
As enterprises and individuals better understand the power of machine learning tools, they often find themselves blocked by the same thing: a lack of high-quality training data. Anyone familiar with Snorkel AI knows that manual labeling presents scalability and data privacy challenges. As a researcher focused on data labeling solutions, I’m excited to introduce Alfred, an open-source tool for combining foundation models with weak supervision.
I recently presented my project to Snorkel AI researchers. You can watch the entire talk (embedded below), but I have summarized the main points here.
What is Alfred?
Alfred is a python library designed to streamline the use of foundation models (FMs) to make it easier for data scientists and researchers to use them to label data at scale.
Traditional data annotation methods often involve time-consuming and costly manual processes. Using FMs to label data directly can create inaccurate results. Alfred aims to address these limitations.
To do this, Alfred allows users to define labeling rules in plain language as prompts to FMs, such as Llama 3.1, GPT-4, or CLIP. Then it denoises and synergizes the models’ responses through weak supervision.
Alfred was initially designed with academic researchers in mind, offering a tool to streamline data science projects in academic settings. While its current iteration may not fully address the complex needs of enterprise data teams, Alfred incorporates fundamental principles similar to those found in the Snorkel Flow AI data development platform, which is enterprise-ready.
How Alfred works
Alfred enables users—even relatively non-technical ones—to multiply their labeling impact. By transforming rigid code-based labeling functions into flexible natural language prompts, Alfred allows non-experts to leverage the expertise of pre-trained foundation models, making the annotation process more accessible.
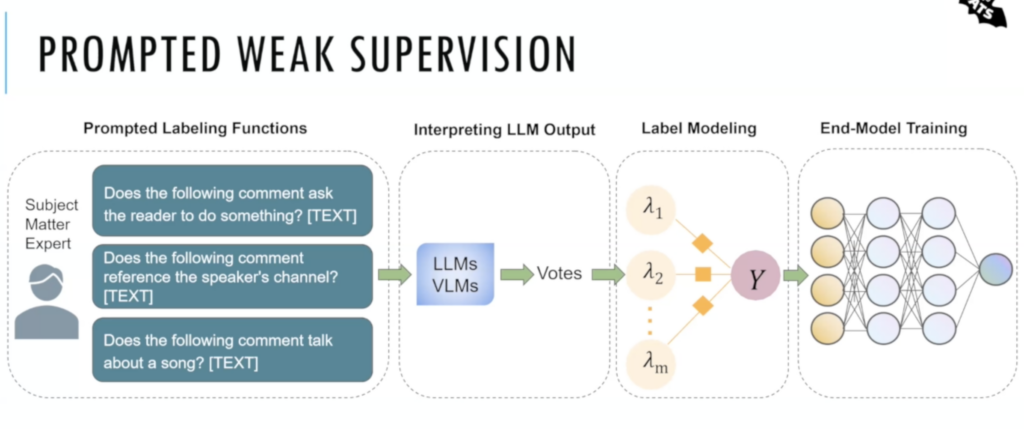
Here’s what that process looks like:
- Heuristics development: Users create informative heuristics as prompt templates, which are then processed to generate typed query objects. This step allows for the translation of domain expertise into a format that foundation models can understand and act upon.
- Query and response processing: Alfred sends the prepared prompts to the user’s chosen FM, whether it’s hosted locally, on a server, in the cloud, or accessed through APIs like GPT-4 or Claude. The system then interprets the model’s responses, converting them into numerical values suitable for subsequent voting mechanisms.
- Probabilistic labeling: In this final stage, Alfred applies the user-selected label models (such as FlyingSquid, Noisy Partial Label Model, or other algorithms) to transform the aggregated, potentially noisy votes into high-quality, probabilistic labels.
With Alfred, users layer heuristics on top of each other. They can write labeling prompts that address different aspects of their target records. They can even use different models. From our empirical studies, we’ve found that using multiple models for the same heuristics improves accuracy by offsetting individual model biases.
Key features of Alfred
In addition to providing an easy-to-use wrapper, my colleagues at Brown and I have built several useful features into Alfred, such as:
- Optimized Inference Throughput: Alfred packages inference requests together, achieving 2-3x faster processing compared to standard methods. This minimizes the number of queries sent to the foundation model, significantly speeding up data labeling.
- Flexible Model Support: Alfred works with a wide range of language and multi-modal foundation models. It supports cloud-based API services from companies like Anthropic, OpenAI, and Google, and self-hosted open-source models. This flexibility lets users choose the best option for their needs.
- User-Friendly Development: Alfred offers a consistent experience whether users are working with local models, Alfred-hosted servers, or third-party APIs. This unified interface allows for rapid iteration and refinement, regardless of where the AI models are running. Users enjoy the same smooth workflow whether the model is on their laptop or a remote cluster.
- Easy-to-Use Templates: The system includes tools for quickly creating, testing, and improving labeling rules. These templates work consistently across all supported model types, allowing users to efficiently develop and refine their approach.
- Smart Label Aggregation: Alfred includes several methods for combining labels from different sources, helping to produce more accurate final labels for training data.
Alfred aims to integrate more automation in future updates, utilizing language models to further streamline template creation and other stages of the workflow.
Alfred in action: sentiment analysis and image classification
In my presentation, I gave two examples of how Alfred can help in the real world.
In the first, we looked at an application to classify the sentiment of financial newss headlines. Very quickly, we noticed headlines that mentioned price targets going up or down. This could serve as a good heuristic. Traditionally, a user might use a regular expression to capture this signal, but regex would miss headlines that used synonyms or even where the writer ordered their words differently.
With Alfred, we can skip the regex and prompt a large language model (LLM). We can create a template that presents the headline to the LLM and asks it which sentiment category the headline falls into—neutral, positive, or negative.
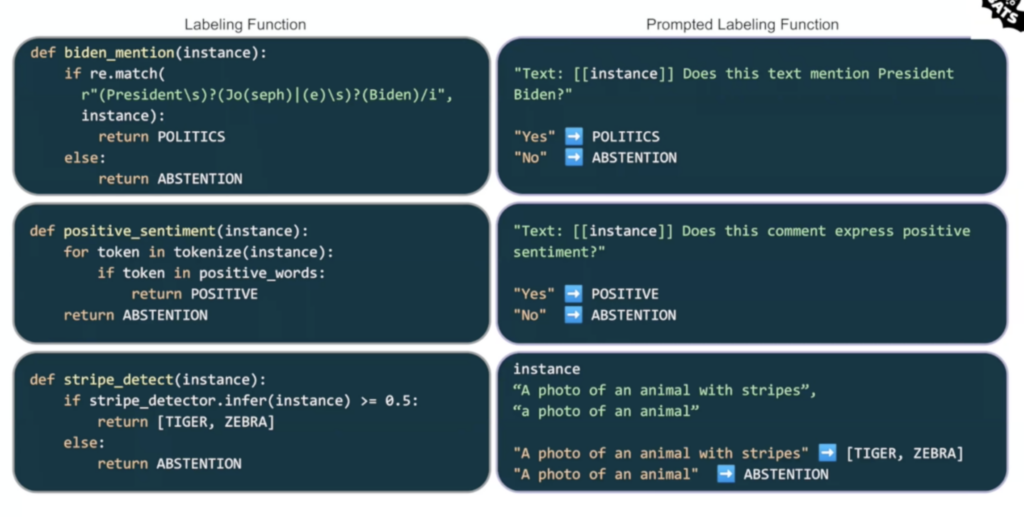
In the second, we demonstrated image Data Annotation. For tasks involving image data, Alfred supports contrastive models like CLIP and autoregressive models like BLIP to simplify attribute-based classification. Here, again, our templates help us efficiently present the information to the model and process a response.
Common challenges addressed by Alfred
One of the significant challenges in data annotation is managing the complexity and computational demands of foundation models. Alfred addresses these through:
- Dynamic batching: By automatically grouping queries of similar lengths, Alfred reduces the impact of useless padding, increasing throughput by up to 2.9x.
- Caching mechanisms: The system caches query and response data to reduce redundant model queries, enhancing efficiency.
Alfred: foundation models + weak supervision
Our Alfred package represents a significant leap forward in open-source programmatic weak supervision. It offers a flexible, efficient, and user-friendly system that enhances data annotation and model training. We believe that Alfred will serve as a cornerstone for future machine learning applications—especially for academic projects— driving innovation and simplifying complex data workflows.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!

Peilin Yu
PhD Candidate
Peilin Yu is a Ph.D. candidate in the Computer Science Department at Brown University, where he is advised by Professor Stephen H. Bach. He focuses on innovative methods for addressing weak supervision challenges and harnessing foundation models to improve weak supervision practices. His work has been presented at conferences such as ICLR, ACL, AISTATS, and IEEE Big Data.
Recommended articles
View all articles

Claude Opus 5: Performance and Error Analysis on Frontier Coding Tasks
Anthropic’s Claude Opus 5 recently debuted as the second model overall on the current Senior SWE-bench leaderboard, behind Fable 5. It also achieves the highest score of any evaluated model on the benchmark’s Bug & Performance Investigation category, reinforcing the rapid progress frontier coding models continue to make on increasingly realistic software engineering tasks. Just as notable, Opus 5 reaches
July 27, 2026
•

Senior SWE-Bench: Evaluating Coding Agents Like Senior Engineers
At our latest Snorkel AI Reading Group, Henry Ehrenberg presented Senior SWE-Bench, an open-source, Harbor-compatible benchmark for evaluating coding agents on realistic, senior-level software engineering work. Its 100 tasks, with 50 public and 50 kept private to mitigate contamination, are sourced from real pull requests across 12 production repositories and cover complex features, migrations, bugs, and performance issues. Senior SWE-Bench
July 16, 2026
•
Snorkel Team

Grok 4.5 Testing Results: How SpaceXAI’s New Model Performs on Real Professional Work
We’ve evaluated Grok 4.5 on Snorkel’s GDPval+ dataset, Snorkel’s expert-created dataset of professional workplace reasoning tasks from across the economy. To compare performance against other frontier models, we ran the evaluation alongside GPT 5.5 and Claude Opus 4.8. Overall, Grok 4.5 demonstrated the strongest overall performance. Dataset GDPval+ is part of the Snorkel Data Series (SDS), Snorkel’s portfolio of expert-curated
July 8, 2026
•

