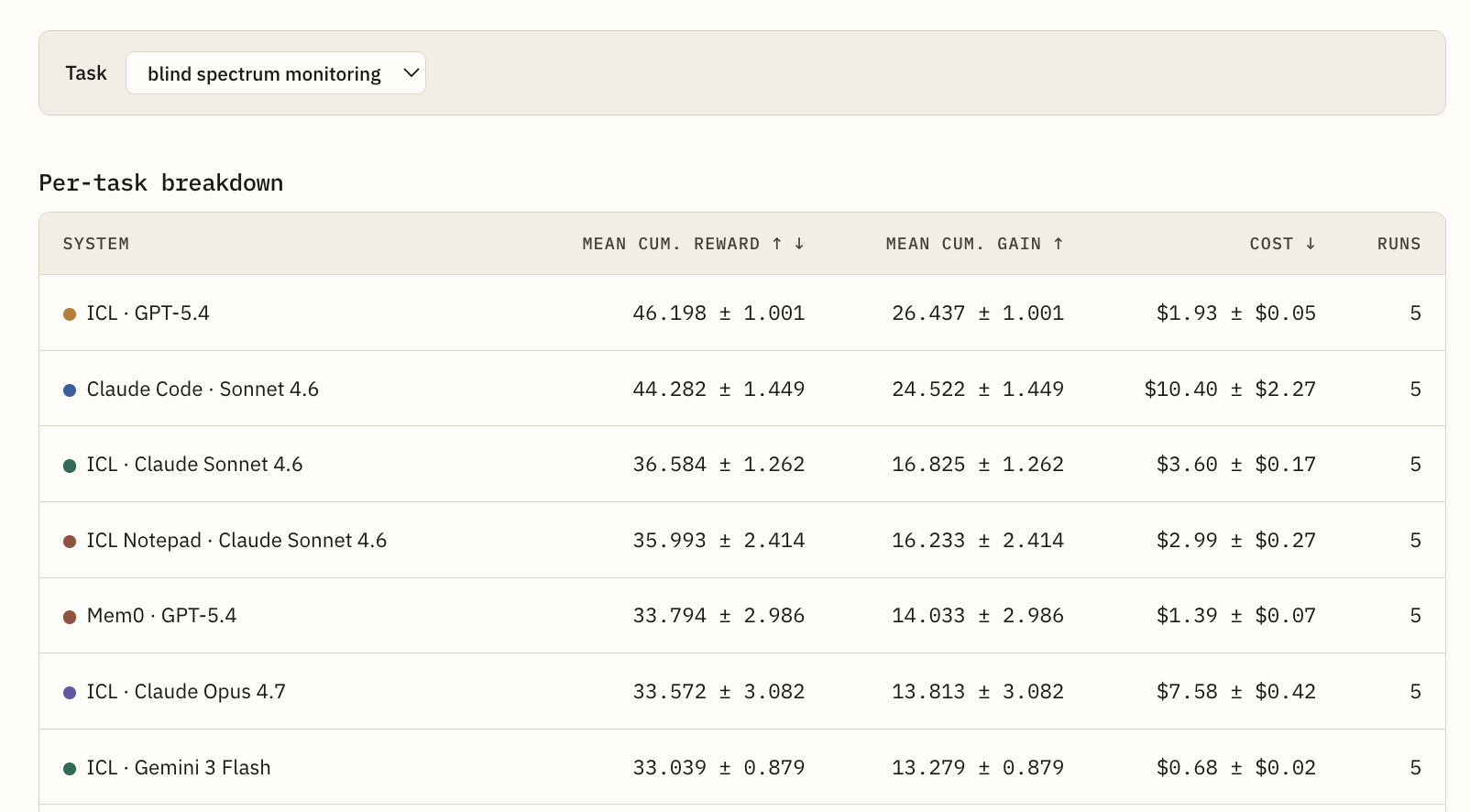
Figure: The Blind Spectrum Monitoring breakdown reports mean cumulative reward, mean cumulative gain, cost, and run count for each system. This view shows which systems benefit from memory on a task that requires evidence accumulation across noisy scans.
Sales Prediction
Sales Prediction asks the agent to forecast sales across stores and product categories. Each instance gives a limited view, but the task contains shared structure across locations, product groups, and schemas.
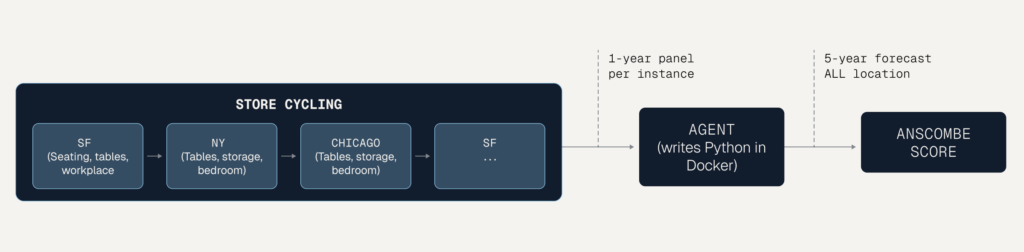
Figure: Sales Prediction cycles through store-level panels before asking for a broader forecast. The task rewards systems that preserve store, product, and schema information across instances.
A stateless system has to infer the forecasting setup again for each instance. A stateful system can reuse earlier schema, product-category, location, and growth patterns when it reaches the final forecast.
The per-task report shows whether memory helps on a transfer-heavy forecasting task, rather than only showing where the system ranks across the full benchmark.
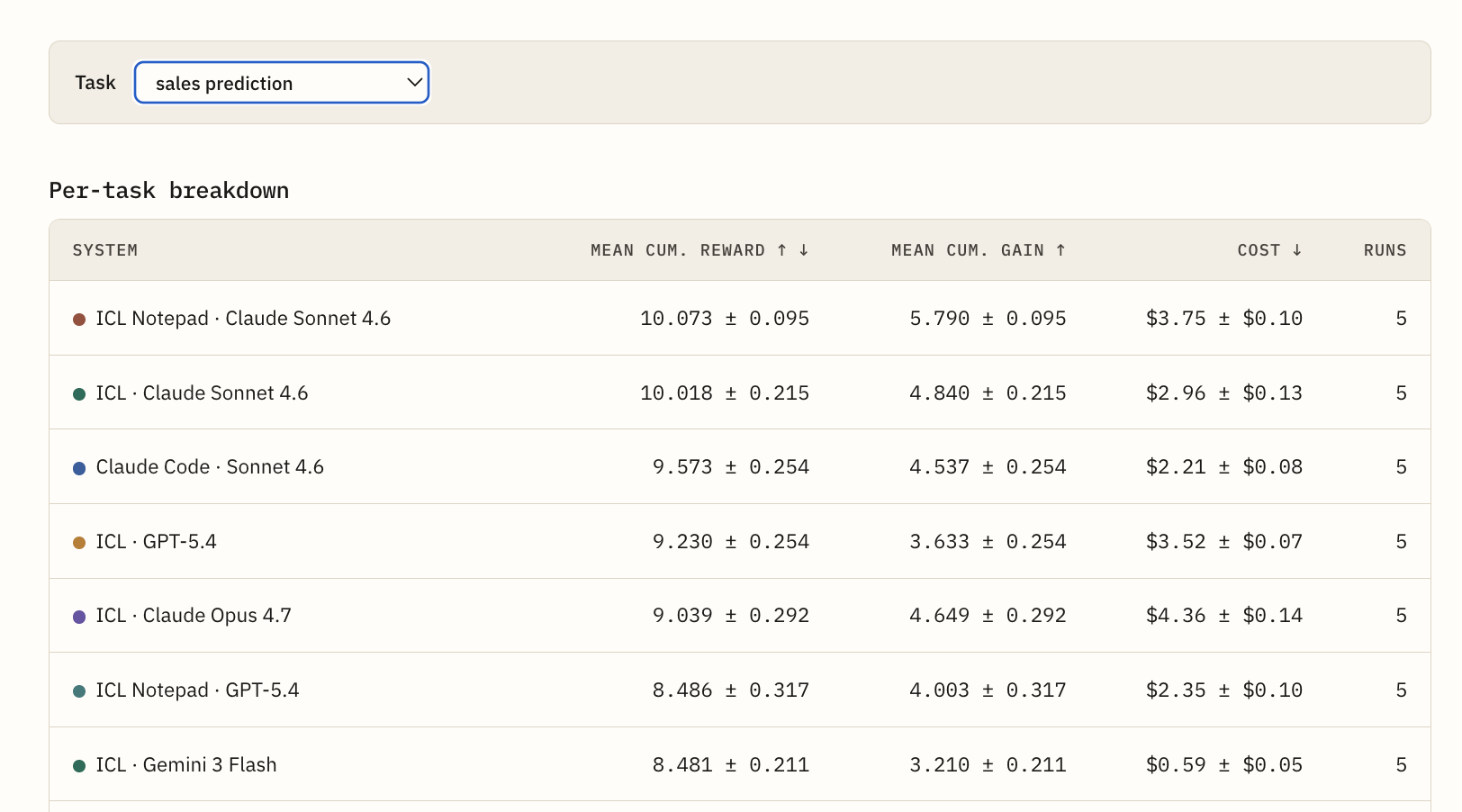
Figure: The Sales Prediction breakdown reports mean cumulative reward, mean cumulative gain, cost, and run count for each system. This view shows which systems benefit from memory on a task that rewards schema reuse and transfer across related stores and product groups.
Snorkel and SkyRL are building Continual Learning Bench with expert-validated tasks
Continual Learning Bench is led by UC Berkeley’s SkyRL lab, in collaboration with Snorkel AI and UW–Madison.
The project is led by Parth Asawa (UC Berkeley), with contributors Chris Glaze (Snorkel AI), Gabe Orlanski (UW–Madison), Benji Xu (UC Berkeley), Ramya Ramakrishnan (Snorkel AI), and Asim Biswal (UC Berkeley). Advised by Vincent Sunn Chen (Snorkel AI), Frederic Sala (UW–Madison · Snorkel AI), Matei Zaharia (UC Berkeley), and Joseph E. Gonzalez (UC Berkeley).
The project brings together benchmark infrastructure, task design, continual learning evaluation, and expert validation.
Continual Learning Bench tasks need more than length. They need related instances, realistic structure, and scoring that separates raw task performance from improvement due to prior experience.
Continual Learning Bench 1.0 is a starting point. The next step is more systems, more expert-designed task domains, and deeper error analysis of where agents learn, forget, or carry forward the wrong lesson.
For continual learning, the data layer is the task sequence, the environment, the memory signal, and the feedback loop.

Chris Glaze
Applied Research Scientist
Chris Glaze is Applied Research Scientist at Snorkel AI. He is an experienced PhD with a demonstrated history of developing novel machine learning tools and mathematical models in academia and industry. Accomplishments span data mining, experimental research, and application to digital technologies.
Recommended articles
View all articles

Benchtalks #3: We taught AI everything except how to learn
For our third Benchtalks, the series dedicated to the researchers building the measurement toolkits that frontier labs hill-climb on, Snorkel AI co-founder Vincent Sunn Chen sat down with Parth Asawa, a PhD student at UC Berkeley advised by Matei Zaharia and Joey Gonzalez. Parth leads research on continual learning and is the creator of Continual Learning Bench, developed in collaboration
June 25, 2026
•

Agentic AI evaluation: Closing the gap with better benchmarks and data
Alex Ratner, co-founder and CEO of Snorkel AI, spoke at @Scale: Systems & Reliability about one of the most underappreciated problems in AI deployment: our ability to measure agents has been outpaced — arguably for the first time in the history of the field — by our ability to build them. The talk digs into what it actually takes to close that
June 23, 2026
•
Snorkel Team

JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment
At our latest Snorkel AI Reading Group, Russell Yang (AI Engineering Fellow at Stanford Law) stopped by our San Francisco office to present JudgmentBench: Comparing Rubric and Preference Evaluation for Quality Assessment. As AI models improve at open-ended tasks, the field faces a harder problem: how to measure quality in domains where ground truth is contested. Two paradigms dominate: rubric-based
June 18, 2026
•
Snorkel Team

