Join our inaugural Reading Group in San Francisco on April 29. Register now
Vision language models: how LLMs boost image classification
Vision language models demonstrate impressive off-the-shelf image classification capabilities. Still, generalist models like CLIP struggle to differentiate between subcategories with significant overlap, such as distinguishing cat breeds. I and my colleagues at Brown University set out to better understand how these models work and find ways to use large language models to improve vision language model performance—with notable results.
I recently presented two research papers, “Follow-Up Differential Descriptions: Language Models Resolve Ambiguities for Image Classification” and “If CLIP Could Talk: Understanding Vision-Language Model Representations Through Their Preferred Concept Descriptions” to an audience of Snorkel AI researchers and engineers. You can watch the entire presentation (embedded below), but I have summarized the main points here.
How do contrastive vision language models work?
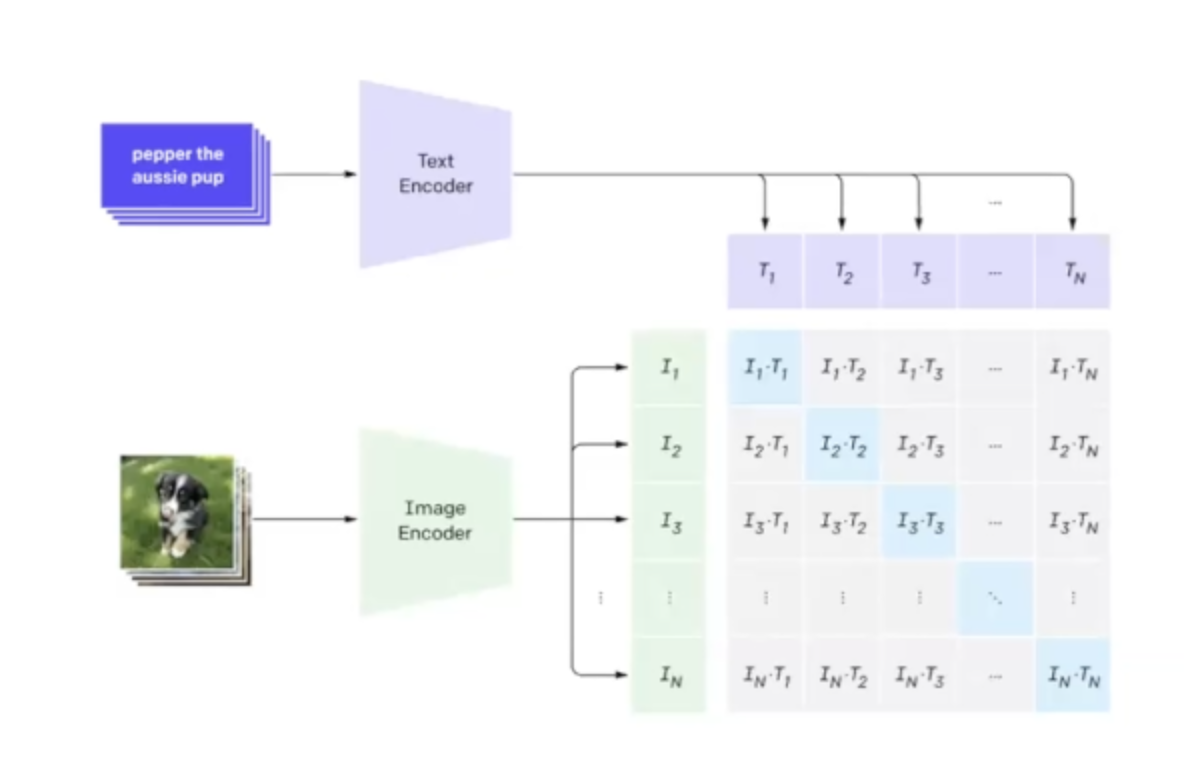
Contrastive vision language models (VLMs) pair a text encoder with an image encoder. The encoders process each input of their respective media to generate an embedding vector. Researchers then train these models on images paired with their descriptions. This enables the model to understand the relationship between the text and image, allowing it to interpret visual concepts.
VLMs like CLIP (Contrastive Language-Impage Pre-training) serve as a great starting point for building image classification models, but they can sometimes use help; research has shown that querying the model with a description of a target class rather than just its label improves accuracy—though not all descriptions work equally well.
Different VLMs prioritize different attributes. For instance, when analyzing a dataset of bird species, one VLM might prioritize the size attribute, while another might prioritize the habitat attribute.
Automatically enhancing VLM prompts
Our Follow-Up Differential Descriptions (FuDD) study aimed to address a key challenge in VLM performance: distinguishing between classes of images easily confused for each other. We used a zero-shot, training-free method to improve accuracy by detecting ambiguous classes and using a large language model (LLM) to generate detailed descriptions crafted to help resolve ambiguities.
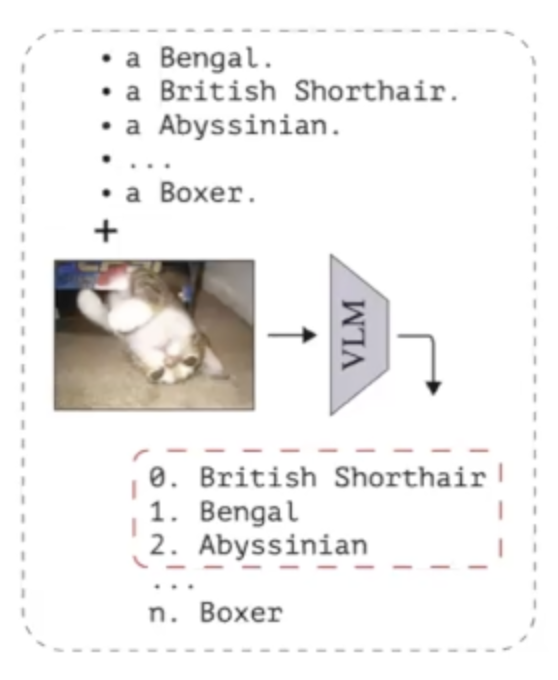
The process begins by presenting the VLM with images and text indicating the potential classes those images could belong to. By measuring the distance between the images and each of the classes, we can determine which classes are most similar to each other for this image (i.e., are ambiguous classes).
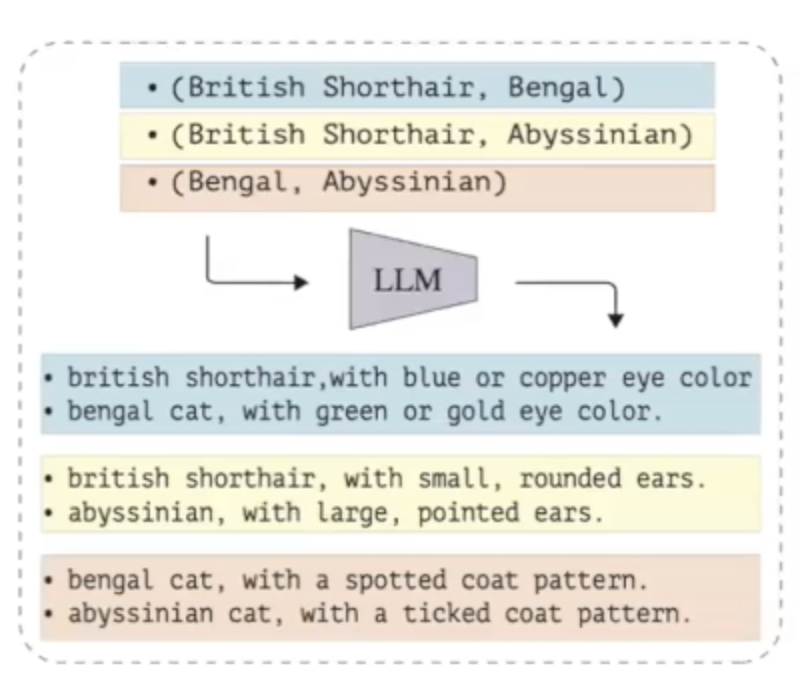
Then, we use the LLM’s generative AI capabilities to generate the information needed to resolve the ambiguity. For example, to help the VLM distinguish between images of a ‘sparrow’ and a ‘cuckoo’, we would prompt the LLM to generate descriptions highlighting differences between these bird species.
We use these contrastive descriptions to help guide CLIP to make the correct prediction for the image. We ran extensive experiments on twelve fine-grained image classification datasets. The experiments tested two versions of CLIP and used GPT-3.5 to generate descriptions. We also tested the impact of contrastive prompts for different levels of ambiguity, ranging from using contrastive prompts only for the five most ambiguous classes to all classes in the dataset.
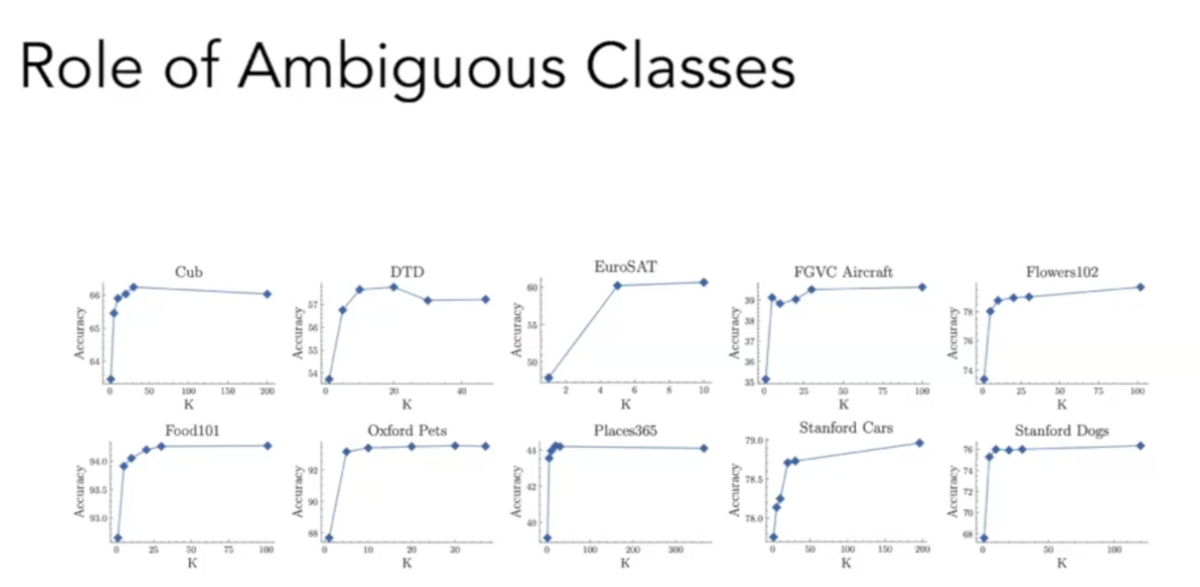
The results were encouraging: we observed that providing differential information about ambiguous classes significantly improved classification performance—and that we need not include contrastive descriptions for all classes. While including contrastive descriptions for all classes yielded the best performance, we achieved most of the performance boost by using contrastive prompts just for the five most ambiguous classes.
Understanding VLM contours
In our Extract and Explore (EX2) study, we used reinforcement learning to train an LLM to generate class descriptions more aligned with the preferences of specific VLMs.
The goal of this study was twofold:
- To better understand how different VLMs might represent the same concepts.
- To demonstrate an approach for training LLMs to assist image labeling tasks better.
We asked an LLM to describe a particular class, for instance, “lemur” or “sparrow.” Then, we then took the VLM’s embeddings for these descriptions and calculated the cosine similarity between them and the embeddings produced by our VLM for images of the given class. We used this cosine similarity as a reward metric to train the LLM to create descriptions more aligned with the VLM’s perspective.
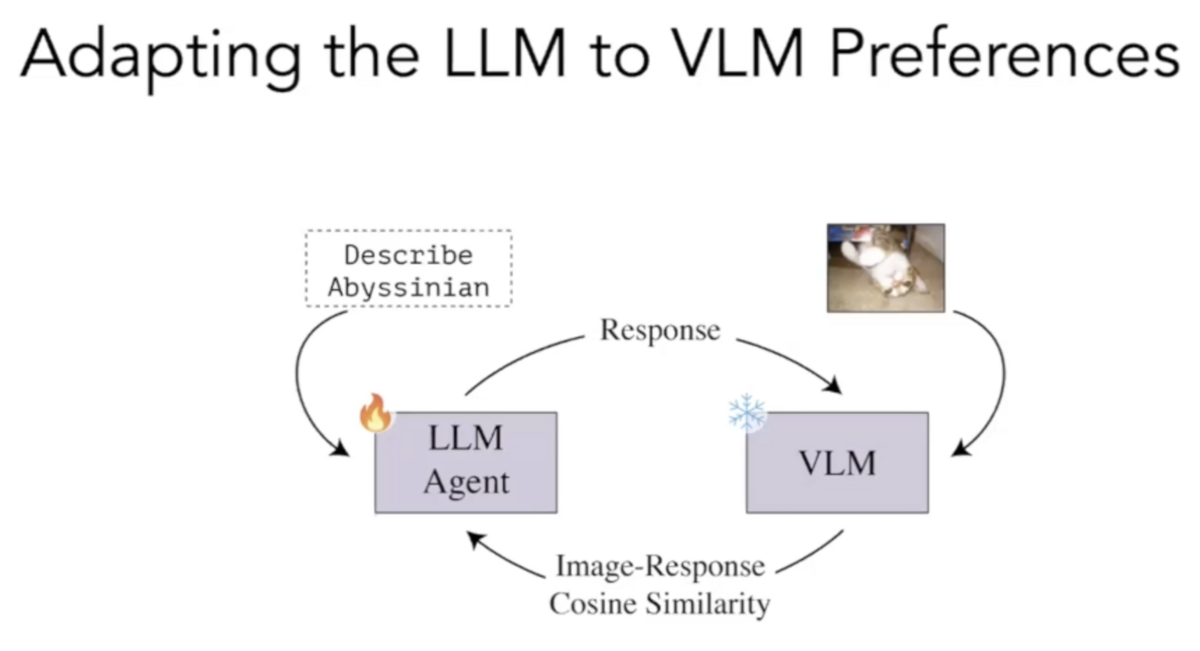
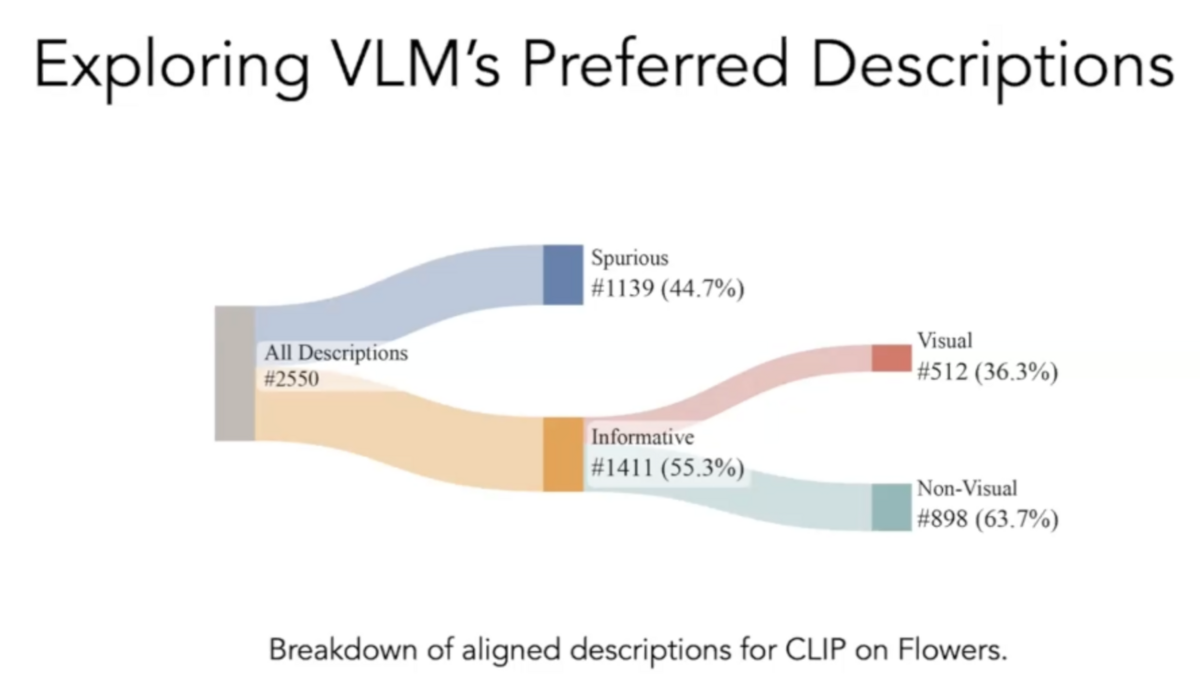
Using EX2, we made several observations about how VLMs represent different concepts. We found that different VLMs prioritize different attributes to represent similar concepts. Some VLMs might focus on the size of an object, while others might focus on its habitat.
We also found that spurious descriptions and non-visual information significantly influence the representations in VLMs. Though non-intuitive, we found instances where VLMs were more responsive to descriptions that described where a bird lived rather than what the bird looked like.
A better understanding for better VLMs
Understanding and improving vision language models is a critical endeavor in machine learning research. These two studies have shown promising results in enhancing the performance and understanding of these models.
Our Follow-Up Differential Definitions study demonstrated how we can resolve ambiguities in VLMs to improve image classification accuracy. Our EX2 study revealed how VLMs represent different concepts and the influence of spurious descriptions and non-visual information on these representations.
These studies contribute to our understanding of VLMs and open new avenues for further research and potential applications. We look forward to continuing to explore these fascinating models and to furthering our knowledge in this exciting field.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.

Reza Esfandiarpoor
Reza Esfandiarpoor is a fifth-year Ph.D. candidate in the Department of Computer Science at Brown University, advised by Stephen Bach. His research interests concern machine learning systems with multiple large pre-trained models and the new challenges and opportunities that interactions between these models provide.