Search result for:
Customer story
Google labels millions of data points in minutes with Snorkel AI
Impact
6
Months of hand labeling replaced in 30 minutes
52%
Performance improvement
6.5M
Programmatically labeled data points
Google used Snorkel’s technology to leverage existing knowledge resources from across the organization to reduce development time and cost by an order of magnitude. The team built content classification models with Snorkel that achieved an average performance improvement of 52%—without requiring tens of thousands of hand-labeled examples.
Agile AI development at industrial scale
Almost every Google product we use runs on AI, from Google Search and Ads to YouTube, Android, Chrome, and Google Assistant. However, Google’s AI and engineering teams faced substantial challenges when scaling topic and product classifiers. Google commonly uses these classifiers for social media monitoring, content and product recommendations, product analytics, and more.
Challenge
The Google team managed hundreds of topic and product classifiers, each trained with its own dataset. The team had to manually label training datasets to create a new classifier. They struggled with adapting existing classifiers to keep up with changing business decisions. For example, the team managed a classifier that detected references to products in a specific category of interest. When the category was expanded to include additional types of accessories and parts, the team had to discard or relabel all previously negative class labels.
Google spent months and considerable resources manually labeling and relabeling thousands of data points for each classifier. The team was motivated to find faster and more agile ways to label data, develop new classifiers, and adapt existing classifiers.
Solution
The Snorkel team collaborated with Google to apply Snorkel’s programmatic labeling and weak supervision framework to speed up development of two types of content classifiers (topic and product). The project was coined Snorkel DryBell, with the goal of achieving the accuracy attained by hand-labeling in a fraction of the time.
A developer spent a short amount of time writing labeling functions that expressed basic heuristics and reused organizational resources, such as existing Google models.
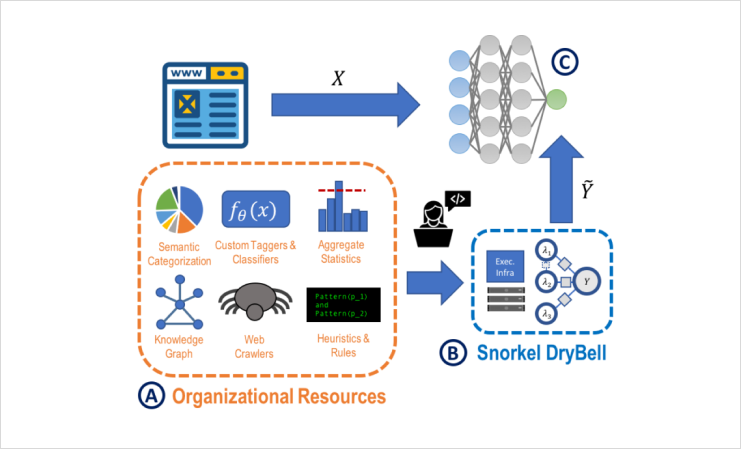
Labeling functions for the topic classifier:
- URL-based: Heuristics based on the linked URL.
- NER tagger-based: Heuristics over entities tagged within the content, using custom-named entity recognition (NER) models maintained internally at Google.
- Topic model-based: Heuristics based on a topic model maintained internally at Google.
Labeling functions for the product classifier:
- Keyword-based: Keywords in the content indicated either products and accessories in the category of interest or other accessories not of interest.
- Knowledge graph-based: Queried Google’s Knowledge Graph for translations of keywords to increase classifier coverage across multiple languages.
- Model-based: Used the semantic topic model to identify content unrelated to the products within the category of interest.
Results
With Snorkel, the Google team built classifiers of comparable quality to ones trained with tens of thousands of hand-labeled examples. From there, they converted non-servable organizational resources to servable models for a 52% average performance improvement. With Snorkel’s labeling functions, Google labeled 684K data points for a topic classification model in a few minutes and 6.5MM data points for a product classification model in 30 minutes.
This work was published in SIGMOD in 2019. Snorkel’s approach has fueled many use cases at Google, including carrying out data curation (e.g., weak supervision and label propagation) and model training (e.g., forms of multimodal learning) across these different data modalities (published in VLDB in 2020).
Ready to get started?
Take the next step and see how you can accelerate AI development by 100x.
