Foundation models have become the new baseline for tackling problems in enterprise AI development. Their power for understanding and generating text has made them the go-to first tool for data scientists and line of business leaders.
However, foundation models (FMs) rarely achieve the performance enterprises need for production deployment. In the case of document intelligence, FMs can struggle to understand the content due to complex layouts, varying formats, or the need for additional pre-processing (especially for scanned documents). To go from starting point to production-ready, data scientists must further develop their data. This is where the Snorkel Flow AI data development platform comes in.
Our latest release of Snorkel Flow, we introduced a prompting-first workflow for document intelligence. This workflow allows users to start with an FM baseline and then investigate where the FM performs well, and (more importantly) where it doesn’t. Users can then iteratively address the FM’s gaps until they build a production-grade model.
In addition to easing the transition from prompting to programmatic labeling, this release also takes advantage of Snorkel Flow’s existing document intelligence features, such as integrated document preprocessing.
Here’s a brief overview of how our FM-first document intelligence workflow works.
The case: extracting interest rate derivatives from pdfs
To explain the new prompting-first workflow, we’ll use a real case we did with a top 10 U.S. bank. The institution wanted to build a specialist model well-trained to extract interest rate derivatives from financial documents—specifically 10K financial statements published by publicly traded corporations.
These many-page documents include a wealth of insights into the companies’ holdings, which may or may not include interest rate derivatives. The model must sort through text and tables in various formats to separate references to interest rate swaps from all other holdings—which can look similar on cursory inspection.
It’s a daunting problem, and we will begin solving it with an FM in Snorkel Flow.
Understanding the document intelligence workflow
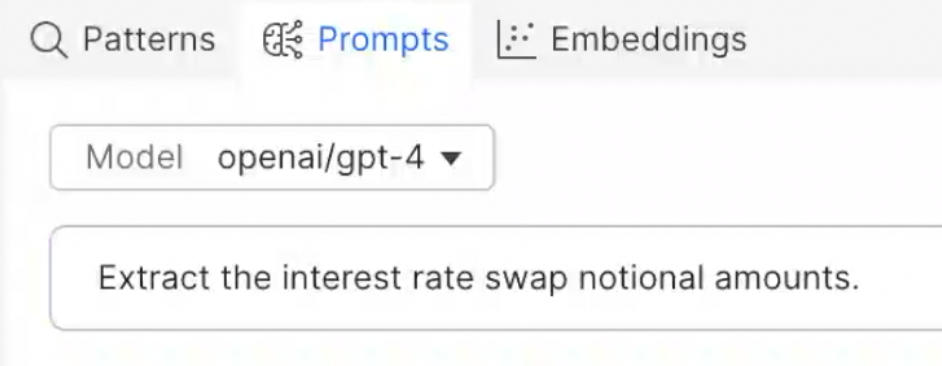
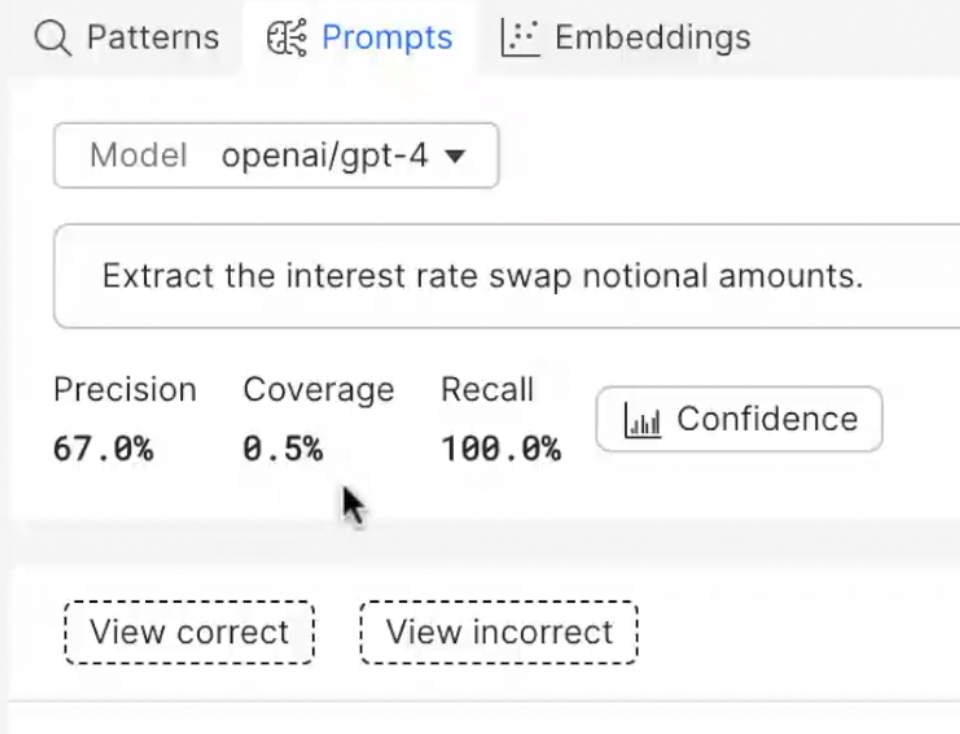
Snorkel Flow’s approach to document intelligence applications leverages the power of FMs— in this case large language models (LLMs), such as OpenAI’s GPT-4. Our demonstration began with a simple prompt: “Extract the interest rate swap notional amounts.”
In our walkthrough, Snorkel Flow evaluated the performance of this prompt, and found that it achieved a precision of 67% while covering about 0.5% of the data—statistics that the platform summarized and displayed clearly for us to understand.
By allowing users to input specific prompts or instructions, we empower them to automatically pre-label their data and see how off-the-shelf models perform on their particular problem. This eases the startup process and enables users to quickly assess and compare FM capabilities.
Data scientists could experiment with prompting outside of the Snorkel Flow ecosystem, but the platform demonstrates several major advantages:
- Snorkel Flow includes document pre-processing tools, including optical character recognition, that otherwise might have to be handled separately.
- The platform packages the output of each prompt into a programmatic labeling function that runs across the entire dataset.
- It combines signals from multiple labeling functions to apply a final label.
Before training our first model, we built two labeling functions on GPT-4 prompts: the one described above, and a second one that identified liabilities and debts—which we do not want the model to label as interest rate swaps. Together, these two labeling functions labeled 276 spans. The model trained on this training set achieved an F1-score of about 60 on our hand-labeled ground truth.
That’s a strong starting point, but not close to the bank’s production benchmark.
However, the true strength of Snorkel Flow lies in its ability to iteratively refine and improve our training data (and therefore the model).
Iteratively addressing FM errors
Snorkel Flow’s iterative training process starts with identifying error modes, which are areas where the model diverges from expectations.
In our demonstration, we used the platform’s Clarity Matrix to identify one specific gap. Our initial model, driven by our GPT-4 labeling functions, abstained from labeling ground truth points that appeared in tables. The table format confused GPT-4, but the text in the table clearly identified the attached figures as interest rate swaps.
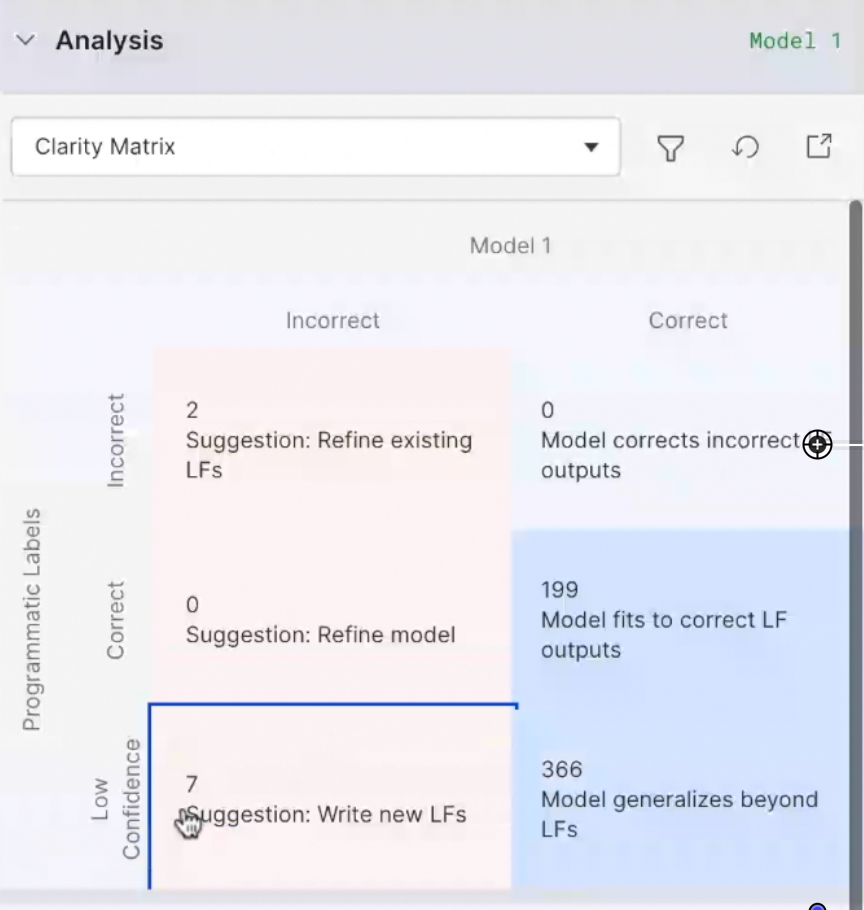
To address this, we built a simple regex labeling function that tagged spans according to a few strings: “interest rate swap,” interest rate derivatives,” and “fixed to variable.” This function more than doubled our quantity of labeled data. We then trained a new model, which saw a more than 20-point F1-score increase. Again, this is not production ready, but a big step in the right direction.
When our customers use Snorkel Flow, they follow this iterative process of identifying errors, correcting them, and retraining the model until the model’s performance reaches production grade. Once they hit their pre-determined benchmarks, they may bring in subject matter experts to sanity check the performance in case anything got lost in translation.
Then, the model goes off to production—ten to 100 times faster than it would have through manual labeling.
Document intelligence: now faster than ever in Snorkel Flow
Snorkel Flow’s prompting-first workflow offers a powerful tool for tackling complex document intelligence problems. By combining the power of large language models with programmatic labeling functions, users can quickly get started with a baseline that shows them where the LLMs do well and (more importantly) where they fall short.
The ability to identify and correct error modes ensures continuous improvement and refinement, bridging the gap between prototype and production deployment faster than ever before.
Learn more
If you'd like to learn how the Snorkel AI team can help you develop high-quality LLMs or deliver value to your organization from generative AI, contact us to get started. See what Snorkel can do to accelerate your data science and machine learning teams. Book a demo today.