We’re thrilled to introduce the latest release of our data-centric AI development platform, Snorkel Flow. This release is packed with an array of new features and enhancements that we’re excited to share with you today.
At the forefront of this Snorkel Flow release are new capabilities for adapting foundation models and large language models for enterprise use. These capabilities allow enterprises to fine-tune foundation models for complex, domain-specific tasks or distill them into smaller, simpler models that can be deployed within existing cost and governance constraints. These new capabilities are now available in private beta.
We’ll go deeper into the foundation model capabilities below, but before we dive in, here’s a quick TL;DR of what’s in this latest release of Snorkel Flow:
- Data-centric Foundation Model Development capabilities now available in beta.
- Programmatic labeling with support for complex tasks and data types.
- Rapid, model-guided iteration with New Studio for all core ML tasks.
If you want to see Snorkel Flow in action, sign up for a demo.
Leveraging foundation models for enterprise AI
Despite the break-neck progress on the foundation model front with ChatGPT, BARD, GPT-4, LLaMA, and more, the enterprise adoption for predictive AI use cases, e.g. fraud detection, patient risk assessment, document processing automation, and more, remains slow. Enterprises face—and will continue to face—two key challenges around using foundation models: adaptation to complex, domain-specific tasks and deployment within governance and cost constraints.
Snorkel introduced Data-centric Foundation Model Development capabilities in November 2022 for enterprises to overcome these challenges and leverage foundation models in production. With the Spring 2022 release, we are making these available to all customers in beta.
Here’s an overview of the Data-centric Foundation Model Development capabilities:
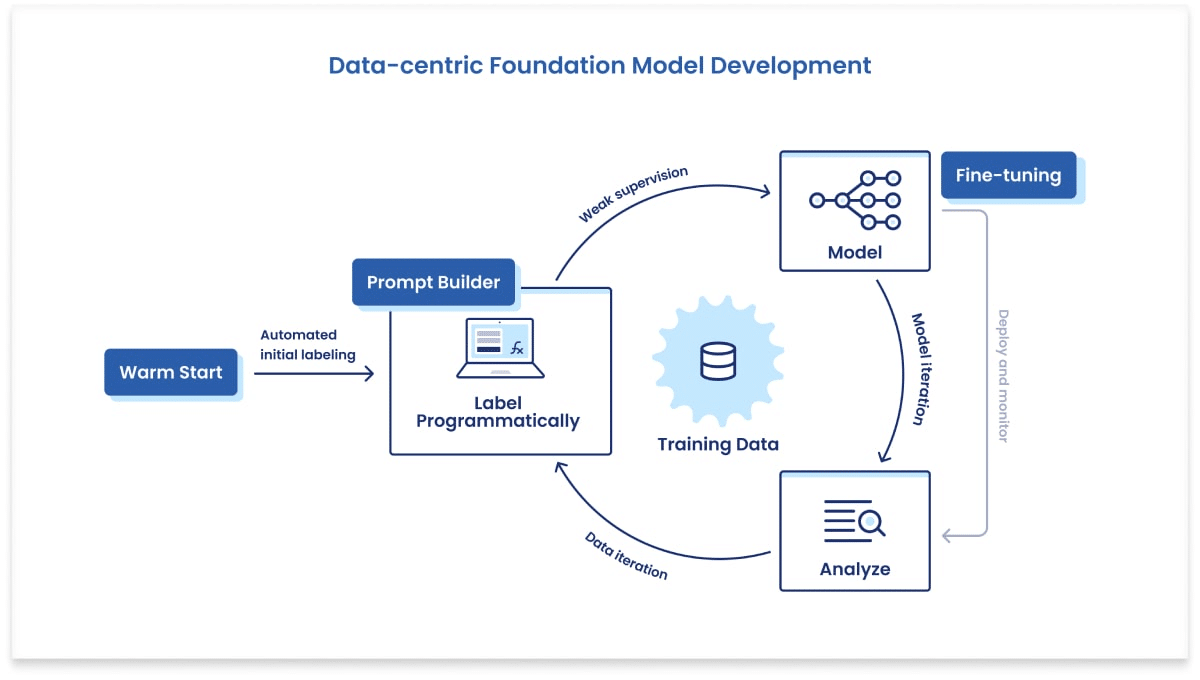
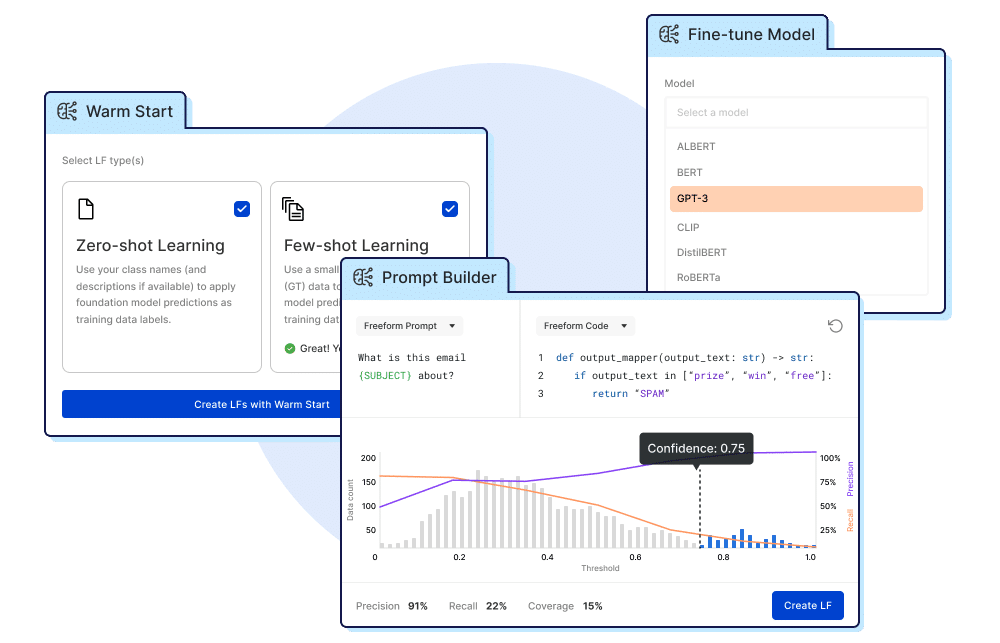
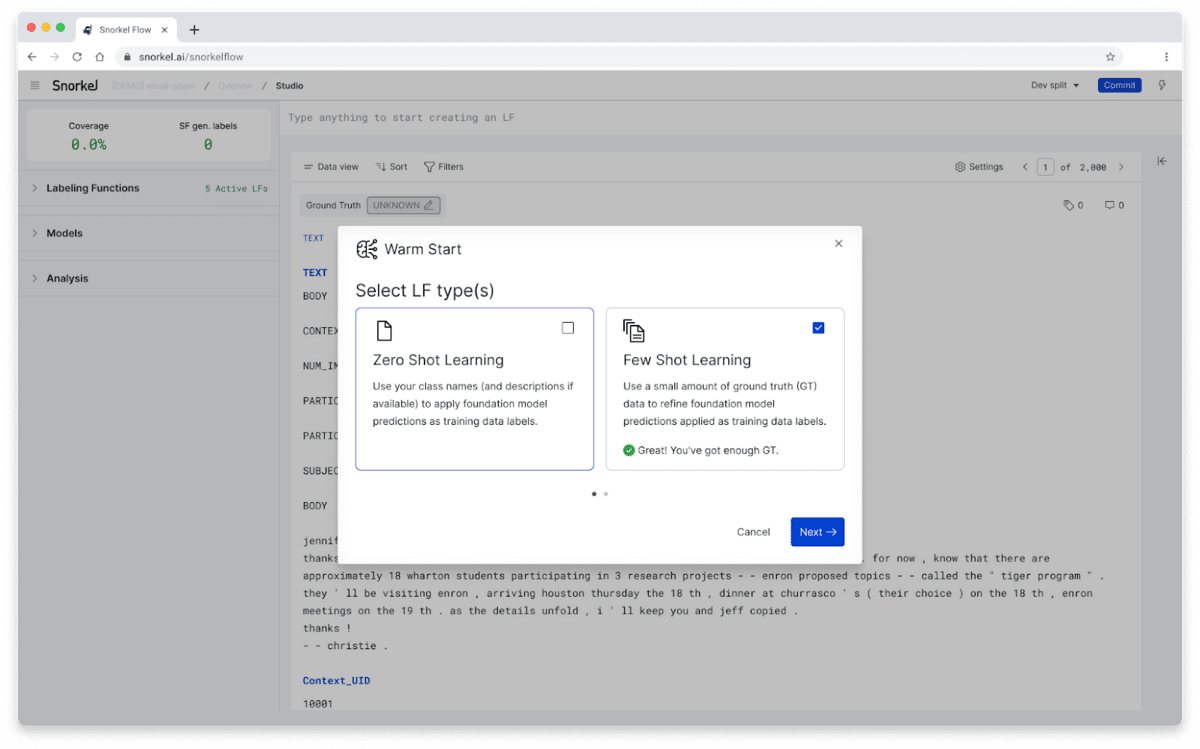
Warm Start: Auto-label training data using the power of FMs + state-of-the-art zero- or few-shot learning techniques during onboarding, helping get to a powerful baseline “first pass” with minimal human effort.
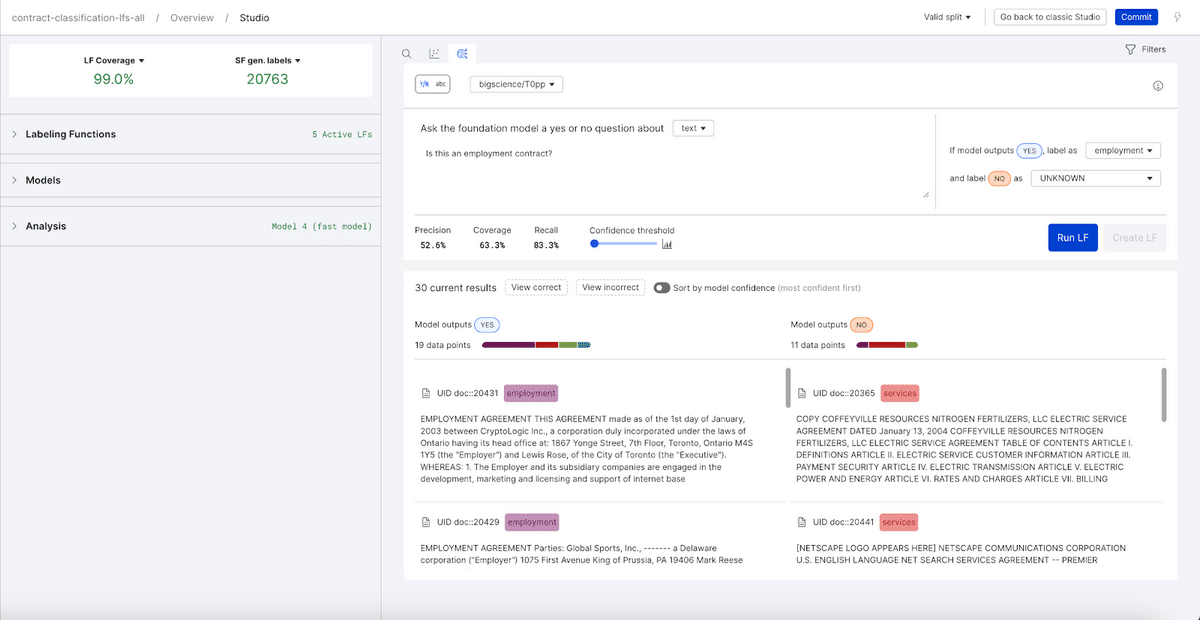
Prompt LF Builder: Explore and label data through natural language prompts using FM knowledge and translate it into labeling functions for your weakly supervised learning use cases.
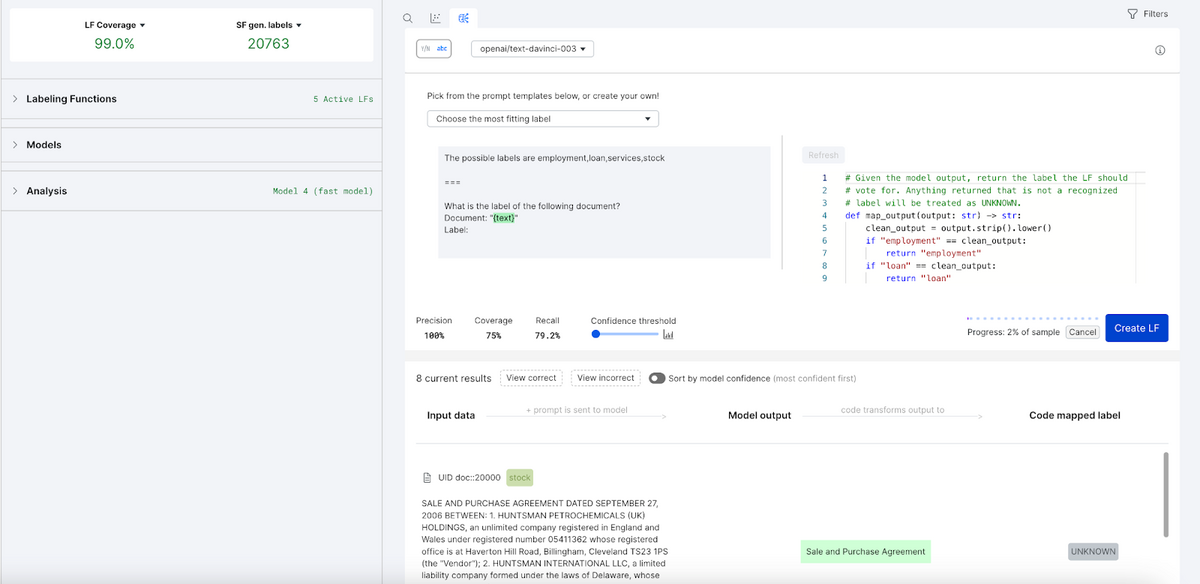
Fine-tuning: Use programmatically and/or manually labeled training data to fine-tune production models of a preferred size, ranging from small easy-to-deploy models, like RoBERTa, to large FMs, like GPT-3.
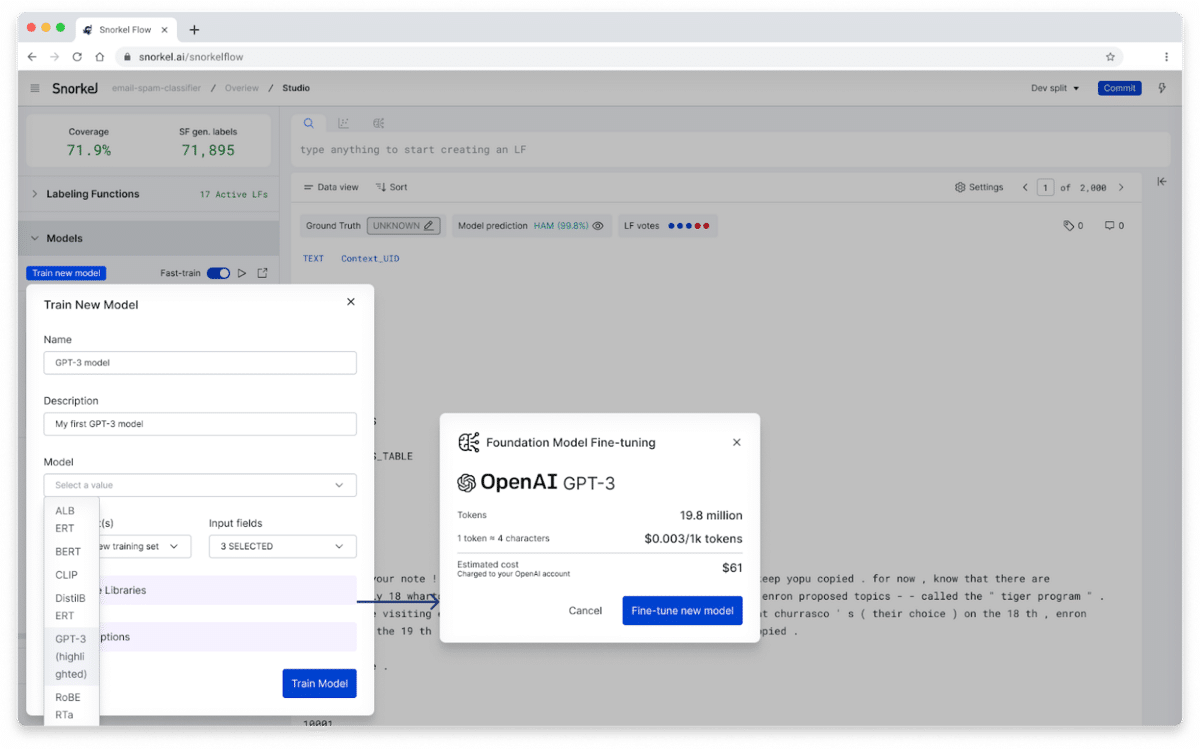
NER made easy with sequence tagging
We’ve made significant performance improvements (up to 20x faster) for data-centric exploration and labeling when working with sequence tagging tasks. We’ve also upgraded the multi-highlighting experience to help you quickly find and correct nuanced labeling and modeling errors over spans.
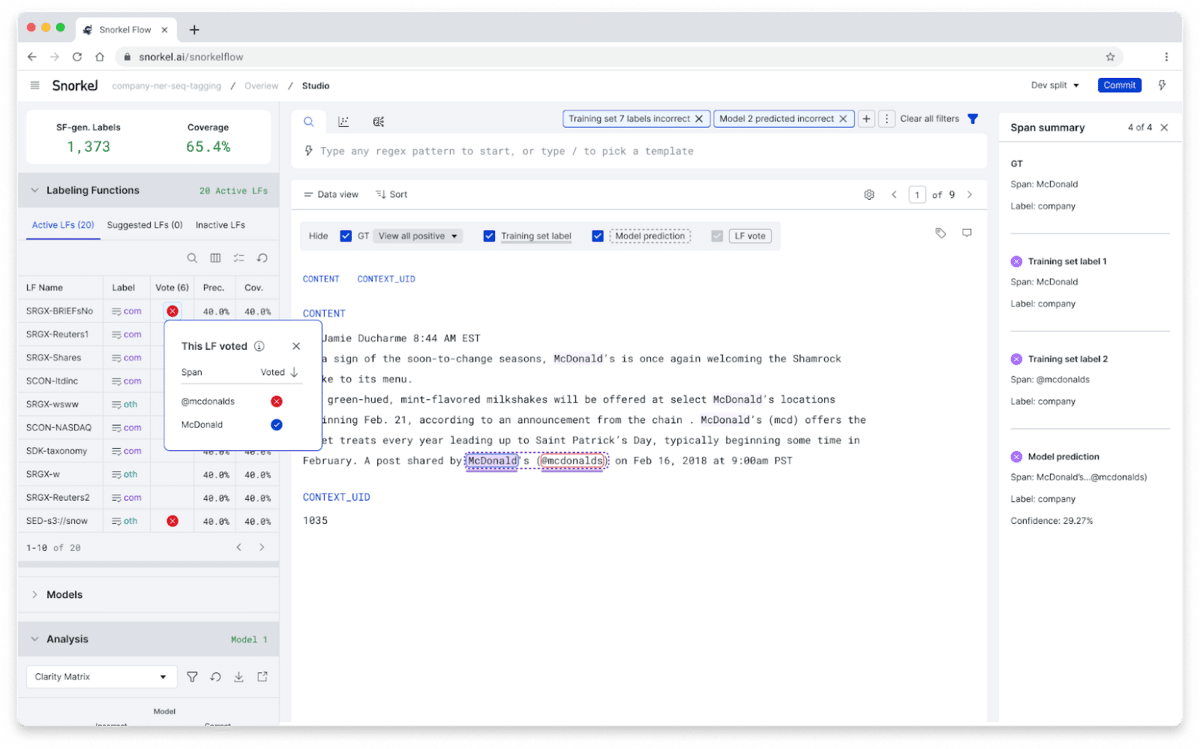
Improved PDF extraction
We’ve added native OCR Integration as well as improved support for multi-line span rendering and whitespace clean-up in the PDF data viewer, you’ll enjoy smoother document-level interactions. Native integrations with Tesseract and Azure Form Recognizer for OCR processing unlock non-native PDF use cases without the need to pre-process data through an external OCR service.
Enhance your experience working with PDFs using foundation models. Also included in this latest release is the highly anticipated Notebook-based prompt LFs for PDFs, which allows you to explore and label your data using natural language prompts in a notebook environment.
Upload your own embeddings
Our new arbitrary embedding operator enables users to import their own embedding data into the platform seamlessly. Now you can import your own embedding directly into SF and once imported, the data can be visualized using the cluster view for an intuitive understanding of your custom embeddings. This new ability allows teams to make use of advanced multilingual capabilities within a unified platform.
Enhanced new studio experience
Snorkel Flow now supports all ML tasks through a single interface via our new Snorkel Flow Studio experience. Using the new Studio experience, you can now leverage new features like the labeling function (LF) composer toolbar and supported templates, searches, in-app model training, and easily accessible analysis for all of your common ML tasks such as text and PDF classification tasks and utterance classification.
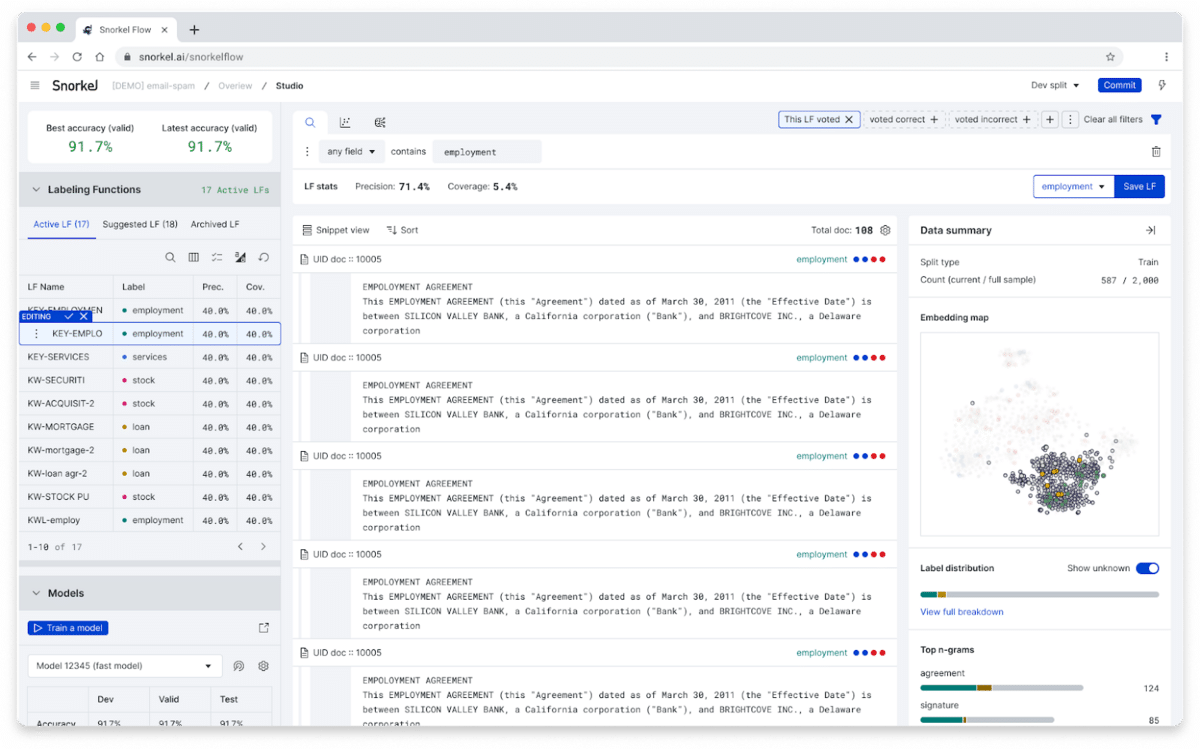
Autosuggest labeling function improvements
We’ve improved the Autosuggest feature for sequence tagging and added new suggestion strategies based on embeddings and TF-IDF keyword count for the text classification task type.
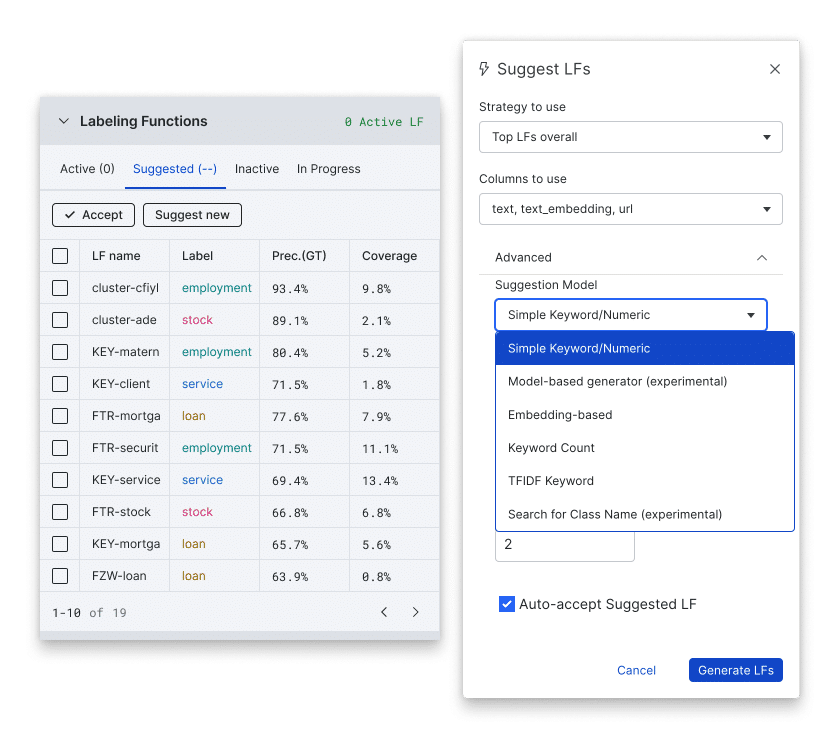
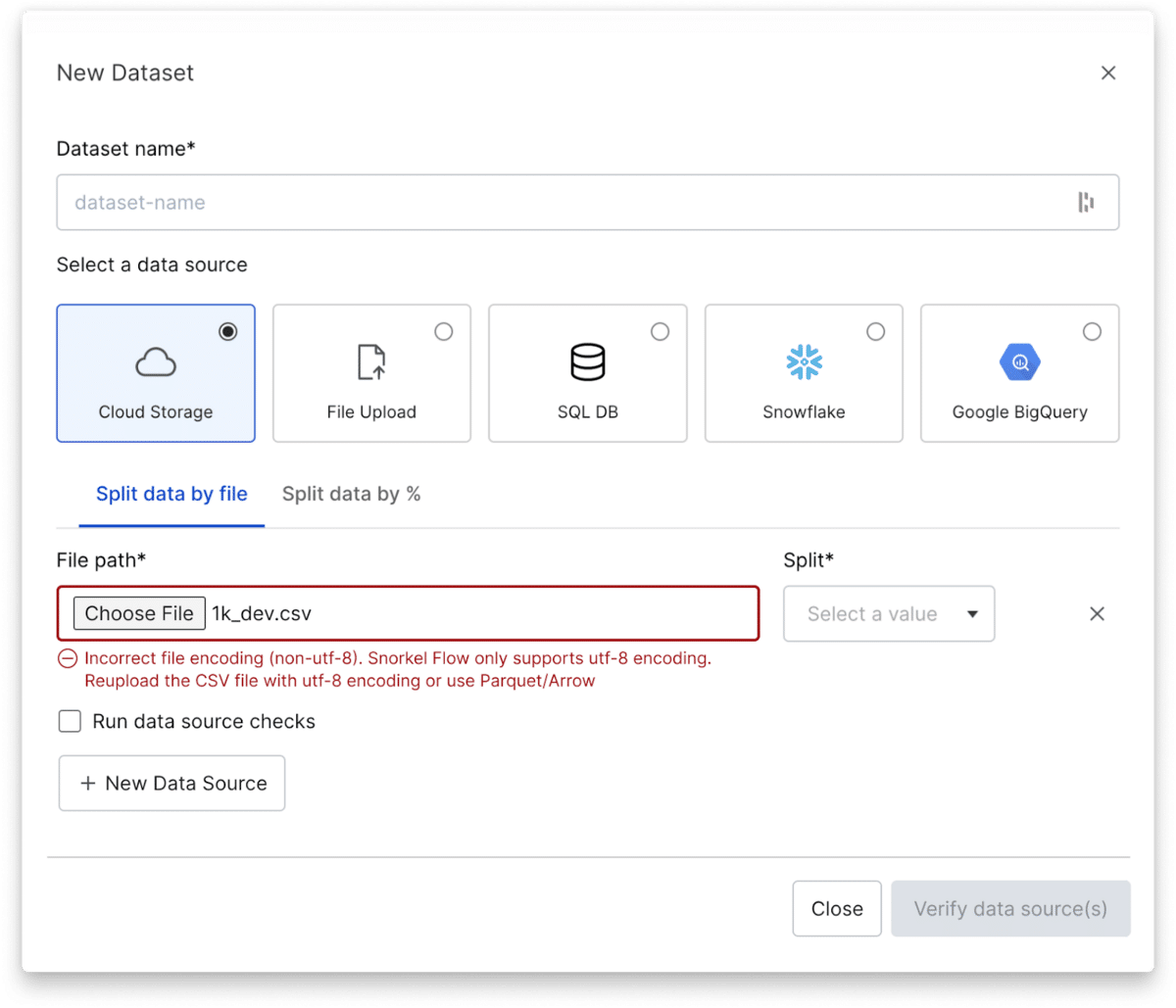
Self-serve guardrails for data upload
We know that uploading data can be a challenging and time-consuming process, which is why we’ve worked hard to make it as easy and streamlined as possible.
With the latest release of Snorkel Flow R1, we’ve introduced improved documentation for uploading data, including UX guardrails and remediation steps to help you avoid common errors, such as files that are too large or have the wrong encoding. We’ve also added warnings to alert you when something is amiss, so you can take immediate action and keep your workflow running smoothly.
New advanced SDK tools
In addition to the foundation model suite, we’ve also added new advanced SDK functions that enable you to leverage LLMs to generate regex syntax for labeling function development and code snippets for custom Snorkel keyword, operator, and code LFs. This enables you to enter straightforward prompts into the SDK functions and receive suggestions that accelerate data-centric development on Snorkel Flow even more.
Annotation enhancements
We’ve added a new sorting utility to the multi-label annotation interface that gives you more flexibility when trying to locate specific annotations. The new tool allows users to sort available classes by name, presence, or absence, providing greater ease and efficiency in reviewing and labeling high-cardinality use cases. This makes it easier to review and label high-cardinality use cases. The Snorkel R&D team spent the last few months making several performance improvements to multi-label annotation. In addition, you can now create custom batch names, as well as perform multi-line annotation in sequence tagging applications.
Enterprise and performance enhancements
We’re continually striving to improve Snorkel Flow to be a secure enterprise-grade solution that enterprises can trust and rely on.
With our new streamlined Snorkel Flow Kubernetes deployments with Replicated, you can get up and running faster than ever before. There are also significant improvements to the logging user experience. We spent a lot of time under the hood improving stability, and functional performance for features such as LF apply and dev set loading. And with support for Git CLI in notebooks, you’ll be able to share your work more easily via your own Git repositories!
Finally, our new credential management system for 3P integrations will help you manage your integrations with third-party tools more efficiently and securely.
Interested in learning more about Snorkel Flow? Schedule a demo with one of our Snorkel Flow experts.
