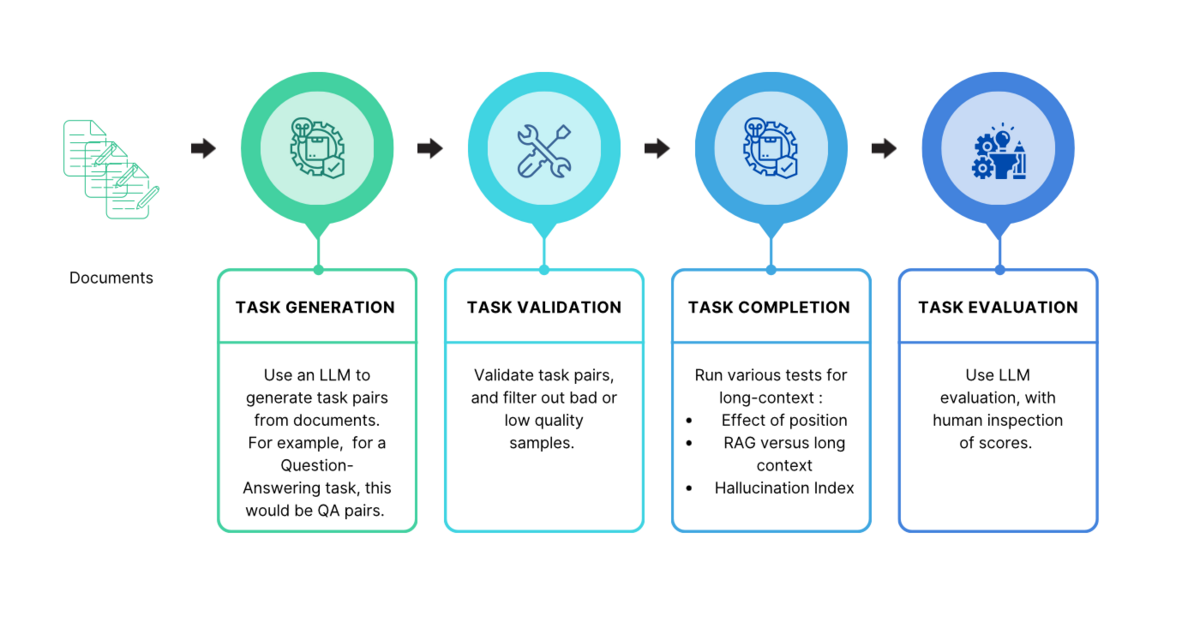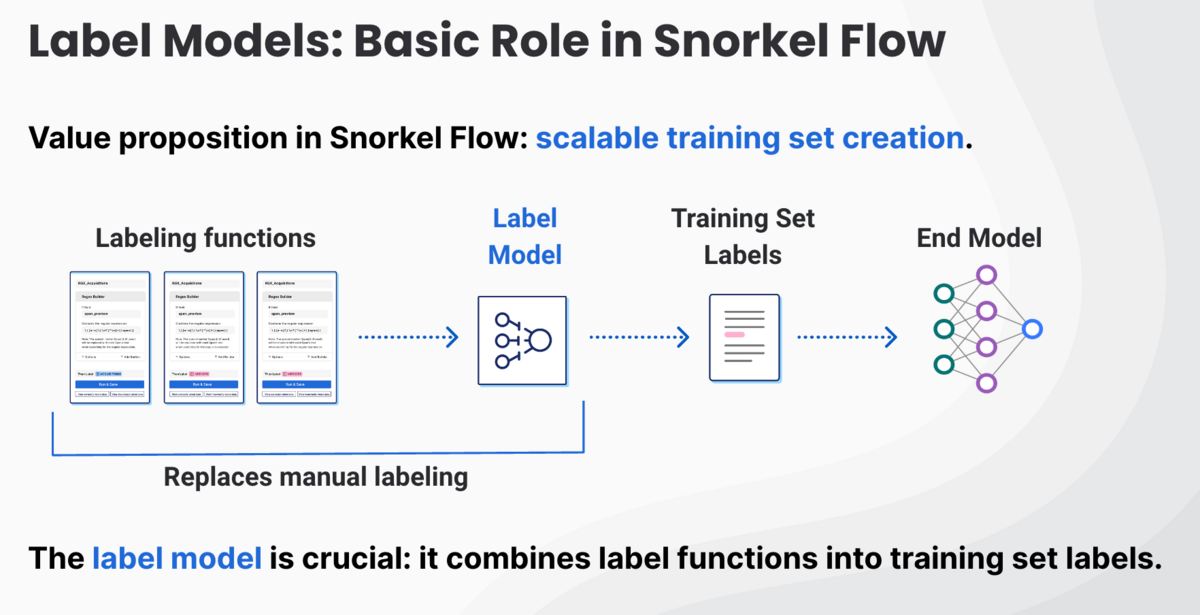
The Snorkel Flow label model plays an instrumental role in driving the enterprise value we create at Snorkel AI. It enables us to create high-accuracy machine learning training datasets quickly and iteratively based on expert knowledge, experience, and intuition.
Choosing how to craft our label model was no easy task. AI researchers continually introduce new models, each with their own strengths and limitations. In my tenure as a machine learning researcher, I’ve observed that label models generally fall into two categories: those that prioritize speed and efficiency, and those that incorporate sophisticated features to tackle specific issues.
None seemed to fit Snorkel’s needs. So, we built our own.
What is a label model?
Label models reconcile the input of labeling functions into the final labels we attach to training data.
We’ve explained labeling functions in greater detail elsewhere, but here’s a brief primer: labeling functions translate expert input into scalable and repeatable rules. They could be as simple as a substring search or as sophisticated as a deeply-instructed call to a large language model (LLM).
Each labeling function either votes or abstains on each document. The label model sorts through the votes and abstentions to apply the final label. The ways label models evaluate these signals range from incredibly simple to highly complex.
Majority vote label models
To resolve labeling function votes, we can simply take the majority vote. The majority vote model, however, operates on a few critical assumptions that I often see violated in practice. The first is that all LFs are of equal weight and quality. It doesn’t distinguish between a highly accurate LF and a mediocre one. It treats all votes equally—which can lead to skewed results if one or more LFs are inherently biased or inaccurate.
The second assumption is that classes with more LFs and LF “coverage” (the number of samples voted on by the LF) dedicated to them are more frequent. If a user happens to write many high-coverage LFs for one class and only one low coverage LF for a second class, the Majority Vote model implicitly assumes the first class is more frequent. The Majority Vote model, by design, can’t recognize whether a class is rare or not. In real-world applications, this often leads to over-voting for rare classes because users can actually devote a lot of time to writing LFs for rare classes.
A third assumption is that LFs make errors independently of each other. If one LF makes a mistake and incorrectly votes on a class, the chance that another LF will mistakenly vote on that same class is the same as it was before. This is a more subtle assumption that is also often incorrect in practice, and one of the most difficult problems for label models to solve.
One final shortcoming of majority voting is that it cannot learn from ground truth. Often customer datasets contain enough ground that a small sample could in theory be leveraged to improve the accuracy of our weak supervision process.
“Graphical” label models
On the other end of the label model spectrum, we have what I refer to as “graphical” label models. These are much more sophisticated statistical models that use machine learning to infer ground truth from LF voting patterns. They are oriented at addressing the shortcomings of majority voting and have been proven out on open-source datasets with relatively straightforward machine learning tasks such as binary classification. The theory behind these models is well established, with a number of high-profile publications from labs that include the group that founded Snorkel AI.
There are two main drawbacks to graphical models, however. One is that due to their complexity, graphical label models can demand significant computational resources and processing time. They may take hours to run, especially on tasks with many classes or more complex target variables, which is rarely feasible in a fast-paced enterprise environment. The second is that they are not always as accurate on real-world datasets due to statistical assumptions they make.

Our proprietary Snorkel Flow label model
To find a happy medium between quick-running Majority Vote models and heavier graphical models, I developed our proprietary Snorkel Flow label model. It is a direct response to the needs and feedback of our customers, who need a robust and practical solution for real-world applications. While I can’t describe our Snorkel Flow label model formula in full detail (it is proprietary, after all), I can offer some high-level insights.
The model leverages ground truth data where it exists and learns from the patterns in the labeling functions. Labeling functions that apply to fewer examples and score higher precision on our ground truth data, for example, get a stronger vote. It also adjusts the weight of labeling functions based on the class distribution in the ground truth.
As a result, it addresses the two most common shortcomings of majority voting described above, assigning equal weight to all LFs and over-weighting classes with more LFs devoted to them. It does not address the third independence-of-errors assumption, which was a conscious choice; it seems to have less impact on accuracy in practice than the first two assumptions, and solving it would require much more sophisticated, computationally expensive models. [cite Fred’s flyingsquid model].
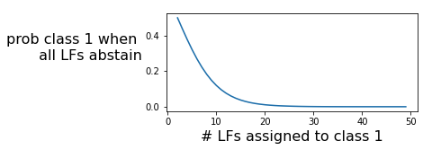
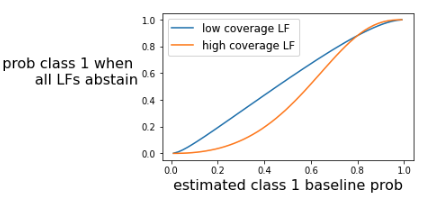
Comparing the Snorkel Flow label model to others
We tested our Snorkel Flow label model and several other options on an internal collection of 10+ datasets with varying properties and fixed labeling functions. The Snorkel Flow label model offered a significant lift in terms of performance, speed, and memory efficiency, which you can see in the table below.
| Fit time diff from Majority Vote | Fit peak memory diff from Majority Vote | Accuracy difference from Majority Vote | |
| Snorkel Flow | 0.07 sec | 27 MB | +1.2% (Up to 4.5%) |
| Open Source Snorkel | 20 sec | 1300 MB | -0.1% |
| Skweak | 31 sec | 5000 MB | -0.5% |
On average, it provides a 1- to 2-point increase in accuracy over majority vote and wins out in 80% of experiments. Importantly, the Snorkel Flow label model is an order of magnitude faster and uses less memory than the academic alternatives.
Those differences sound small, but they add up. Due to our model’s small footprint and high processing speed, our customers can iterate quickly—spotting places where their existing labeling functions need additional help, adding it, and getting to a production-grade application faster.
The Snorkel Flow label model: a platform cornerstone
Label models are central to creating efficient and effective training sets for machine learning models. While the field of AI is not short of label models, our proprietary Snorkel Flow label mode provides a significant lift in performance, speed, and memory efficiency.
It’s a testament to our commitment to continually improve and adapt our tools to meet the real needs of our customers. The development of a label model is a constant work in progress (I’ve updated it twice), and we look forward to the exciting prospects it holds for the future.
Learn More
Follow Snorkel AI on LinkedIn, Twitter, and YouTube to be the first to see new posts and videos!